Clear Sky Science · nl
Een adaptief kader voor differentiële privacy voor klinische LLM's met contextbewuste ruiskalibratie, hiërarchische budgettering en realtime auditing
Waarom veiligere medische AI ertoe doet
Ziekenhuizen zetten kunstmatige intelligentie in om artsen te helpen bij het opstellen van aantekeningen en het samenvatten van lange medische dossiers, maar elke regel tekst kan iets persoonlijks over een patiënt prijsgeven. Dit artikel introduceert PrivLLM-Guard, een methode om grote taalmodellen op klinische tekst te laten draaien zodat ze nuttig blijven voor de zorg terwijl de kans dat privégegevens via de antwoorden van het model lekken sterk wordt verkleind.
Slimmere privacy voor klinische tekst
Moderne taalmodellen zijn uitstekend in het lezen en schrijven van medische aantekeningen, maar ze kunnen ook fragmenten van hun trainingsdata memoriseren en herhalen. In de gezondheidszorg is dat risico onaanvaardbaar omdat privacywetten en ethiek sterke bescherming eisen voor iemands identiteit, diagnoses en medische geschiedenis. Veel bestaande privacytools voegen overal hetzelfde niveau van willekeurige ruis toe aan een model, wat vaak de kwaliteit van de output ruïneert of het systeem zo vertraagt dat het niet aan het bed gebruikt kan worden. De auteurs betogen dat klinische AI een meer op maat gemaakte aanpak nodig heeft die verschillende soorten medische informatie met verschillende zorgniveaus behandelt.
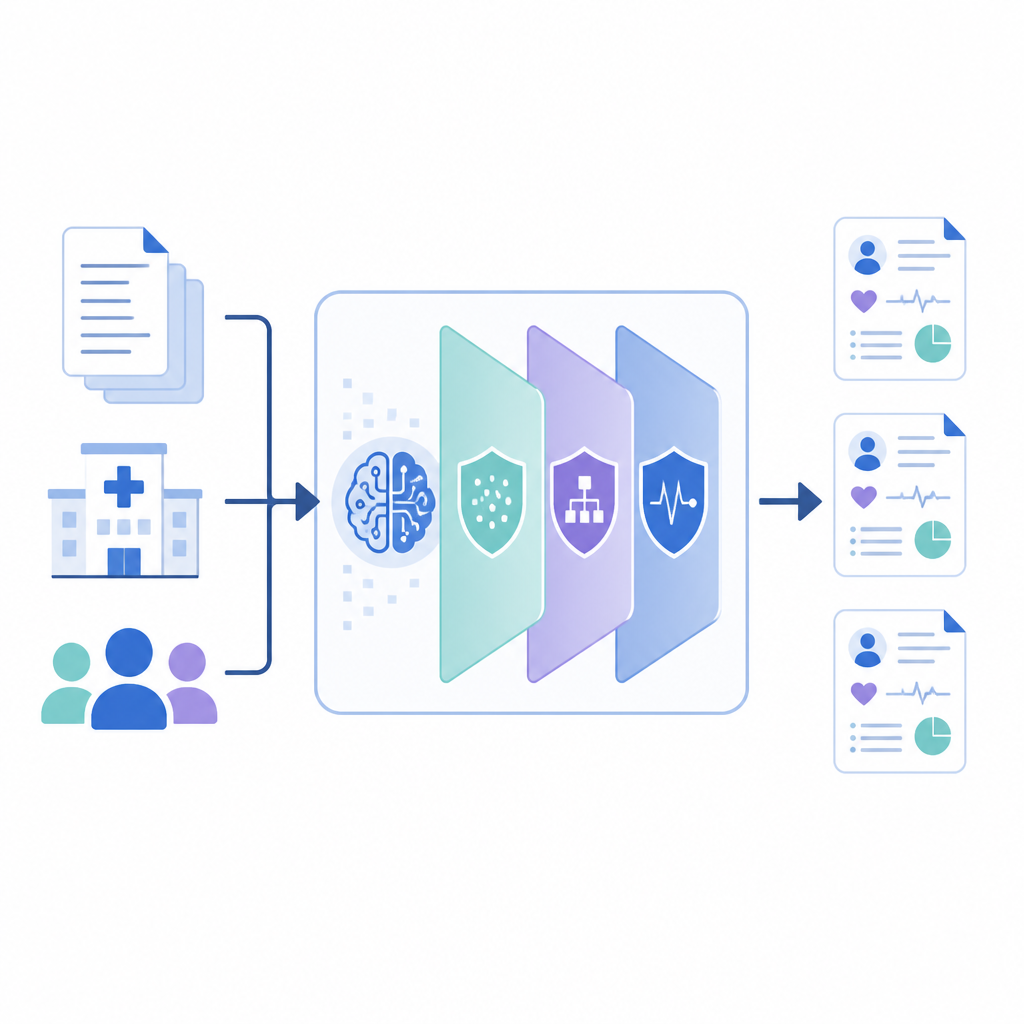
Hoe het nieuwe raamwerk werkt
PrivLLM-Guard wikkelt een krachtig taalmodel in meerdere samenwerkende privacylagen. Bij binnenkomst verstoort een privacybewuste encoder licht de interne representatie van elke invoer, zodat de bewoording van één enkele patiënt niet kan worden teruggevoerd. Bij de uitgang regelt een speciaal ontworpen decoder hoe nieuwe tekst wordt gegenereerd, met gerandomiseerde keuzes die beperken hoe nauwkeurig het model een enkel dossier kan echoën. Tussen deze uiteinden houdt het systeem bij hoeveel "privacybudget" er is verbruikt, vergelijkbaar met een meter, en verdeelt dat budget over componenten zodat de meest gevoelige items, zoals namen of datums, sterker worden afgeschermd dan algemene medische feiten zoals veelvoorkomende medicijnnamen.
