Clear Sky Science · en
RGB-conditioned frequency domain refinement for sparse-to-dense depth completion
Sharper digital depth for everyday machines
Self-driving cars, delivery robots and augmented reality headsets all need to understand how far away things are, not just what they look like. Modern laser sensors provide only a sprinkling of distance points, which is too sparse for safe navigation or convincing 3D graphics. This paper presents a new way to "fill in" the missing depth information using camera images, producing detailed distance maps that keep object edges crisp without being fooled by surface textures.
Why filling in distance is so hard
Depth completion tries to turn a very sparse set of distance samples into a full depth image, using an ordinary color photo as guidance. Earlier systems often mix color and depth information directly inside a neural network. That shortcut creates two opposing problems. On one hand, the network may copy brick patterns, stripes or logos from the color image into the depth map as fake bumps and dents. On the other, methods that aggressively smooth away these false details tend to blur the true boundaries between objects, such as the outline of a car or a street sign. Balancing detail and reliability has become a central obstacle for real-world applications.
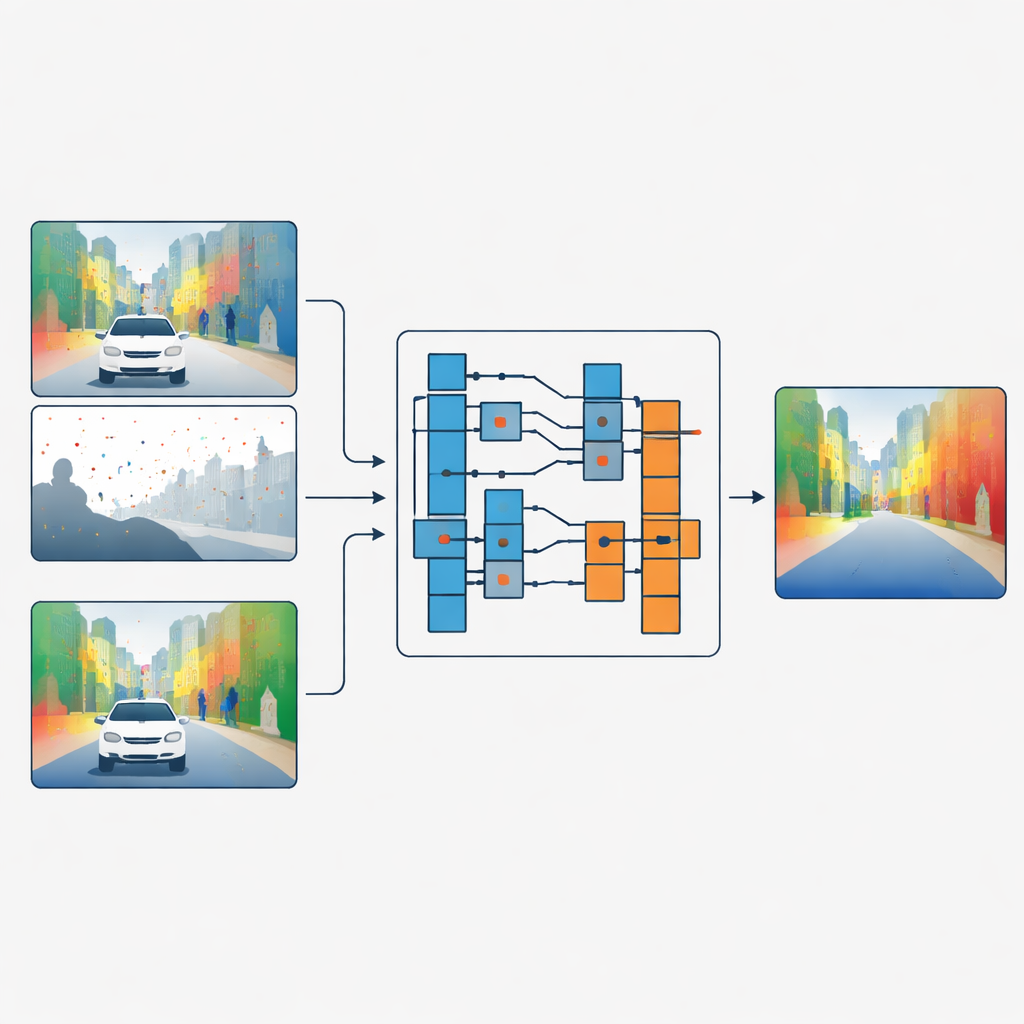
Separating shapes from surface detail
The authors propose a different strategy: instead of blending color and depth features, they let the color image decide how the depth data should be filtered, without ever mixing the two directly. Their network first processes sparse depth and color in separate branches. In key stages of the network, a module called the Guided Refinement Module looks at the color features through a frequency lens. Using a wavelet transform, it splits the color information into smooth, low-frequency parts that capture broad shapes and slowly changing regions, and high-frequency parts that capture sharp edges and fine textures like leaves or window frames.
