Clear Sky Science · de
Ein adaptives Differential-Privacy-Framework für klinische LLMs mit kontextbewusster Rauschkalibrierung, hierarchischem Budgeting und Echtzeit-Auditierung
Warum sicherere medizinische KI wichtig ist
Krankenhäuser setzen zunehmend auf Künstliche Intelligenz, um Ärztinnen und Ärzten beim Verfassen von Notizen und beim Zusammenfassen umfangreicher Patientenakten zu helfen. Doch jede Textzeile kann etwas sehr Persönliches über eine Patientin oder einen Patienten offenbaren. Dieses Papier stellt PrivLLM-Guard vor, eine Methode, mit der große Sprachmodelle auf klinischen Texten betrieben werden können, sodass sie für die Versorgung nützlich bleiben und gleichzeitig die Wahrscheinlichkeit verringert wird, dass private Details über die Modellantworten durchsickern.
Intelligenterer Schutz für klinische Texte
Moderne Sprachmodelle sind sehr gut im Lesen und Schreiben medizinischer Notizen, können aber auch Fragmente ihrer Trainingsdaten behalten und wiedergeben. In der Gesundheitsversorgung ist dieses Risiko inakzeptabel, weil Gesetze und Ethik strenge Schutzmaßnahmen für Identitäten, Diagnosen und Krankengeschichten verlangen. Viele bestehende Datenschutzwerkzeuge fügen dem Modell einfach überall denselben Grad zufälligen Rauschens hinzu, was häufig die Ausgabequalität zerstört oder das System so stark verlangsamt, dass es nicht am Krankenbett einsetzbar ist. Die Autoren argumentieren, dass klinische KI einen maßgeschneiderteren Ansatz benötigt, der unterschiedliche Arten medizinischer Informationen unterschiedlich behandelt.
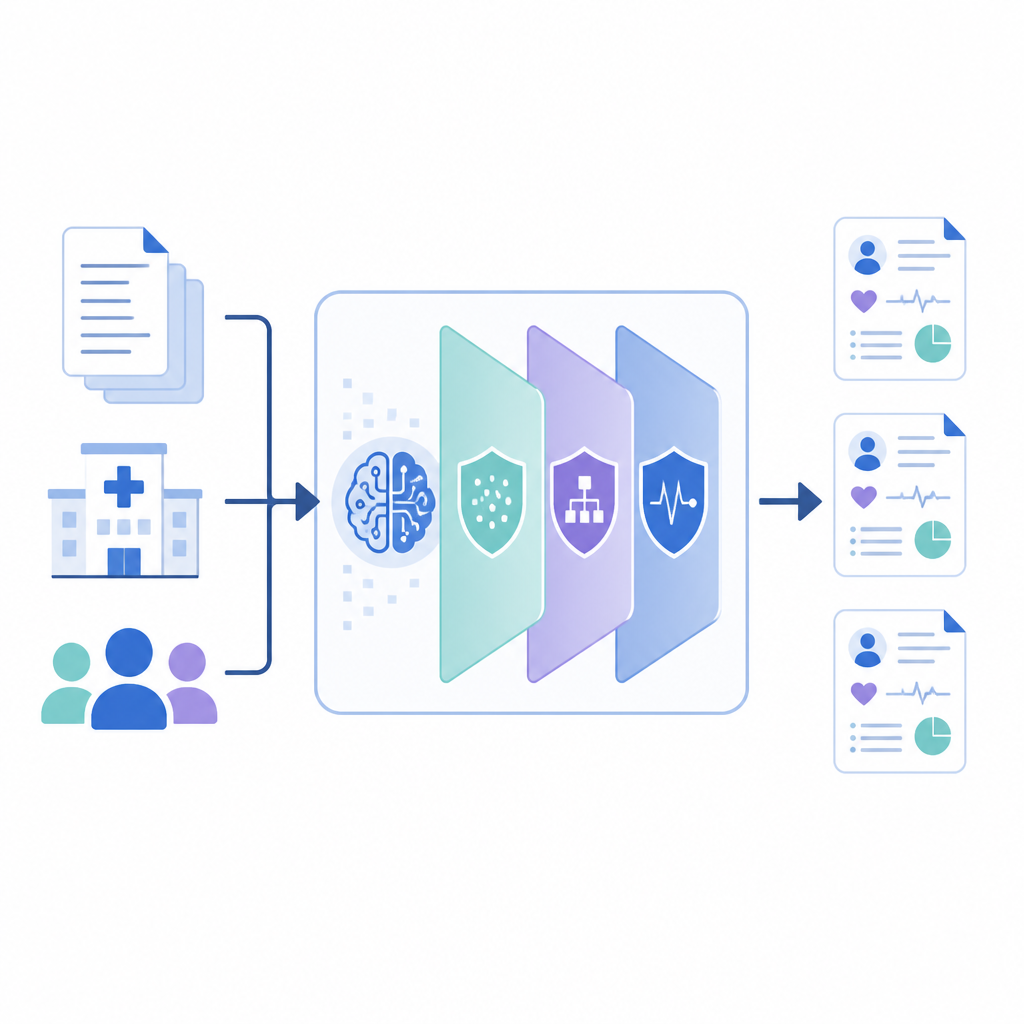
Wie das neue Framework funktioniert