Adaptatie aan risico's in realtime
Een belangrijke innovatie is dat PrivLLM-Guard niet elk verzoek hetzelfde behandelt. Een adaptieve ruismodule analyseert de binnenkomende tekst om te beoordelen hoe privé deze is: bijvoorbeeld of het een routinematige samenvatting is of een zeldzame aandoening die één persoon kan identificeren. Op basis van die beoordeling en van eerder gedrag past het systeem aan hoeveel willekeurige variatie het toevoegt aan de interne signalen van het model. Tegelijkertijd houdt een realtime privacymonitor elk token dat het model produceert in de gaten en schat hij de kans in dat het iets gevoeligs onthult. Als dat risico boven een vooraf ingestelde drempel uitkomt, reageert het systeem direct door de bescherming te versterken of zelfs de respons te stoppen, in plaats van te wachten op een achterafvolgende menselijke beoordeling.
Nauwkeurigheid en snelheid in balans houden
Privacy beschermen is alleen nuttig als de resulterende aantekeningen nog steeds hulp bieden aan zorgverleners. De auteurs hebben PrivLLM-Guard getest op miljoenen geanonimiseerde dossiers uit de intensivecare, algemene ziekenhuiszorg en uitdagingdatasets. Onder zeer strikte privacyinstellingen leverde het raamwerk samenvattingen en gegenereerde rapporten die dichter bij referentieteksten lagen dan meerdere concurrerende privacybehoudende modellen, terwijl belangrijke medische termen en relaties intact bleven. Artsen die de outputs beoordeelden in specialismen zoals oncologie, cardiologie, spoedeisende hulp en radiologie waardeerden de tekst als zowel klinisch accuraat als goed leesbaar. Het systeem bleef ook snel genoeg voor realtime gebruik en verwerkte typische notitielengtes in een fractie van een seconde met gematigde geheugenvraag.
