Clear Sky Science · pt
Um quadro adaptativo de privacidade diferencial para LLMs clínicos com calibração de ruído sensível ao contexto, orçamento hierárquico e auditoria em tempo real
Por que uma IA médica mais segura importa
Hospitais estão recorrendo à inteligência artificial para ajudar médicos a rascunhar notas e resumir longos prontuários, mas cada linha de texto pode revelar algo profundamente pessoal sobre um paciente. Este artigo introduz o PrivLLM-Guard, um método para executar grandes modelos de linguagem em textos clínicos de modo que permaneçam úteis para o cuidado, ao mesmo tempo em que reduz drasticamente a probabilidade de que detalhes privados vazem pelas respostas do modelo.
Privacidade mais inteligente para textos clínicos
Modelos de linguagem modernos são muito bons em ler e escrever anotações médicas, mas também podem memorizar e repetir fragmentos de seus dados de treinamento. Na saúde, esse risco é inaceitável porque leis de privacidade e a ética exigem proteção forte às identidades, diagnósticos e históricos das pessoas. Muitas ferramentas de privacidade existentes simplesmente adicionam o mesmo nível de ruído aleatório por toda parte em um modelo, o que frequentemente arruina a qualidade do resultado ou desacelera o sistema a ponto de torná-lo impraticável à beira do leito. Os autores defendem que a IA clínica precisa de uma abordagem mais personalizada que trate diferentes tipos de informação médica com níveis distintos de cuidado.
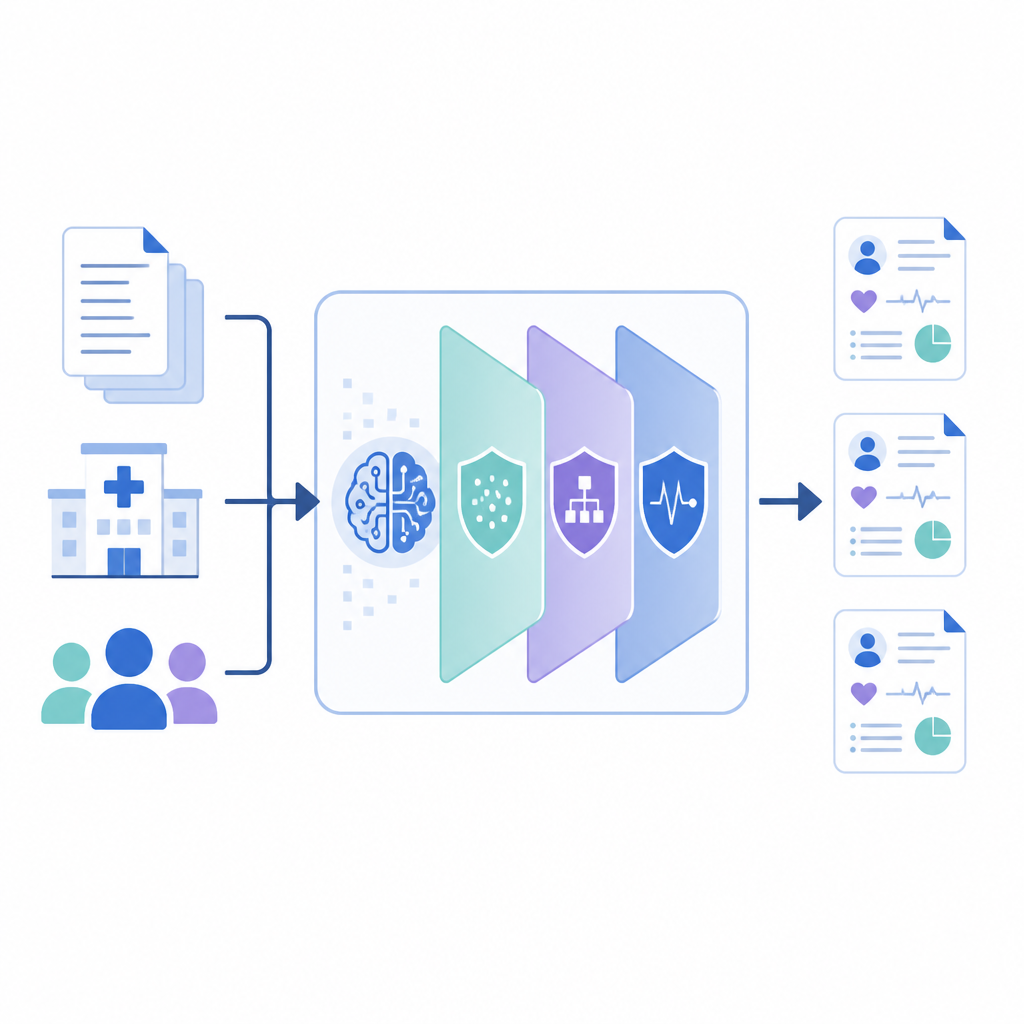
Como o novo quadro funciona
O PrivLLM-Guard envolve um poderoso modelo de linguagem em várias camadas de privacidade que cooperam. Na entrada, um codificador sensível à privacidade perturba ligeiramente a representação interna de cada entrada, para que a redação de um único paciente não possa ser rastreada. Na saída, um decodificador especialmente projetado controla como o texto novo é gerado, usando escolhas aleatórias que limitam o quanto ele pode reproduzir fielmente qualquer