PrivLLM-Guard kapselt ein leistungsfähiges Sprachmodell in mehrere kooperierende Datenschutzelemente. Beim Eingang verändert ein datenschutzbewusster Encoder die interne Repräsentation jeder Eingabe leicht, sodass sich die Formulierung einer einzelnen Patientin oder eines einzelnen Patienten nicht zurückverfolgen lässt. Beim Ausgang steuert ein speziell entwickelter Decoder die Textgenerierung, indem er randomisierte Entscheidungen nutzt, die begrenzen, wie genau das Modell einzelne Datensätze wiedergeben kann. Dazwischen verfolgt das System, wie viel "Privacy-Budget" verbraucht wurde — ähnlich einem Zähler — und verteilt dieses Budget auf Komponenten, sodass besonders sensible Elemente wie Namen oder Datumsangaben stärker geschützt werden als allgemeine medizinische Fakten wie gebräuchliche Wirkstoffnamen.
Anpassung an Risiko in Echtzeit
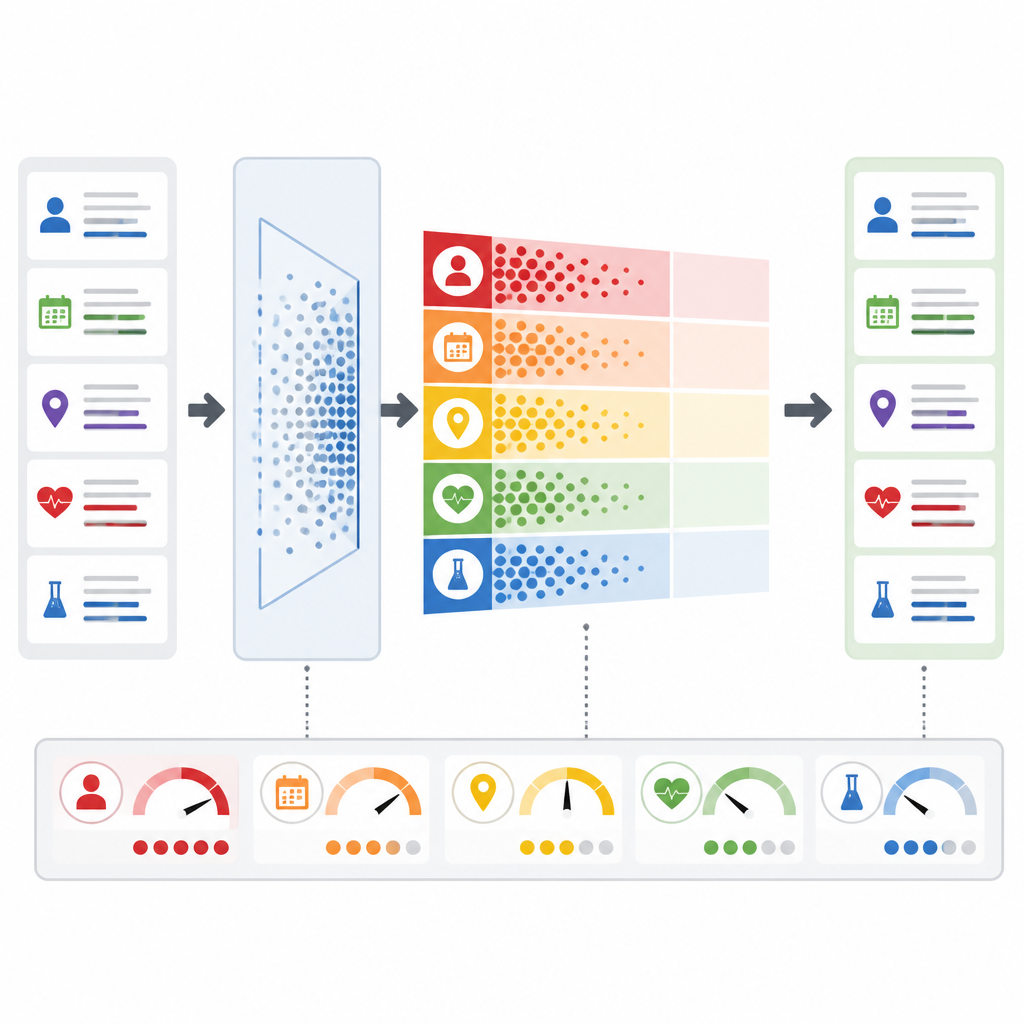
Eine zentrale Innovation ist, dass PrivLLM-Guard nicht jede Anfrage gleich behandelt. Ein adaptives Rauschmodul analysiert den eingehenden Text, um dessen Sensitivität zu beurteilen: etwa ob es sich um eine Routinezusammenfassung oder um eine seltene Erkrankung handelt, die eine einzelne Person identifizieren könnte. Basierend auf dieser Einschätzung und auf vergangenem Verhalten passt das System an, wie viel zufällige Variation es den internen Signalen des Modells beimischt. Gleichzeitig überwacht ein Echtzeit-Privacy-Monitor jedes Token, das das Modell erzeugt, und schätzt die Wahrscheinlichkeit ein, dass es etwas Sensibles offenbart. Wenn dieses Risiko einen voreingestellten Schwellenwert überschreitet, reagiert das System sofort, indem es den Schutz erhöht oder die Antwort sogar stoppt, anstatt auf eine nachträgliche menschliche Überprüfung zu warten.
Balance zwischen Genauigkeit und Geschwindigkeit
