Clear Sky Science · it
Un framework di privacy differenziale adattivo per LLM clinici con calibrazione del rumore contestuale, bilancio gerarchico e audit in tempo reale
Perché un’IA medica più sicura è importante
Gli ospedali si rivolgono all’intelligenza artificiale per aiutare i medici a redigere note e riassumere cartelle cliniche estese, ma ogni riga di testo può rivelare aspetti profondamente personali di un paziente. Questo articolo presenta PrivLLM-Guard, un metodo per eseguire grandi modelli di linguaggio su testi clinici in modo che restino utili per l’assistenza riducendo drasticamente la probabilità che dettagli privati trapelino attraverso le risposte del modello.
Privacy più intelligente per i testi clinici
I moderni modelli linguistici sono molto bravi a leggere e scrivere note mediche, ma possono anche memorizzare e ripetere frammenti dei dati di addestramento. In ambito sanitario questo rischio è inaccettabile perché leggi e etica richiedono una protezione forte delle identità, delle diagnosi e delle storie cliniche. Molti strumenti di privacy esistenti aggiungono semplicemente lo stesso livello di rumore casuale ovunque nel modello, il che spesso rovina la qualità dell’output o rallenta il sistema così tanto da renderlo inutilizzabile al letto del paziente. Gli autori sostengono che l’IA clinica necessita di un approccio più su misura che tratti diversi tipi di informazioni mediche con diversi livelli di attenzione.
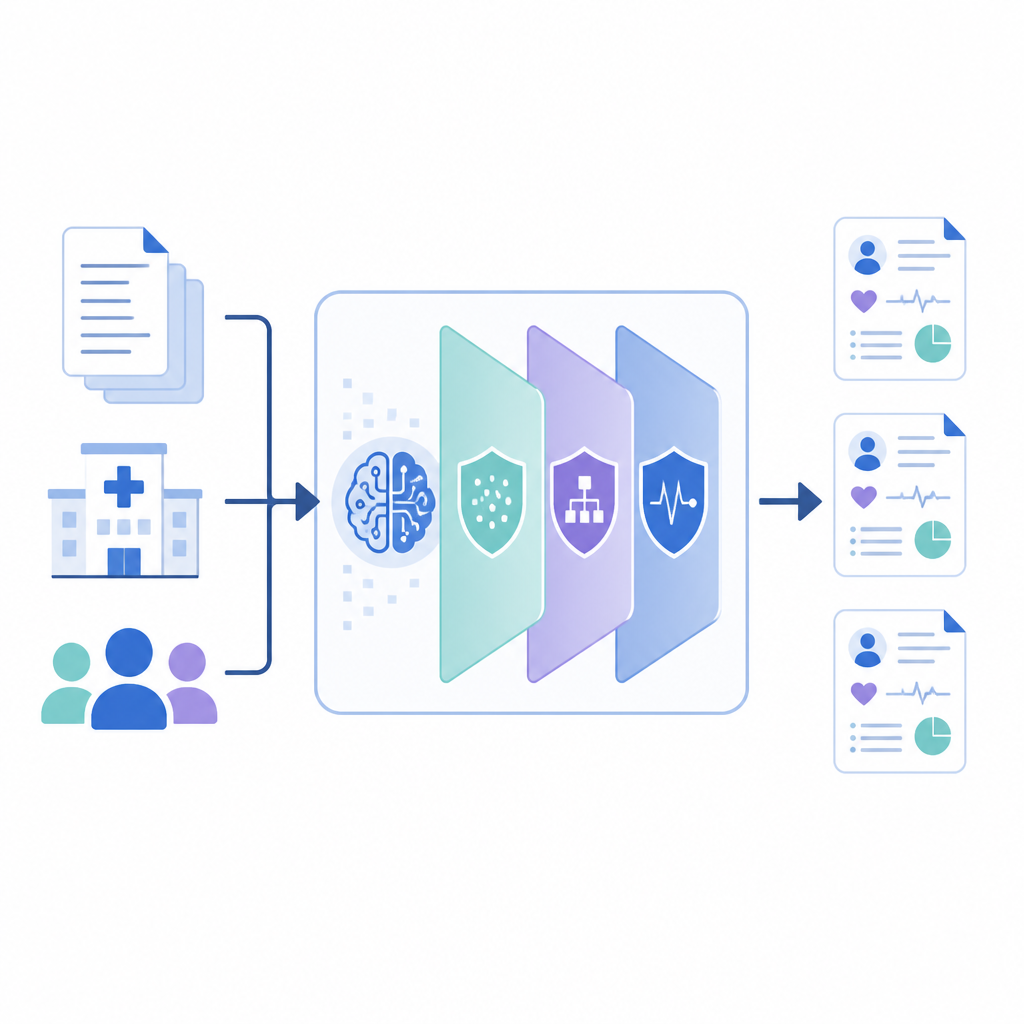
Come funziona il nuovo framework
PrivLLM-Guard incapsula un potente modello di linguaggio all’interno di diversi strati di privacy cooperativi. In ingresso, un encoder attento alla privacy altera leggermente la rappresentazione interna di ogni input, così che la formulazione di un singolo paziente non possa essere tracciata. In uscita, un decoder progettato ad hoc controlla come viene generato il nuovo testo, usando scelte randomizzate che limitano quanto possa riecheggiare fedelmente un singolo record. Tra questi estremi, il sistema monitora quanto “budget di privacy” è stato speso, come un contatore, e distribuisce quel budget tra i componenti in modo che gli elementi più sensibili, come nomi o date, ricevano una protezione più forte rispetto a fatti medici generali come nomi di farmaci comuni.