registro. Entre esses extremos, o sistema monitora quanto do “orçamento de privacidade” foi gasto, como um medidor, e distribui esse orçamento entre componentes de forma que itens mais sensíveis, como nomes ou datas, recebam proteção mais forte do que fatos médicos gerais, como nomes comuns de medicamentos.
Adaptando-se ao risco em tempo real
Uma inovação chave é que o PrivLLM-Guard não trata todas as solicitações da mesma forma. Um módulo de ruído adaptativo analisa o texto de entrada para julgar quão privado ele é: por exemplo, se é um resumo rotineiro ou uma condição rara que poderia identificar uma única pessoa. Com base nessa avaliação e no comportamento passado, o sistema ajusta quanto de variação aleatória adiciona aos sinais internos do modelo. Ao mesmo tempo, um monitor de privacidade em tempo real observa cada token produzido pelo modelo, estimando a chance de que ele revele algo sensível. Se esse risco ultrapassar um limiar predefinido, o sistema reage instantaneamente reforçando a proteção ou até interrompendo a resposta, em vez de aguardar uma revisão humana posterior.
Equilibrando precisão e velocidade
Proteger a privacidade só é útil se as notas resultantes ainda ajudarem os clínicos. Os autores testaram o PrivLLM-Guard em milhões de registros desidentificados de unidades de terapia intensiva, cuidados hospitalares gerais e conjuntos de dados de desafio. Sob configurações de privacidade muito rígidas, o quadro produziu resumos e relatórios que ficaram mais próximos dos textos de referência do que vários modelos concorrentes com preservação de privacidade, mantendo termos médicos e relações importantes intactos. Médicos que revisaram as saídas em especialidades como oncologia, cardiologia, medicina de emergência e radiologia classificaram o texto como clinicamente preciso e legível. O sistema também permaneceu rápido o suficiente para uso em tempo real, lidando com comprimentos típicos de notas em frações de segundo com necessidades moderadas de memória.