Datenschutz ist nur dann nützlich, wenn die resultierenden Notizen Ärztinnen und Ärzten weiterhin helfen. Die Autoren testeten PrivLLM-Guard an Millionen de-identifizierter Datensätze aus der Intensivpflege, der allgemeinen Krankenhausversorgung und speziellen Challenge-Datensätzen. Selbst unter sehr strengen Privatsphäre-Einstellungen lieferte das Framework Zusammenfassungen und Berichte, die referenztextnaher waren als die Ausgaben mehrerer konkurrierender privacy-schützender Modelle, während wichtige medizinische Begriffe und Zusammenhänge erhalten blieben. Ärztinnen und Ärzte aus Fachgebieten wie Onkologie, Kardiologie, Notfallmedizin und Radiologie bewerteten die Texte sowohl als klinisch akkurat als auch gut lesbar. Das System blieb außerdem schnell genug für den Echtzeiteinsatz und verarbeitete typische Notizenlängen in Bruchteilen einer Sekunde bei moderatem Speicherbedarf.
Was das für Patientinnen, Patienten und Klinikpersonal bedeutet
Einfach gesagt zeigt PrivLLM-Guard, dass Krankenhäuser leistungsfähige Sprachmodelle einsetzen können, um Papierarbeit zu reduzieren und komplexe Akten zu klären, ohne blind darauf zu vertrauen, dass der Datenschutz von selbst funktioniert. Durch kontinuierliche Risikomessung, an den Informationstyp angepassten Schutz und mathematisch nachgewiesene Privacy-Garantien bietet das Framework einen Weg zu klinischen KI-Werkzeugen, die sowohl medizinische Qualität als auch Patientengeheimnis respektieren. Zwar bleiben Herausforderungen für seltene Erkrankungen, andere Sprachen und gemischte Datentypen wie Bilder bestehen, doch diese Arbeit zeigt, dass sicherere, transparentere textbasierte Assistenten im Gesundheitswesen in Reichweite sind.
Zitation: Alghamdi, A.D. An adaptive differential privacy framework for clinical llms with context-aware noise calibration, hierarchical budgeting, and real-time auditing. Sci Rep 16, 15781 (2026). https://doi.org/10.1038/s41598-026-45883-6
Schlüsselwörter: klinische Sprachmodelle, Datenschutz bei medizinischen Daten, Differential Privacy, Zusammenfassung von Gesundheitstexten, Echtzeit-Klinik-KI