Clear Sky Science · en
An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing
Why safer medical AI matters
Hospitals are turning to artificial intelligence to help doctors draft notes and summarize long medical records, but every line of text can reveal something deeply personal about a patient. This paper introduces PrivLLM-Guard, a method for running large language models on clinical text so they stay useful for care while sharply reducing the chance that private details leak out through the model’s responses.
Smarter privacy for clinical text
Modern language models are very good at reading and writing medical notes, yet they can also memorize and repeat fragments of their training data. In healthcare, that risk is unacceptable because privacy laws and ethics demand strong protection for people’s identities, diagnoses, and histories. Many existing privacy tools simply add the same level of random noise everywhere in a model, which often ruins the quality of the output or slows the system so much that it cannot be used at the bedside. The authors argue that clinical AI needs a more tailored approach that treats different kinds of medical information with different levels of care.
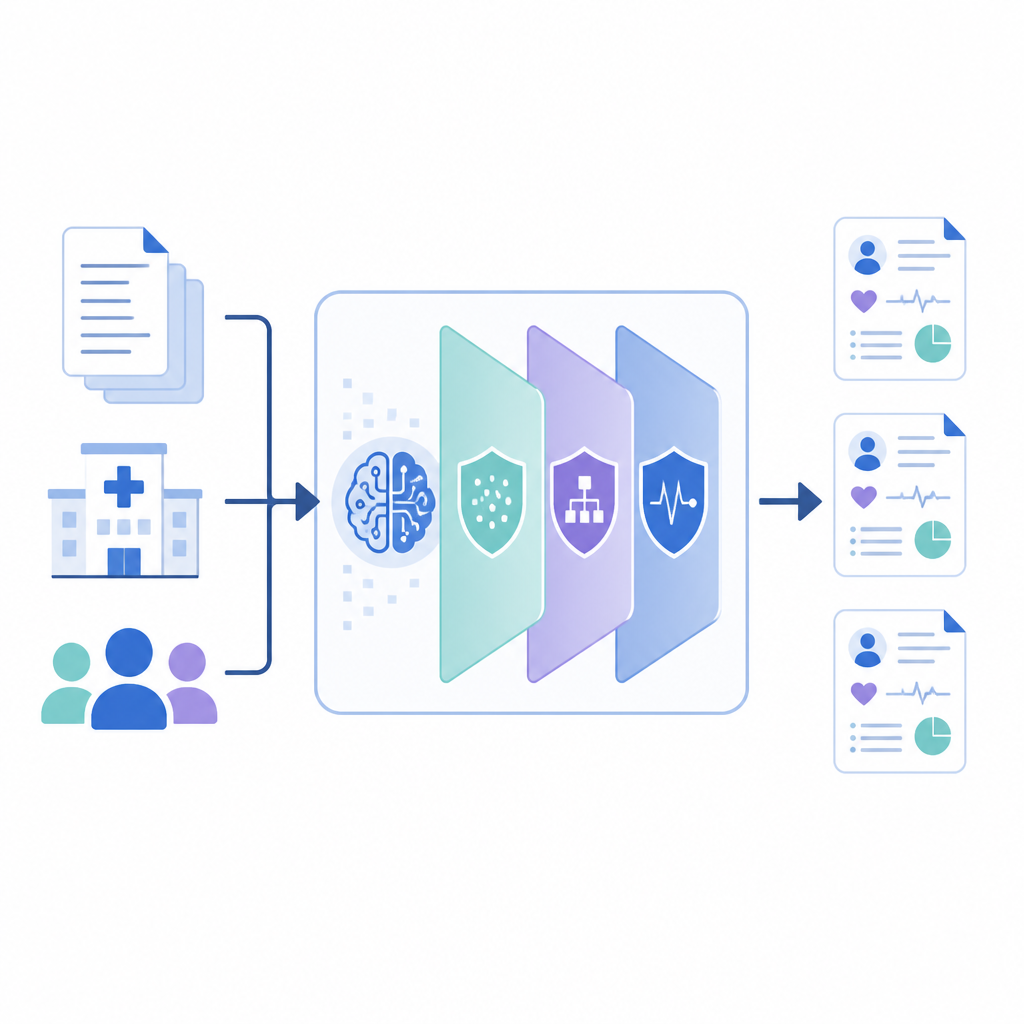
How the new framework works
PrivLLM-Guard wraps a powerful language model inside several cooperating privacy layers. On the way in, a privacy-aware encoder slightly perturbs the internal representation of each input, so that no single patient’s wording can be traced. On the way out, a specially designed decoder controls how new text is generated, using randomized choices that limit how closely it can echo any one record. Between these ends, the system tracks how much “privacy budget” has been spent, much like a meter, and spreads that budget across components so that the most sensitive items, such as names or dates, get stronger shielding than general medical facts like common drug names.
