Clear Sky Science · es
Un marco de privacidad diferencial adaptativo para LLM clínicos con calibración de ruido consciente del contexto, presupuestación jerárquica y auditoría en tiempo real
Por qué importa una IA médica más segura
Los hospitales recurren a la inteligencia artificial para ayudar a los médicos a redactar notas y resumir largos historiales médicos, pero cada línea de texto puede revelar algo muy personal sobre un paciente. Este artículo presenta PrivLLM-Guard, un método para ejecutar grandes modelos de lenguaje sobre texto clínico de modo que sigan siendo útiles para la atención y, al mismo tiempo, reduzcan drásticamente la probabilidad de que detalles privados se filtren a través de las respuestas del modelo.
Privacidad más inteligente para texto clínico
Los modelos de lenguaje modernos son muy buenos leyendo y escribiendo notas médicas, pero también pueden memorizar y repetir fragmentos de sus datos de entrenamiento. En el ámbito sanitario, ese riesgo es inaceptable porque las leyes y la ética exigen una fuerte protección de las identidades, diagnósticos e historiales de las personas. Muchas herramientas de privacidad existentes simplemente añaden el mismo nivel de ruido aleatorio por todas partes en un modelo, lo que a menudo arruina la calidad de la salida o ralentiza el sistema tanto que no puede usarse junto a la cama del paciente. Los autores sostienen que la IA clínica necesita un enfoque más personalizado que trate distintos tipos de información médica con diferentes niveles de cuidado.
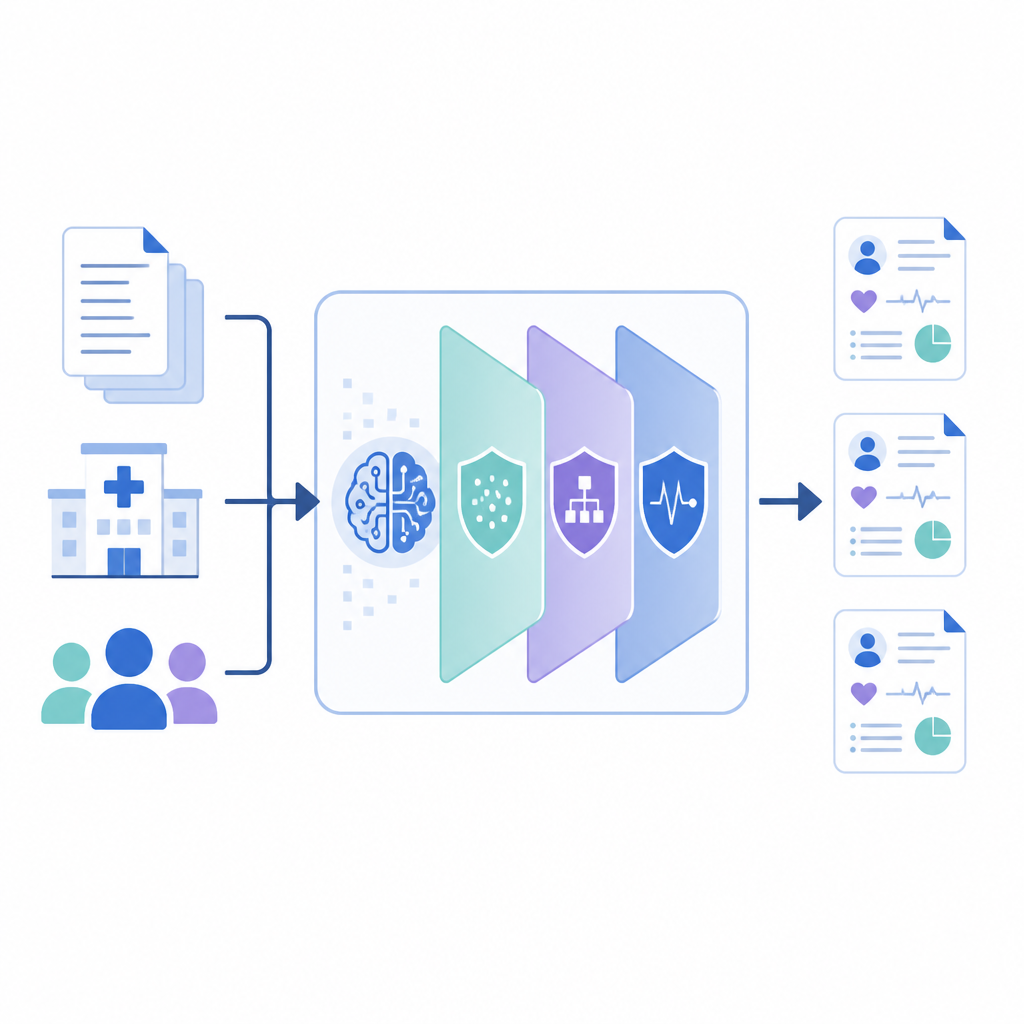
Cómo funciona el nuevo marco
