Clear Sky Science · zh
基于RGB条件的频域细化用于稀疏到密集深度补全
为日常机器提供更清晰的数字深度
自动驾驶汽车、配送机器人和增强现实头显都需要不仅识别物体长什么样,还要知道物体有多远。现代激光传感器只提供稀疏的距离点,这对于安全导航或可信的 3D 图形来说太稀疏。本文提出了一种利用相机图像“填补”缺失深度信息的新方法,生成的深度图细节丰富,在保持物体边缘清晰的同时不会被表面纹理所误导。
为什么填补距离如此困难
深度补全试图将非常稀疏的距离样本转化为完整的深度图,并用普通彩色照片作为引导。早期系统常在神经网络内部直接混合颜色和深度特征。这种捷径带来两方面相互矛盾的问题。一方面,网络可能会把颜色图像中的砖块纹理、条纹或标志直接复制到深度图中,形成假的凸凹。另一方面,那些为了去除这些虚假细节而强力平滑的方法往往会模糊真实的物体边界,例如汽车或路牌的轮廓。在细节与可靠性之间取得平衡,已成为现实应用中的核心障碍。
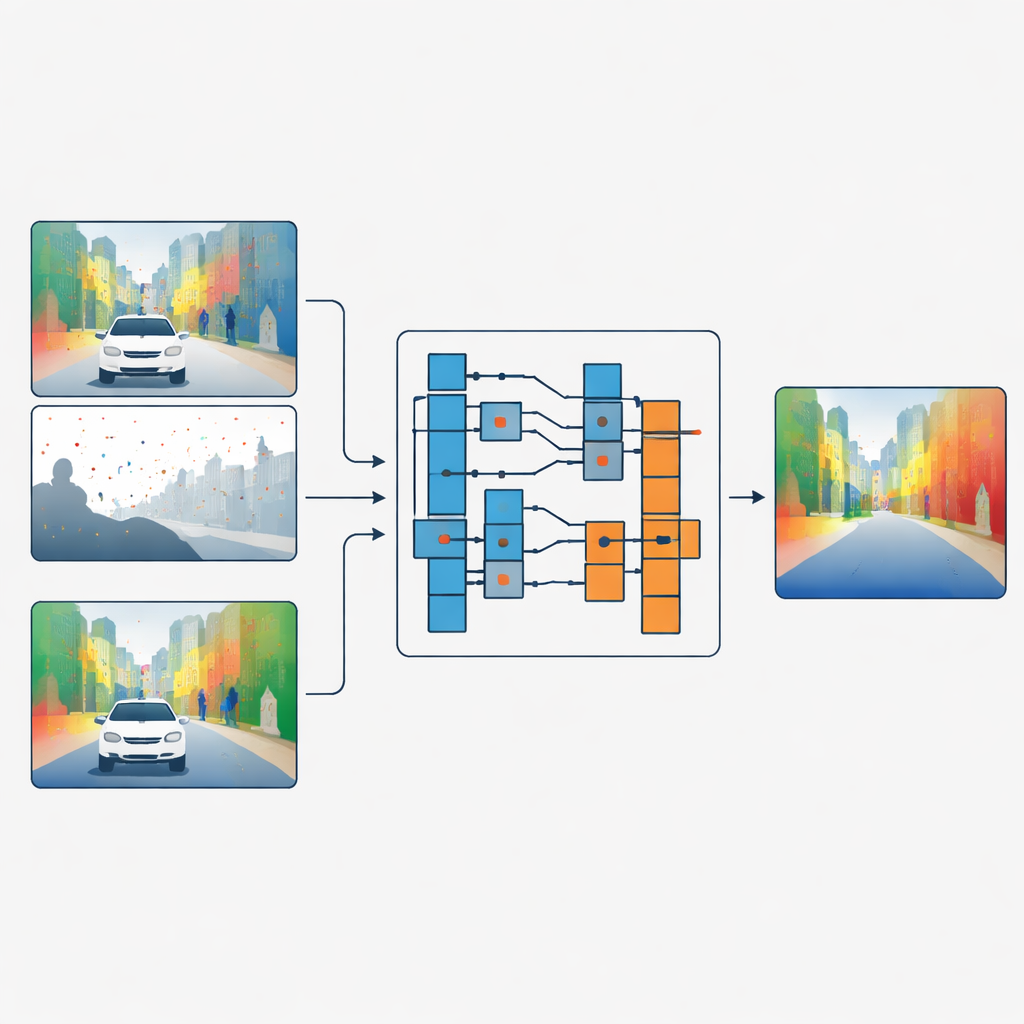
将形状与表面细节分离
作者提出了一种不同的策略:不是直接混合颜色和深度特征,而是让彩色图像决定如何对深度数据进行滤波,但两者从不直接混合。网络首先在独立分支中分别处理稀疏深度和颜色。在网络的关键阶段,一个称为引导细化模块(Guided Refinement Module)的模块通过频率透镜观察颜色特征。使用小波变换,它将颜色信息分解为平滑的低频部分,捕捉宽阔的形状和缓慢变化的区域,以及高频部分,捕捉诸如叶子或窗框等锋利边缘和细微纹理。
针对每个区域自适应的智能滤波器
在这样分离颜色信息后,该方法学习一组不同尺寸的小图像滤波器。对于每个区域和每个频带,网络选择应用多大尺寸的滤波器以及应用的强度。在应当平滑过渡的平滑区域倾向使用大滤波器,帮助将可靠测量值扩散到空白区域;在强边缘附近使用小滤波器,以使深度图保持清晰边界,而不是将一个物体模糊到另一个上。关键在于,滤波器始终仅将深度值与其他深度值组合;颜色数据仅引导使用哪种滤波器以及在何处使用。这种“操作者而非数值”的连接充当了瓶颈,防止了颜色图像的表面纹理被刻印为虚假的深度。