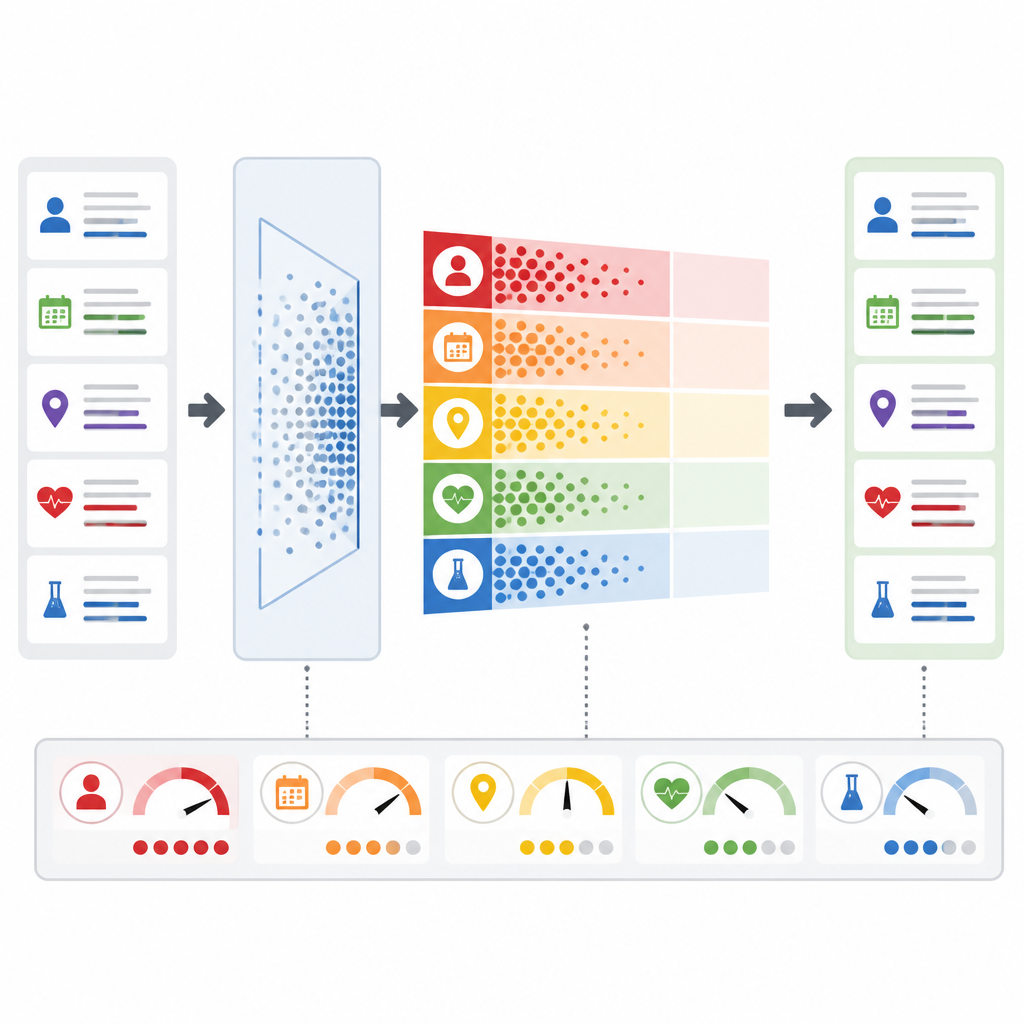
Adapting to risk in real time
A key innovation is that PrivLLM-Guard does not treat every request the same. An adaptive noise module analyzes the incoming text to judge how private it is: for example, whether it is a routine summary or a rare condition that might identify a single person. Based on that assessment and on past behavior, the system adjusts how much random variation it adds to the model’s internal signals. At the same time, a real-time privacy monitor watches each token the model produces, estimating the chance that it reveals something sensitive. If that risk rises above a preset threshold, the system reacts instantly by boosting protection or even halting the response, rather than waiting for a human review after the fact.
Keeping accuracy and speed in balance
Protecting privacy is only useful if the resulting notes still help clinicians. The authors tested PrivLLM-Guard on millions of de-identified records from intensive care, general hospital care, and challenge datasets. Under very strict privacy settings, the framework produced summaries and generated reports that were closer to reference texts than several competing privacy-preserving models, while keeping important medical terms and relationships intact. Doctors who reviewed the outputs in specialties such as oncology, cardiology, emergency medicine, and radiology rated the text as both clinically accurate and readable. The system also remained fast enough for real-time use, handling typical note lengths in a fraction of a second with moderate memory needs.
What this means for patients and clinicians
In plain terms, PrivLLM-Guard shows that hospitals can use powerful language models to cut paperwork and clarify complex records without simply trusting that privacy will take care of itself. By measuring risk continuously, tailoring protection to the type of information, and proving privacy guarantees mathematically, the framework offers a path toward clinical AI tools that respect both medical quality and patient confidentiality. While challenges remain for rare diseases, other languages, and mixed data types like images, this work suggests that safer, more transparent text-based assistants in health care are within reach.
Citation: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Keywords: clinical language models, medical data privacy, differential privacy, healthcare text summarization, real-time clinical AI