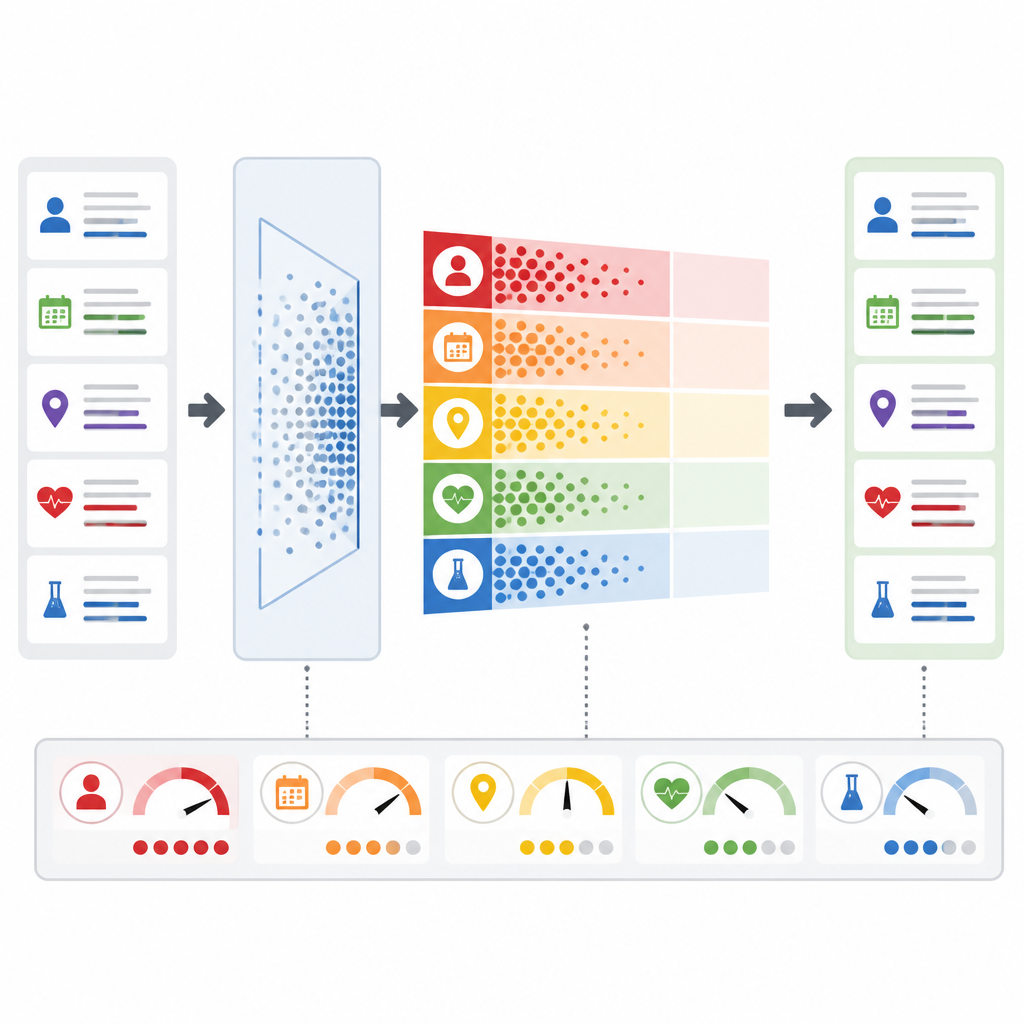
O que isso significa para pacientes e clínicos
Em termos simples, o PrivLLM-Guard demonstra que hospitais podem usar modelos de linguagem poderosos para reduzir a papelada e esclarecer prontuários complexos sem simplesmente confiar que a privacidade se cuidará sozinha. Ao medir o risco continuamente, adaptar a proteção ao tipo de informação e provar garantias de privacidade matematicamente, o quadro oferece um caminho rumo a ferramentas de IA clínica que respeitam tanto a qualidade médica quanto a confidencialidade do paciente. Embora desafios permaneçam para doenças raras, outras línguas e tipos de dados mistos como imagens, este trabalho sugere que assistentes textuais mais seguros e transparentes na saúde estão ao alcance.
Citação: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Palavras-chave: modelos de linguagem clínicos, privacidade de dados médicos, privacidade diferencial, resumode textos em saúde, IA clínica em tempo real