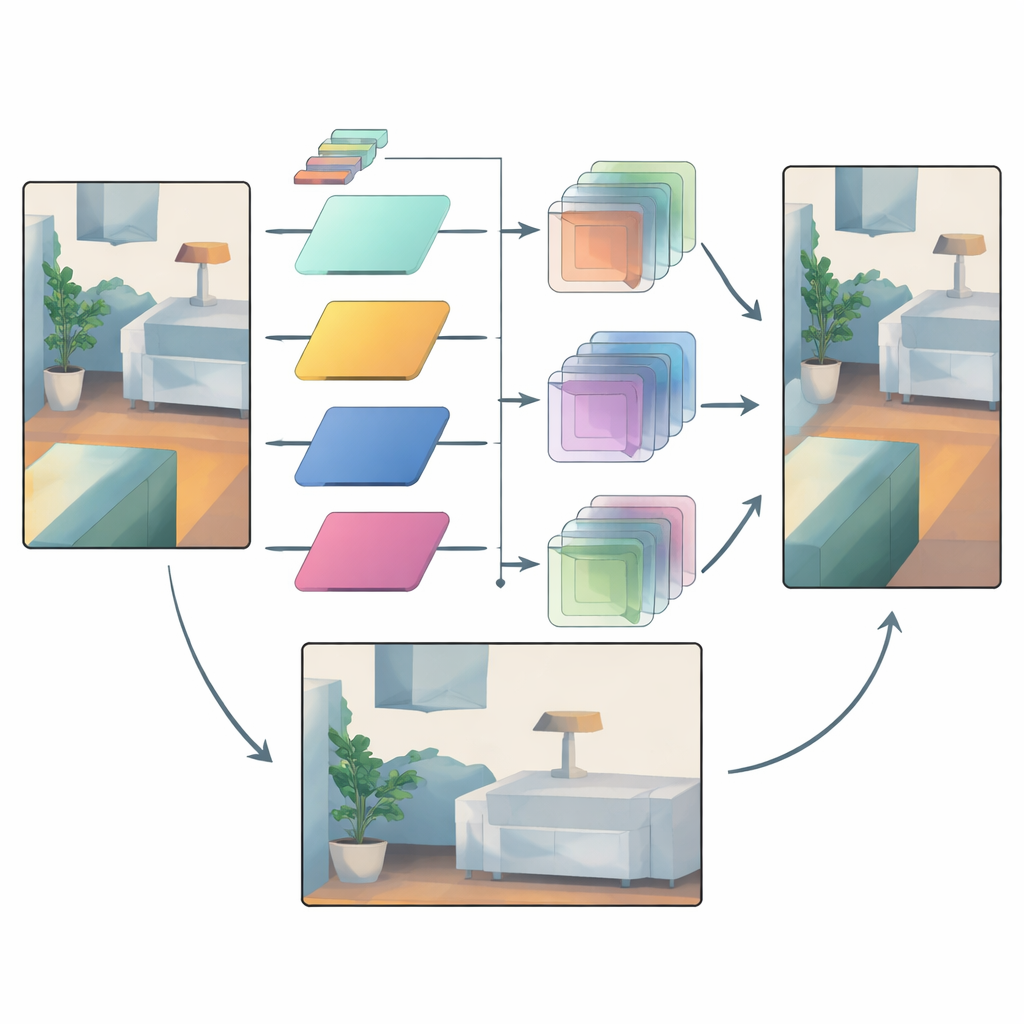
信任可靠信号同时抑制不确定性
即便使用自适应滤波,仍有一些区域不确定——比如透过雨雾看到的远处物体,或激光点非常稀少的区域。为此,网络使用第二种机制比较早期和晚期阶段的中间深度特征。早期特征更接近原始传感器输入,携带哪些区域可信的信息。模型构建注意力掩码,以突出结构可靠的区域和最重要的特征通道。这些掩码随后温和地增强可靠细节并抑制在流水线后期引入的可疑变化,从而减少过度平滑和杂散伪影。
在道路和室内场景上的验证增益
团队在两个标准基准上测试了他们的方法:用于户外驾驶场景的 KITTI 和用于室内房间的 NYUv2。他们的方法在多种误差度量上持续匹配或超越领先竞争者,同时参数量比一些最复杂的模型更少。当深度读数极为稀疏时(例如模拟只有少量扫描线或点的廉价激光传感器),其表现尤为出色。视觉对比显示细长结构如路灯杆被更干净地保留,汽车或家具与背景的分离更清晰,纹理复制产生的虚假波纹大为减少。
这对现实世界 3D 视觉意味着什么
通过重新思考相机图像如何引导深度补全,这项工作表明可以在保留来自颜色图的有用线索(如边缘和总体布局)的同时避免继承其误导性的纹理。关键是使用频率分析和精心约束的交互,使颜色决定深度值应如何被组合,而不是决定数值本身。因此,机器人、车辆和 AR 设备可以从相同的稀疏传感器中获得更密集、更清晰的深度图,从而把更安全的导航和更稳定的 3D 体验带入日常生活的愿景更近一步。
引用: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
关键词: 深度补全, 激光雷达, 3D 感知, 计算机视觉, 自动驾驶