Adattarsi al rischio in tempo reale
Un’innovazione chiave è che PrivLLM-Guard non tratta tutte le richieste allo stesso modo. Un modulo di rumore adattivo analizza il testo in arrivo per giudicare quanto sia privato: per esempio, se si tratta di un riepilogo di routine o di una condizione rara che potrebbe identificare una singola persona. In base a quella valutazione e al comportamento passato, il sistema aggiusta quanta variazione casuale inserire nei segnali interni del modello. Allo stesso tempo, un monitor della privacy in tempo reale osserva ogni token prodotto dal modello, stimando la probabilità che riveli qualcosa di sensibile. Se quel rischio supera una soglia preimpostata, il sistema reagisce istantaneamente aumentando la protezione o addirittura interrompendo la risposta, invece di attendere una revisione umana a posteriori.
Mantenere equilibrio tra accuratezza e velocità
Proteggere la privacy ha senso solo se le note risultanti continuano ad essere utili per i clinici. Gli autori hanno testato PrivLLM-Guard su milioni di record de-identificati provenienti da terapia intensiva, assistenza ospedaliera generale e dataset di sfida. Con impostazioni di privacy molto rigorose, il framework ha prodotto riepiloghi e report più vicini ai testi di riferimento rispetto a diversi modelli concorrenti che preservano la privacy, mantenendo al tempo stesso termini e relazioni mediche importanti intatti. I medici che hanno valutato gli output in specialità come oncologia, cardiologia, medicina d’urgenza e radiologia hanno giudicato i testi clinicamente accurati e leggibili. Il sistema è rimasto anche sufficientemente veloce per l’uso in tempo reale, gestendo lunghezze tipiche delle note in una frazione di secondo con esigenze di memoria moderate.
