Clear Sky Science · fr
Un cadre de confidentialité différentielle adaptative pour les LLM cliniques avec calibration du bruit contextuelle, budgétisation hiérarchique et audit en temps réel
Pourquoi une IA médicale plus sûre est importante
Les hôpitaux recourent à l’intelligence artificielle pour aider les médecins à rédiger des notes et à résumer de longs dossiers médicaux, mais chaque ligne de texte peut révéler quelque chose de profondément personnel sur un patient. Cet article présente PrivLLM-Guard, une méthode pour exécuter de grands modèles de langage sur des textes cliniques afin qu’ils restent utiles pour les soins tout en réduisant fortement le risque que des détails privés s’échappent via les réponses du modèle.
Une confidentialité plus intelligente pour les textes cliniques
Les modèles de langage modernes lisent et rédigent très bien les notes médicales, mais ils peuvent aussi mémoriser et reproduire des fragments de leurs données d’entraînement. En santé, ce risque est inacceptable, car la loi et l’éthique exigent une forte protection des identités, diagnostics et antécédents des personnes. De nombreux outils actuels appliquent simplement le même niveau de bruit aléatoire partout dans un modèle, ce qui gâche souvent la qualité des sorties ou ralentit le système au point de le rendre inutilisable au chevet. Les auteurs soutiennent que l’IA clinique nécessite une approche plus ciblée qui traite différemment les diverses catégories d’information médicale.
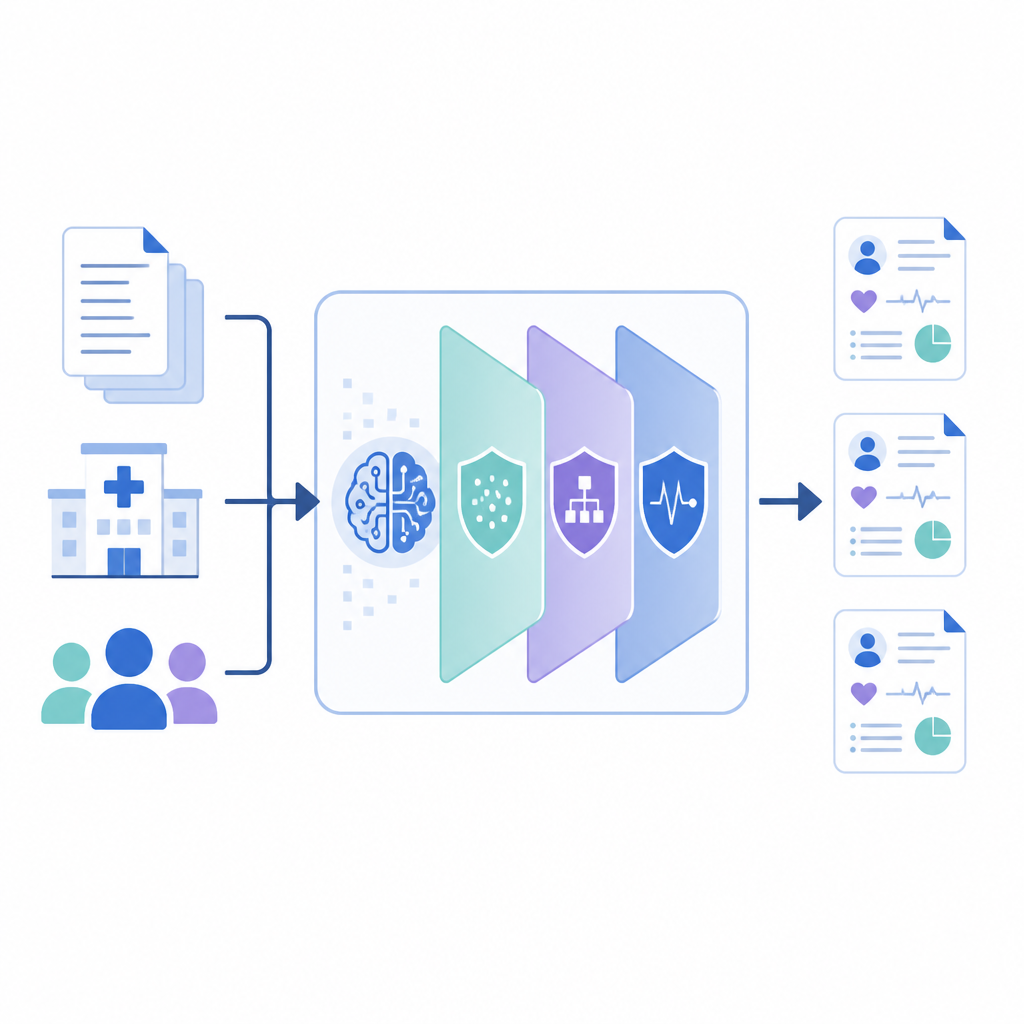
Comment fonctionne le nouveau cadre
PrivLLM-Guard encapsule un puissant modèle de langage dans plusieurs couches de confidentialité coopérantes. À l’entrée, un encodeur sensible à la confidentialité perturbe légèrement la représentation interne de chaque entrée, de sorte qu’aucun libellé d’un patient ne puisse être retracé. À la sortie, un décodeur spécialement conçu contrôle la génération du texte, en utilisant des choix aléatoires qui limitent la capacité du modèle à reproduire fidèlement un seul dossier. Entre ces deux extrémités, le système suit la quantité de « budget de confidentialité » dépensée, à la manière d’un compteur, et répartit ce budget entre les composants afin que les éléments les plus sensibles, tels que les noms ou les dates, bénéficient d’une protection plus forte que des faits médicaux généraux comme les noms de médicaments courants.
