Clear Sky Science · pl
Adaptacyjny framework prywatności różnicowej dla klinicznych LLM-ów z kontekstowo dostosowaną kalibracją szumu, hierarchicznym budżetowaniem i audytem w czasie rzeczywistym
Dlaczego bezpieczniejsza medyczna AI ma znaczenie
Szpitale sięgają po sztuczną inteligencję, by pomagała lekarzom sporządzać notatki i streszczać obszerne dokumentacje medyczne, ale każda linia tekstu może ujawnić coś głęboko osobistego o pacjencie. W artykule przedstawiono PrivLLM-Guard — metodę uruchamiania dużych modeli językowych na tekstach klinicznych tak, aby pozostały przydatne w opiece, jednocześnie znacząco zmniejszając ryzyko wycieku prywatnych informacji w odpowiedziach modelu.
Inteligentniejsza ochrona prywatności dla tekstów klinicznych
Nowoczesne modele językowe świetnie czytają i piszą notatki medyczne, ale mogą też zapamiętywać i powtarzać fragmenty danych treningowych. W opiece zdrowotnej takie ryzyko jest nie do przyjęcia, ponieważ przepisy i etyka wymagają silnej ochrony tożsamości, diagnoz i historii pacjentów. Wiele istniejących narzędzi prywatności po prostu dodaje ten sam poziom losowego szumu wszędzie, co często psuje jakość wyjścia lub spowalnia system do stopnia uniemożliwiającego użycie przy łóżku pacjenta. Autorzy argumentują, że kliniczna AI potrzebuje bardziej dopasowanego podejścia, które traktuje różne rodzaje informacji medycznych z różnym stopniem ostrożności.
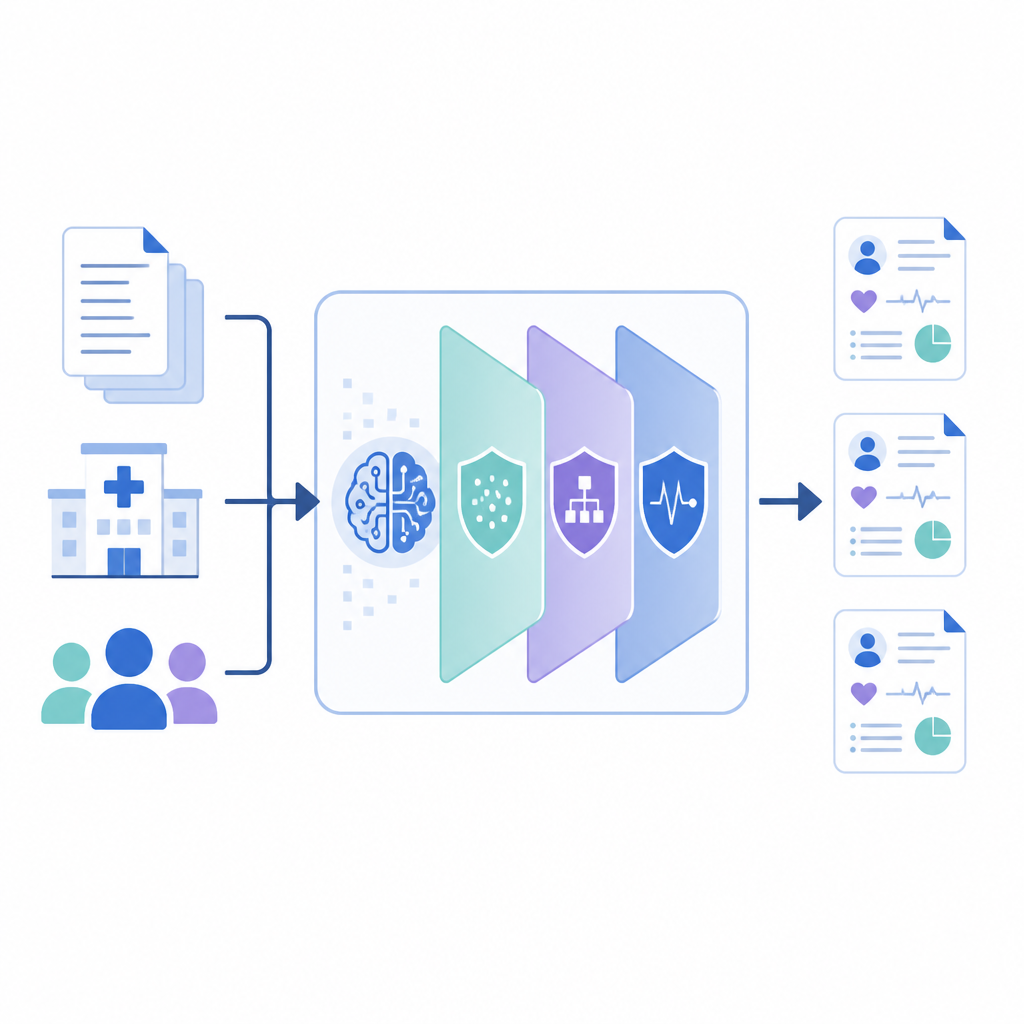
Jak działa nowy framework