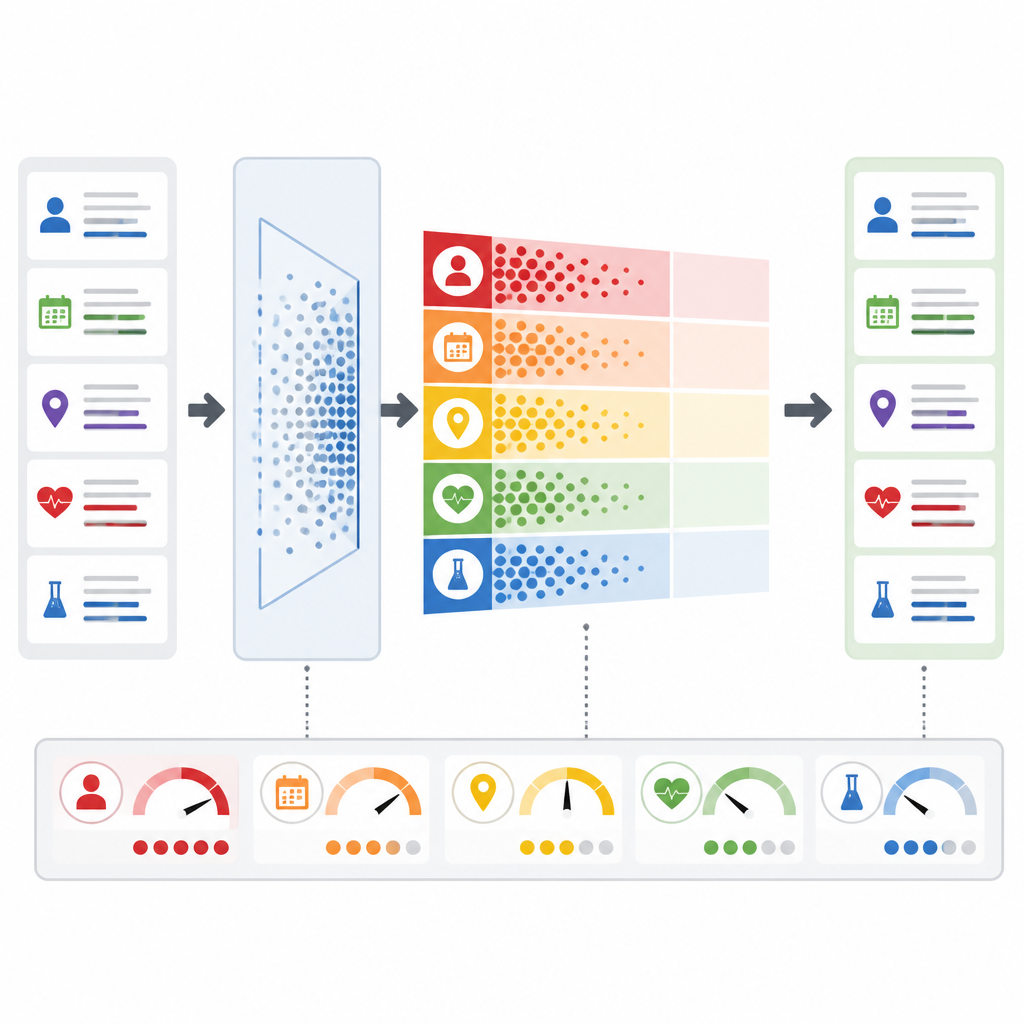
Cosa significa per pazienti e clinici
In termini semplici, PrivLLM-Guard dimostra che gli ospedali possono usare potenti modelli di linguaggio per ridurre la burocrazia e chiarire cartelle complesse senza affidarsi passivamente alla sola buona sorte della privacy. Misurando il rischio in modo continuo, adattando la protezione al tipo di informazione e fornendo garanzie di privacy dimostrabili matematicamente, il framework offre una via verso strumenti di IA clinica che rispettano sia la qualità medica sia la riservatezza dei pazienti. Pur rimanendo sfide per malattie rare, altre lingue e tipi di dati misti come le immagini, questo lavoro suggerisce che assistenti testuali più sicuri e trasparenti in ambito sanitario sono alla portata.
Citazione: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Parole chiave: modelli di linguaggio clinici, privacy dei dati medici, privacy differenziale, riepilogo di testi sanitari, IA clinica in tempo reale