S’adapter au risque en temps réel
Une innovation clé est que PrivLLM-Guard ne traite pas chaque requête de la même manière. Un module de bruit adaptatif analyse le texte entrant pour évaluer son niveau de confidentialité : par exemple, s’il s’agit d’un résumé de routine ou d’une pathologie rare susceptible d’identifier une seule personne. En se fondant sur cette évaluation et sur le comportement passé, le système ajuste la quantité de variation aléatoire qu’il ajoute aux signaux internes du modèle. Parallèlement, un moniteur de confidentialité en temps réel surveille chaque jeton produit par le modèle, estimant la probabilité qu’il révèle quelque chose de sensible. Si ce risque dépasse un seuil prédéfini, le système réagit instantanément en renforçant la protection voire en interrompant la réponse, plutôt que d’attendre une révision humaine a posteriori.
Concilier précision et rapidité
Protéger la confidentialité n’est utile que si les notes produites restent utiles aux cliniciens. Les auteurs ont testé PrivLLM-Guard sur des millions de dossiers dé-identifiés provenant de soins intensifs, de soins hospitaliers généraux et de jeux de données de référence. Sous des réglages de confidentialité très stricts, le cadre a produit des résumés et des rapports générés plus proches des textes de référence que plusieurs modèles concurrents préservant la confidentialité, tout en conservant les termes médicaux et les relations importantes. Des médecins ayant évalué les sorties dans des spécialités comme l’oncologie, la cardiologie, la médecine d’urgence et la radiologie ont jugé les textes à la fois cliniquement précis et lisibles. Le système est également resté suffisamment rapide pour un usage en temps réel, traitant des longueurs de note typiques en une fraction de seconde avec des besoins mémoire modérés.