PrivLLM-Guard otacza potężny model językowy kilkoma współpracującymi warstwami prywatności. Na wejściu prywatnościowy enkoder nieznacznie zniekształca wewnętrzną reprezentację każdego wejścia, tak by sformułowanie pojedynczego pacjenta nie dało się wyśledzić. Na wyjściu specjalnie zaprojektowany dekoder kontroluje generowanie nowego tekstu, stosując losowe wybory ograniczające możliwość odwzorowania któregokolwiek zapisu. Pomiędzy tymi punktami system śledzi, ile „budżetu prywatności” zostało zużyte, niczym licznik, i rozdziela ten budżet między komponenty tak, aby najwrażliwsze elementy, takie jak imiona czy daty, otrzymywały silniejsze zabezpieczenie niż ogólne fakty medyczne, np. nazwy powszechnych leków.
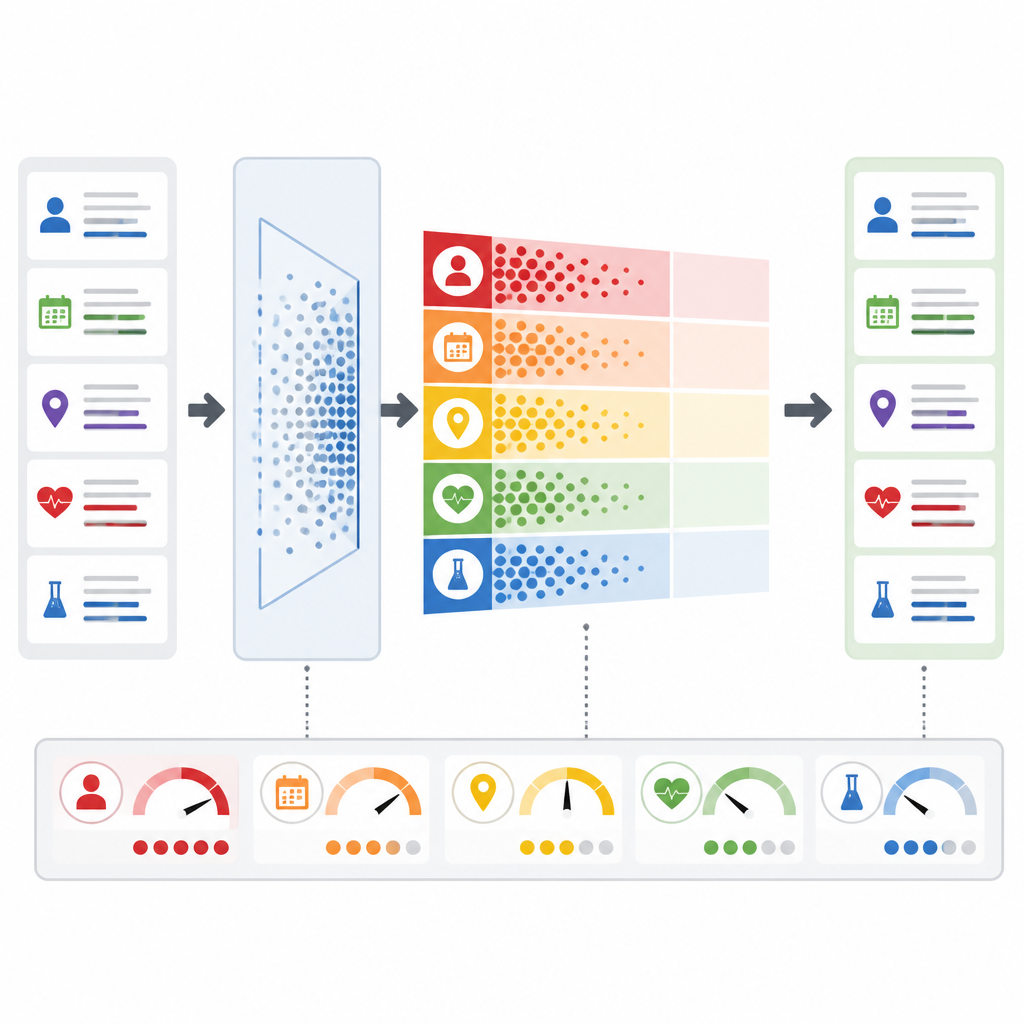
Dostosowywanie do ryzyka w czasie rzeczywistym
Kluczową innowacją jest to, że PrivLLM-Guard nie traktuje każdego żądania jednakowo. Adaptacyjny moduł szumu analizuje przychodzący tekst, oceniając jego stopień prywatności: na przykład, czy jest to rutynowe streszczenie, czy rzadkie schorzenie, które mogłoby zidentyfikować pojedynczą osobę. Na podstawie tej oceny i dotychczasowego zachowania system dostosowuje ilość losowej wariancji dodawanej do wewnętrznych sygnałów modelu. Równocześnie monitor prywatności w czasie rzeczywistym obserwuje każdy token generowany przez model, szacując prawdopodobieństwo ujawnienia czegoś wrażliwego. Jeśli to ryzyko przekroczy ustawiony próg, system reaguje natychmiast, zwiększając ochronę lub nawet przerywając odpowiedź, zamiast czekać na późniejszą ludzką weryfikację.
Równowaga między dokładnością a szybkością