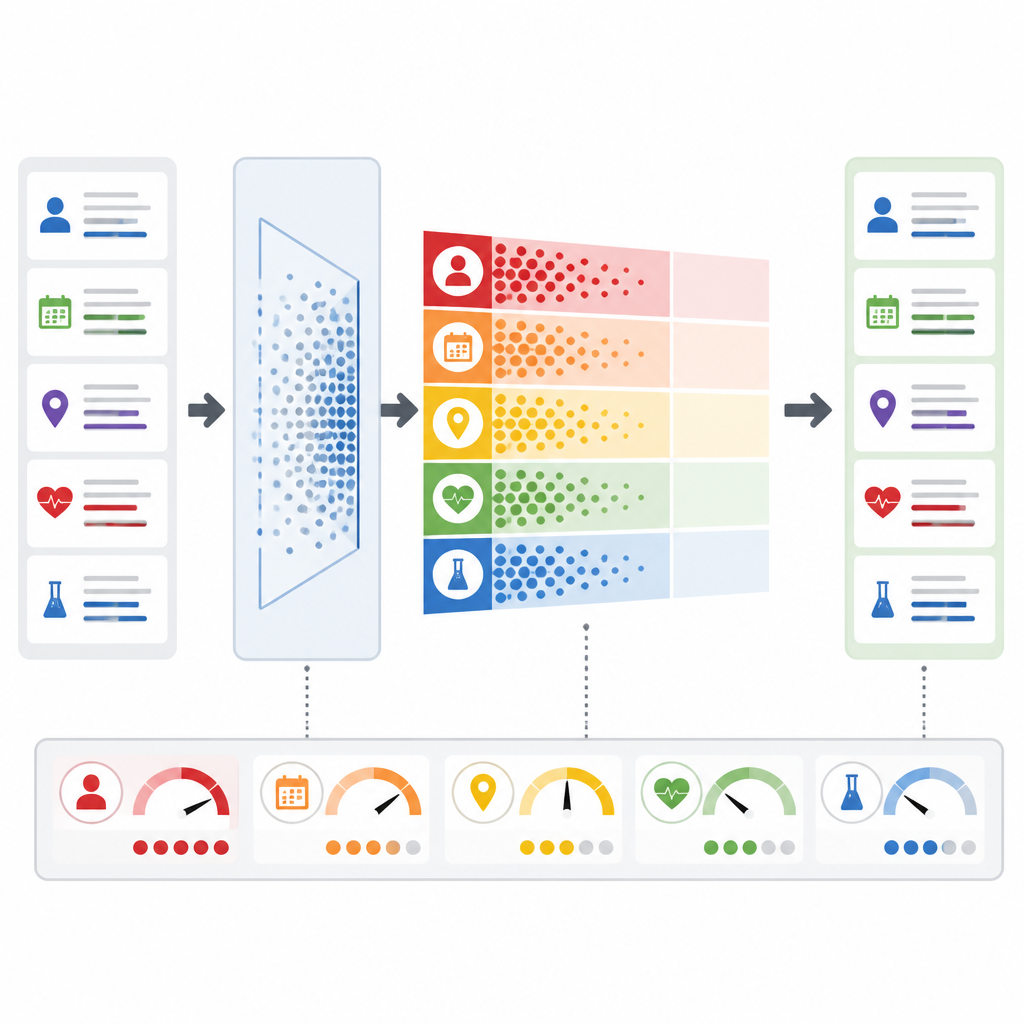
Wat dit betekent voor patiënten en zorgverleners
Kort gezegd laat PrivLLM-Guard zien dat ziekenhuizen krachtige taalmodellen kunnen gebruiken om administratieve lasten te verminderen en complexe dossiers te verduidelijken zonder blind te vertrouwen dat privacy vanzelf wordt gewaarborgd. Door continu risico te meten, bescherming af te stemmen op het type informatie en privacygaranties wiskundig te onderbouwen, biedt het raamwerk een route naar klinische AI-instrumenten die zowel medische kwaliteit als patiëntvertrouwelijkheid respecteren. Hoewel er nog uitdagingen zijn voor zeldzame ziekten, andere talen en gemengde datatypes zoals beelden, suggereert dit werk dat veiliger, transparantere tekstgebaseerde assistenten in de gezondheidszorg binnen bereik liggen.
Bronvermelding: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Trefwoorden: klinische taalmodellen, privacy van medische gegevens, differentiële privacy, samenvatting van zorgteksten, realtime klinische AI