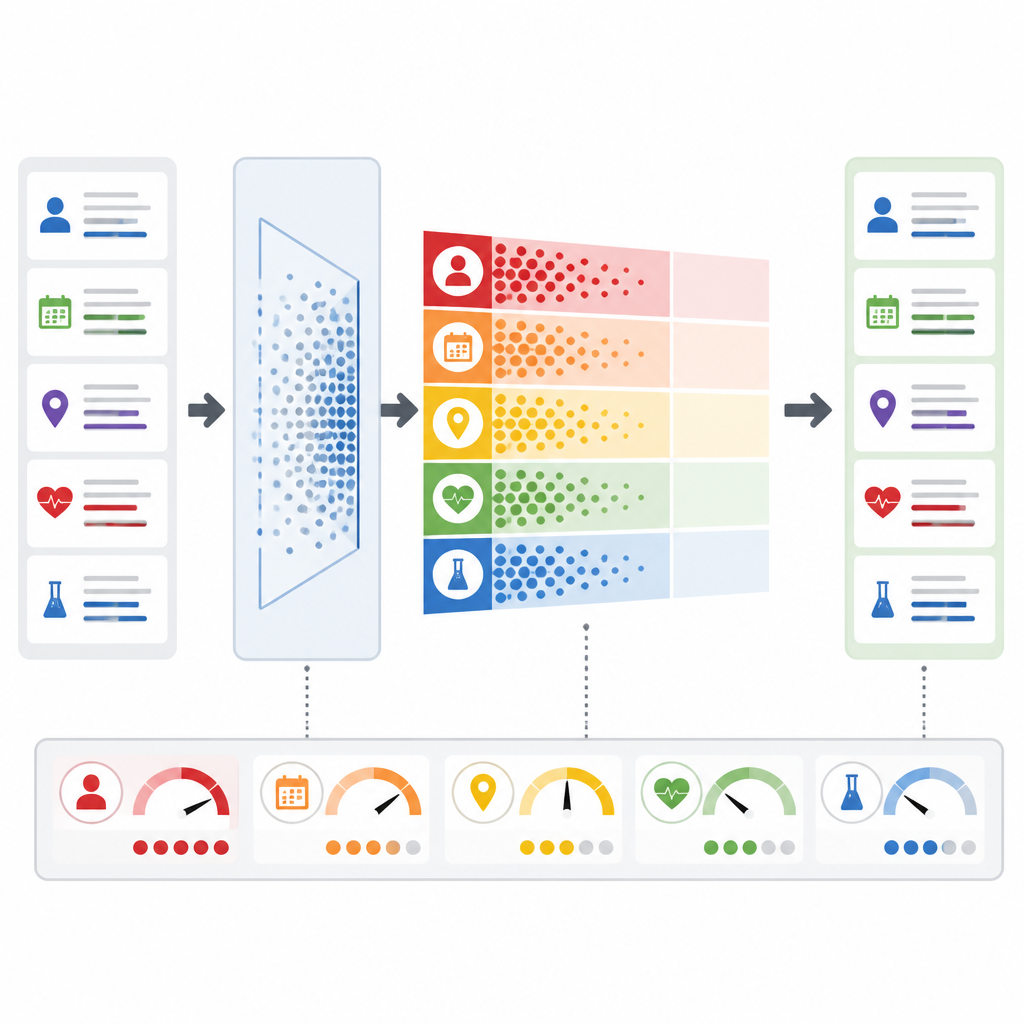
Ce que cela signifie pour les patients et les cliniciens
En termes simples, PrivLLM-Guard montre que les hôpitaux peuvent utiliser des modèles de langage puissants pour réduire la paperasserie et clarifier des dossiers complexes sans se contenter de supposer que la confidentialité se gèrera d’elle-même. En mesurant le risque en continu, en adaptant la protection au type d’information et en démontrant des garanties de confidentialité sur le plan mathématique, le cadre ouvre la voie à des outils d’IA clinique qui respectent à la fois la qualité médicale et la confidentialité des patients. Si des défis subsistent pour les maladies rares, d’autres langues et les types de données mixtes comme les images, ce travail suggère que des assistants textuels plus sûrs et plus transparents en soins de santé sont à portée de main.
Citation: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Mots-clés: modèles de langage cliniques, confidentialité des données médicales, confidentialité différentielle, résumé de textes de santé, IA clinique en temps réel