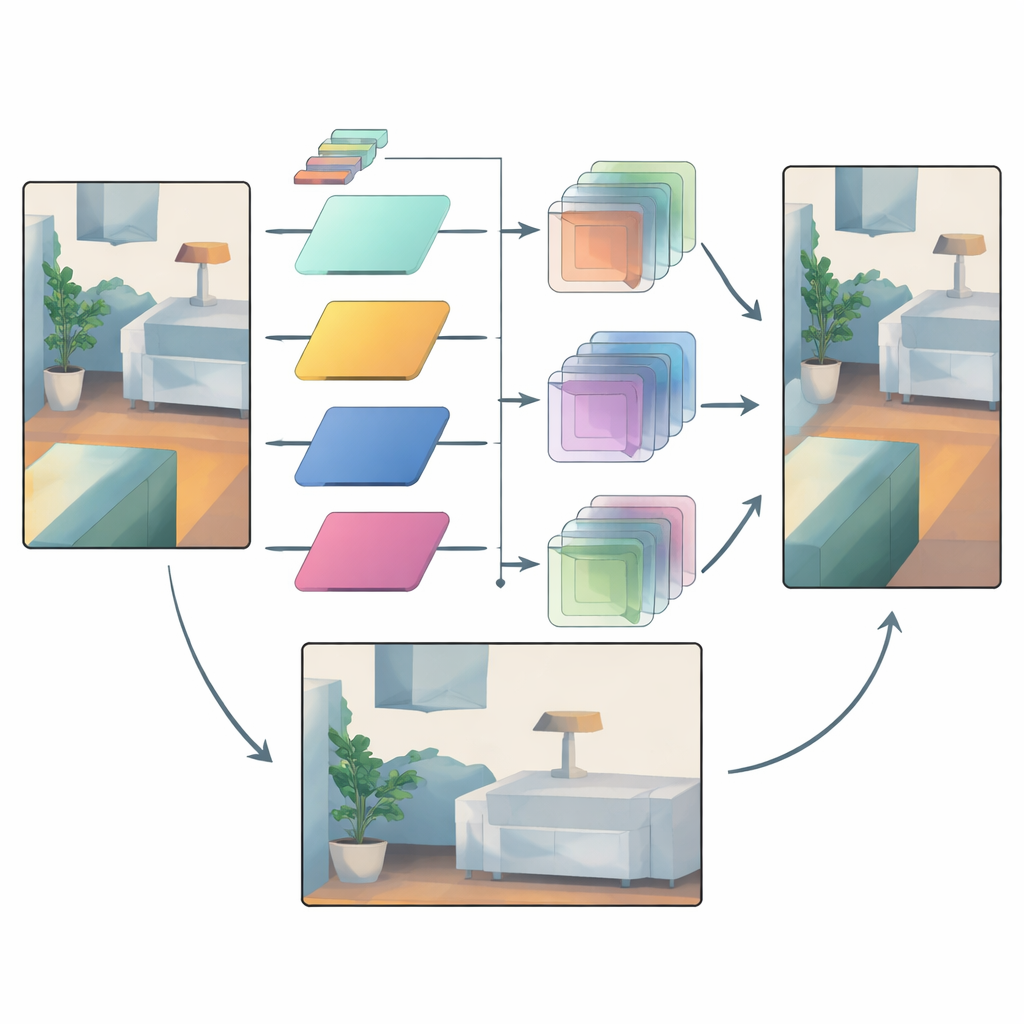
Smart filters that adapt to each region
Once the color information is split this way, the method learns a family of small image filters of different sizes. For each region and each frequency band, the network chooses how large a filter to apply and how strongly to apply it. Large filters are favored in smooth areas where depth should change gradually, helping to spread reliable measurements across empty regions. Small filters are used near strong edges, so that the depth map keeps clear borders instead of smearing one object into another. Crucially, the filters always combine only depth values with other depth values; the color data merely steers which filter to use and where. This "operator but not value" connection acts as a bottleneck that prevents surface textures in the color image from being imprinted as fake depth.
Trusting reliable signals while taming uncertainty
Even with adaptive filtering, some areas remain uncertain—think of distant objects seen through rain, or regions where very few laser points are available. To handle this, the network uses a second mechanism that compares intermediate depth features from early and late stages. Early features are closer to the raw sensor input and carry a sense of which regions are trustworthy. The model builds attention masks that highlight where structure is reliable and which feature channels matter most. These masks then gently boost confident details and damp down suspicious changes introduced later in the pipeline, reducing over-smoothing and stray artifacts.
Proven gains on roads and indoors
The team tests their approach on two standard benchmarks: KITTI for outdoor driving scenes and NYUv2 for indoor rooms. Their method consistently matches or beats leading competitors across multiple error measures, while using fewer parameters than some of the heaviest models. It performs particularly well when depth readings are extremely sparse, such as when simulating cheaper laser sensors with only a handful of scan lines or points. Visual comparisons show thinner structures, like lamp posts, preserved cleanly, and cars or furniture separated more clearly from their backgrounds, with far fewer false ripples from texture copying.
What this means for real-world 3D vision
By rethinking how camera images guide depth completion, this work shows that it is possible to keep the helpful cues from color—such as edges and overall layout—without inheriting their misleading textures. The key is to use frequency analysis and carefully constrained interactions so that color decides how depth values are combined, not what the values should be. As a result, robots, vehicles and AR devices can obtain denser, sharper depth maps from the same sparse sensors, bringing safer navigation and more stable 3D experiences closer to everyday reality.
Citation: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Keywords: depth completion, lidar, 3D perception, computer vision, autonomous driving