Clear Sky Science · ru
Адаптивная схема дифференциальной приватности для клинических LLM с контекстно-зависимой калибровкой шума, иерархическим бюджетированием и аудитом в реальном времени
Почему безопасный медицинский ИИ важен
Больницы всё активнее используют искусственный интеллект, чтобы помогать врачам составлять заметки и суммировать длинные медицинские истории, но каждая строка текста может раскрыть нечто глубоко личное о пациенте. В этой статье представлена система PrivLLM-Guard — метод запуска крупных языковых моделей на клинических текстах, который сохраняет их полезность для оказания помощи и одновременно значительно снижает вероятность утечки приватных деталей через ответы модели.
Более интеллектуальная приватность для клинических текстов
Современные языковые модели отлично читают и генерируют медицинские заметки, однако они также могут запоминать и воспроизводить фрагменты обучающей выборки. В здравоохранении этот риск неприемлем: законы о конфиденциальности и этические нормы требуют надёжной защиты идентичности, диагнозов и истории болезни. Многие существующие инструменты приватности просто добавляют одинаковый уровень случайного шума везде в модели, что часто ухудшает качество вывода или замедляет систему настолько, что её нельзя использовать у постели больного. Авторы утверждают, что клиническому ИИ нужна более дифференцированная стратегия, которая по‑разному относится к разным типам медицинской информации.
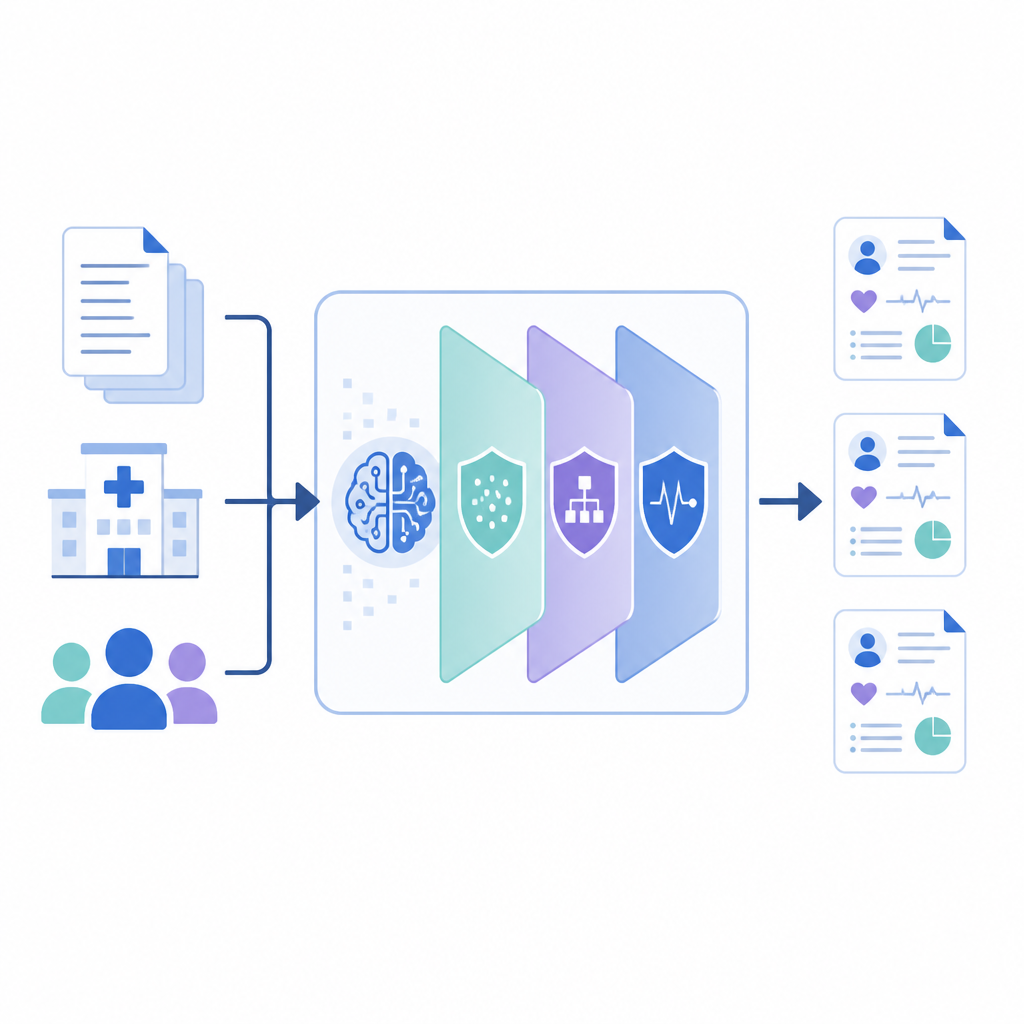
Как работает новая схема
PrivLLM-Guard окружает мощную языковую модель несколькими координируемыми слоями приватности. На входе приватносознанный кодировщик слегка искажает внутреннее представление каждого входа, чтобы формулировка отдельного пациента не была отслеживаема. На выходе специально разработанный декодер контролирует генерацию нового текста, используя рандомизированные решения, которые ограничивают то, насколько близко модель может повторять какую‑то одну запись. Между ними система отслеживает, сколько «бюджета приватности» уже израсходовано, подобно счётчику, и распределяет этот бюджет по компонентам так, чтобы наиболее чувствительные элементы — например, имена или даты — получали более сильную защиту, чем общие медицинские факты, такие как названия распространённых препаратов.