PrivLLM-Guard envuelve un potente modelo de lenguaje dentro de varias capas de privacidad que cooperan entre sí. En la entrada, un codificador consciente de la privacidad perturba ligeramente la representación interna de cada entrada, de modo que la redacción de un solo paciente no pueda rastrearse. En la salida, un decodificador especialmente diseñado controla cómo se genera el texto nuevo, usando elecciones aleatorizadas que limitan cuánto puede reproducir fielmente cualquier registro. Entre ambos extremos, el sistema rastrea cuánto "presupuesto de privacidad" se ha consumido, similar a un contador, y reparte ese presupuesto entre componentes para que los elementos más sensibles, como nombres o fechas, reciban un blindaje más fuerte que hechos médicos generales como nombres de fármacos comunes.
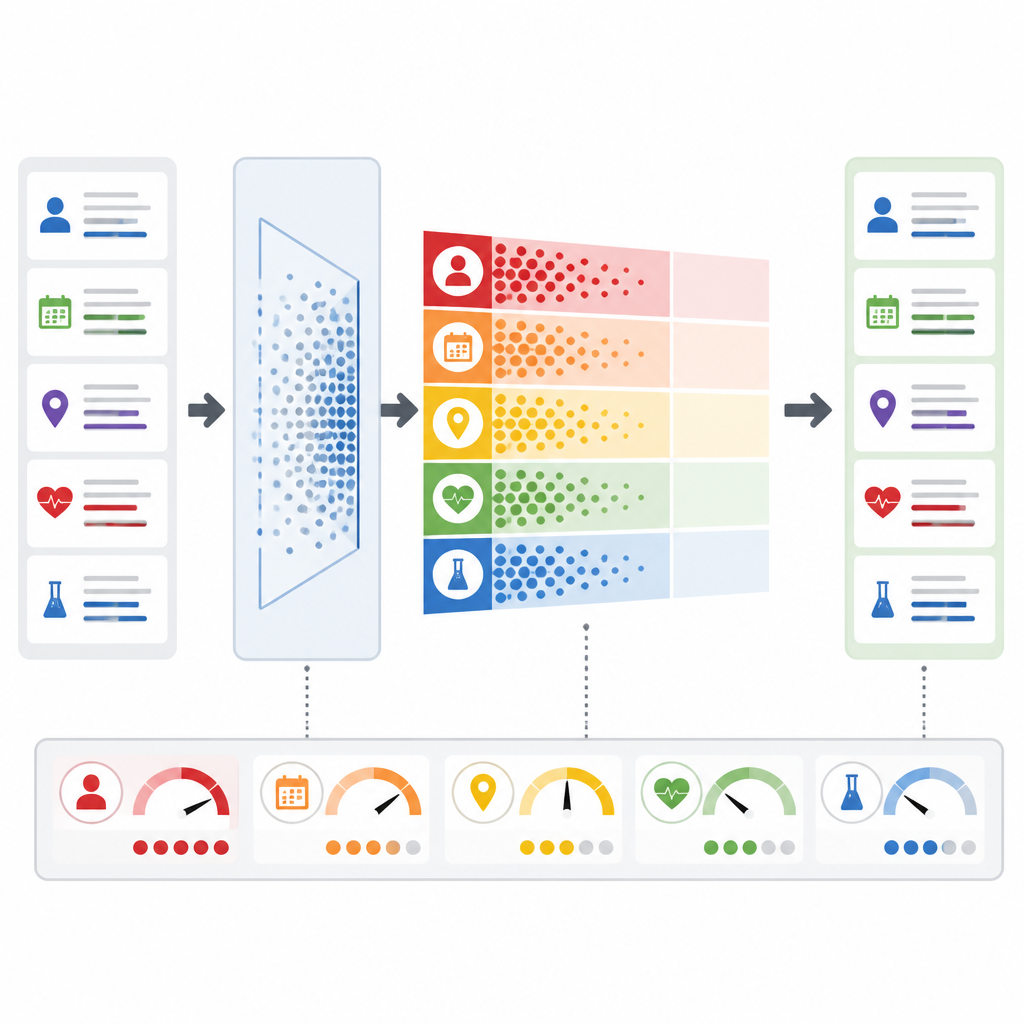
Adaptándose al riesgo en tiempo real
Una innovación clave es que PrivLLM-Guard no trata todas las solicitudes por igual. Un módulo de ruido adaptativo analiza el texto entrante para juzgar cuán privado es: por ejemplo, si se trata de un resumen rutinario o de una condición rara que podría identificar a una sola persona. Basándose en esa evaluación y en el comportamiento pasado, el sistema ajusta cuánto ruido aleatorio añade a las señales internas del modelo. Al mismo tiempo, un monitor de privacidad en tiempo real vigila cada token que produce el modelo, estimando la probabilidad de que revele algo sensible. Si ese riesgo supera un umbral preestablecido, el sistema reacciona al instante aumentando la protección o incluso deteniendo la respuesta, en lugar de esperar a una revisión humana posterior.
Manteniendo el equilibrio entre precisión y velocidad