Ochrona prywatności ma sens tylko wtedy, gdy wygenerowane notatki nadal pomagają klinicystom. Autorzy przetestowali PrivLLM-Guard na milionach zanonimizowanych zapisów z intensywnej opieki, ogólnej opieki szpitalnej i zbiorach testowych. Przy bardzo rygorystycznych ustawieniach prywatności framework wytwarzał streszczenia i raporty bliższe tekstom referencyjnym niż kilka konkurencyjnych modeli zachowujących prywatność, jednocześnie zachowując istotne terminy medyczne i relacje między nimi. Lekarze oceniający wyniki w takich specjalnościach jak onkologia, kardiologia, medycyna ratunkowa i radiologia ocenili tekst jako zarówno klinicznie dokładny, jak i czytelny. System pozostał też wystarczająco szybki do użycia w czasie rzeczywistym, obsługując typowe długości notatek w ułamku sekundy przy umiarkowanych wymaganiach pamięciowych.
Co to oznacza dla pacjentów i klinicystów
Mówiąc prosto, PrivLLM-Guard pokazuje, że szpitale mogą korzystać z potężnych modeli językowych, by zmniejszyć obciążenie dokumentacyjne i wyjaśniać złożone zapisy, nie polegając tylko na nadziei, że prywatność sama się obroni. Dzięki ciągłemu pomiarowi ryzyka, dopasowywaniu ochrony do rodzaju informacji oraz matematycznemu udowadnianiu gwarancji prywatności, framework oferuje drogę do narzędzi klinicznej AI, które szanują zarówno jakość medyczną, jak i poufność pacjentów. Chociaż wciąż istnieją wyzwania związane z rzadkimi chorobami, innymi językami i mieszanymi typami danych, takimi jak obrazy, praca ta sugeruje, że bezpieczniejsze, bardziej przejrzyste asystenty tekstowe w opiece zdrowotnej są w zasięgu ręki.
Cytowanie: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Słowa kluczowe: kliniczne modele językowe, prywatność danych medycznych, prywatność różnicowa, streszczenie tekstów medycznych, kliniczna AI w czasie rzeczywistym