Адаптация к риску в реальном времени
Ключевая новация в том, что PrivLLM-Guard не рассматривает все запросы одинаково. Модуль адаптивного шума анализирует входной текст, чтобы оценить степень его приватности: например, является ли это рутинной сводкой или редким заболеванием, которое может идентифицировать одного человека. На основе этой оценки и прошлой активности система регулирует, сколько случайной вариации добавлять во внутренние сигналы модели. Одновременно монитор приватности в реальном времени отслеживает каждый токен, который модель выдаёт, оценивая вероятность раскрытия чего‑то чувствительного. Если риск превышает заранее заданный порог, система мгновенно усиливает защиту или даже прекращает ответ, вместо того чтобы ждать послеточного ручного обзора.
Баланс точности и скорости
Защита приватности полезна только если итоговые заметки по‑прежнему помогают клиницистам. Авторы протестировали PrivLLM-Guard на миллионах де‑идентифицированных записей из отделений интенсивной терапии, общей больничной помощи и контрольных наборов. При очень жёстких настройках приватности схема генерировала сводки и отчёты, которые были ближе к эталонным текстам, чем у нескольких конкурирующих моделей с защитой приватности, при этом сохраняя важные медицинские термины и взаимосвязи. Врачи, оценившие выводы в таких специализациях, как онкология, кардиология, неотложная медицина и радиология, признали тексты клинически точными и читабельными. Система также оставалась достаточно быстрой для использования в реальном времени, обрабатывая типичные длины заметок за доли секунды при умеренных требованиях к памяти.
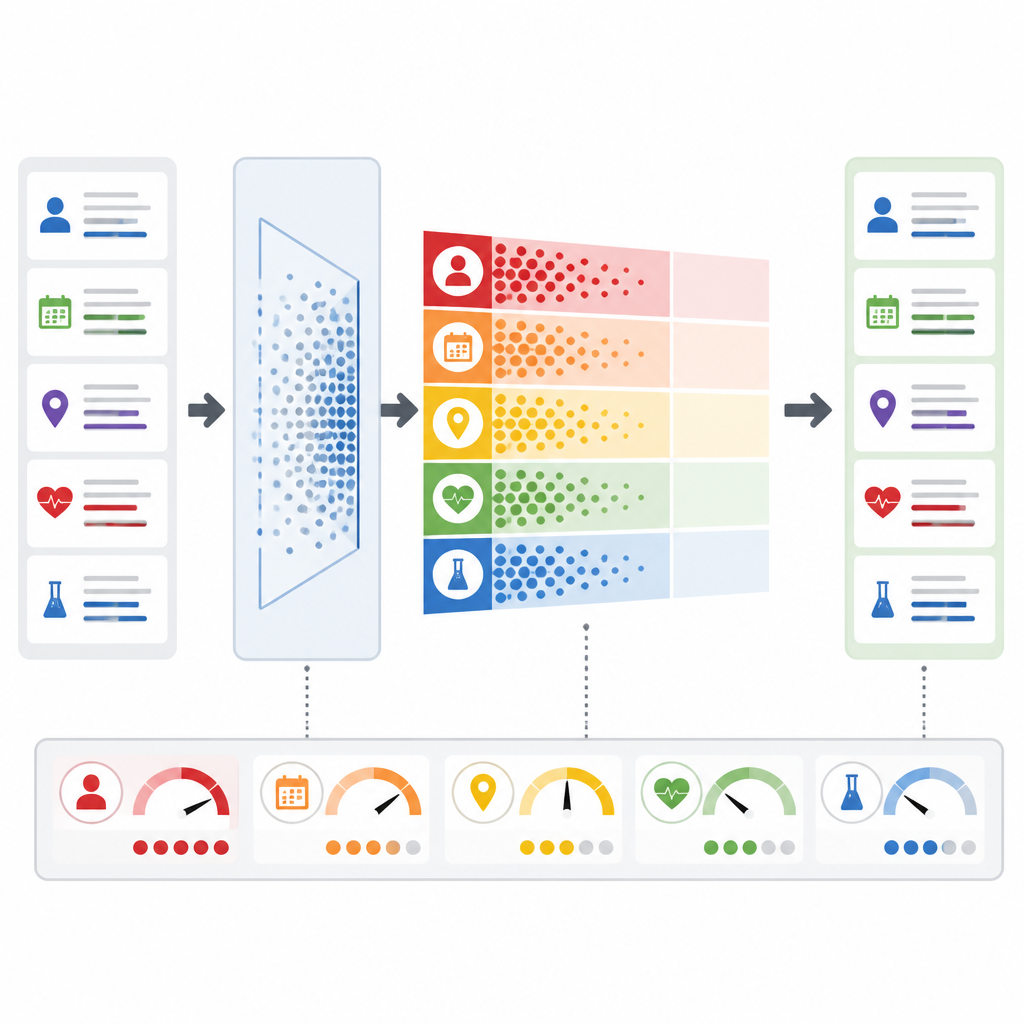
Что это означает для пациентов и клиницистов
Проще говоря, PrivLLM-Guard показывает, что больницы могут использовать мощные языковые модели, чтобы сократить бумажную работу и прояснять сложные записи, не полагаясь на то, что приватность сохранится сама по себе. Непрерывно измеряя риск, адаптируя защиту к типу информации и предоставляя математические гарантии приватности, эта схема предлагает путь к клиническим инструментам ИИ, которые уважают и медицинское качество, и конфиденциальность пациентов. Хотя остаются задачи для редких заболеваний, других языков и смешанных типов данных, таких как изображения, работа показывает: более безопасные и прозрачные текстовые ассистенты в здравоохранении вполне достижимы.
Цитирование: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Ключевые слова: клинические языковые модели, конфиденциальность медицинских данных, дифференциальная приватность, суммирование медицинских текстов, клинический ИИ в реальном времени