Proteger la privacidad solo es útil si las notas resultantes siguen ayudando a los clínicos. Los autores probaron PrivLLM-Guard con millones de registros desidentificados de cuidados intensivos, atención hospitalaria general y conjuntos de datos de desafío. Bajo configuraciones de privacidad muy estrictas, el marco produjo resúmenes e informes generados que se acercaron más a los textos de referencia que varios modelos rivales con preservación de la privacidad, manteniendo a la vez términos médicos y relaciones importantes. Médicos que revisaron las salidas en especialidades como oncología, cardiología, medicina de urgencias y radiología calificaron los textos como clínicamente precisos y legibles. El sistema también se mantuvo lo bastante rápido para uso en tiempo real, manejando longitudes de nota típicas en una fracción de segundo con necesidades de memoria moderadas.
Qué supone esto para pacientes y clínicos
En términos sencillos, PrivLLM-Guard demuestra que los hospitales pueden usar modelos de lenguaje potentes para reducir la carga administrativa y clarificar registros complejos sin confiar simplemente en que la privacidad se protegerá por sí sola. Midiendo el riesgo de forma continua, adaptando la protección al tipo de información y demostrando garantías de privacidad matemáticas, el marco ofrece un camino hacia herramientas de IA clínica que respeten tanto la calidad médica como la confidencialidad de los pacientes. Aunque todavía quedan desafíos para enfermedades raras, otros idiomas y tipos de datos mixtos como imágenes, este trabajo sugiere que asistentes textuales más seguros y transparentes en la atención sanitaria están al alcance.
Cita: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Palabras clave: modelos de lenguaje clínicos, privacidad de datos médicos, privacidad diferencial, resumen de textos sanitarios, IA clínica en tiempo real