Clear Sky Science · pt
Refinamento no domínio da frequência condicionado por RGB para completion de profundidade de esparso a denso
Profundidade digital mais nítida para máquinas do dia a dia
Carros autônomos, robôs de entrega e headsets de realidade aumentada precisam entender a distância dos objetos, não apenas sua aparência. Sensores a laser modernos fornecem apenas uma sprinkling de pontos de distância, o que é demasiado esparso para navegação segura ou gráficos 3D convincentes. Este artigo apresenta uma nova forma de “preencher” a informação de profundidade faltante usando imagens de câmera, produzindo mapas de distância detalhados que preservam as bordas dos objetos sem se confundir com texturas de superfície.
Por que preencher distâncias é tão difícil
A complementação de profundidade tenta transformar um conjunto muito esparso de amostras de distância em uma imagem de profundidade completa, usando uma foto colorida comum como guia. Sistemas anteriores frequentemente misturam informações de cor e profundidade diretamente dentro de uma rede neural. Esse atalho cria dois problemas opostos. Por um lado, a rede pode copiar padrões de tijolo, listras ou logotipos da imagem colorida para o mapa de profundidade como saliências e reentrâncias falsas. Por outro, métodos que suavizam agressivamente esses detalhes falsos tendem a borrar os limites verdadeiros entre objetos, como o contorno de um carro ou uma placa de rua. Equilibrar detalhe e confiabilidade tornou-se um obstáculo central para aplicações no mundo real.
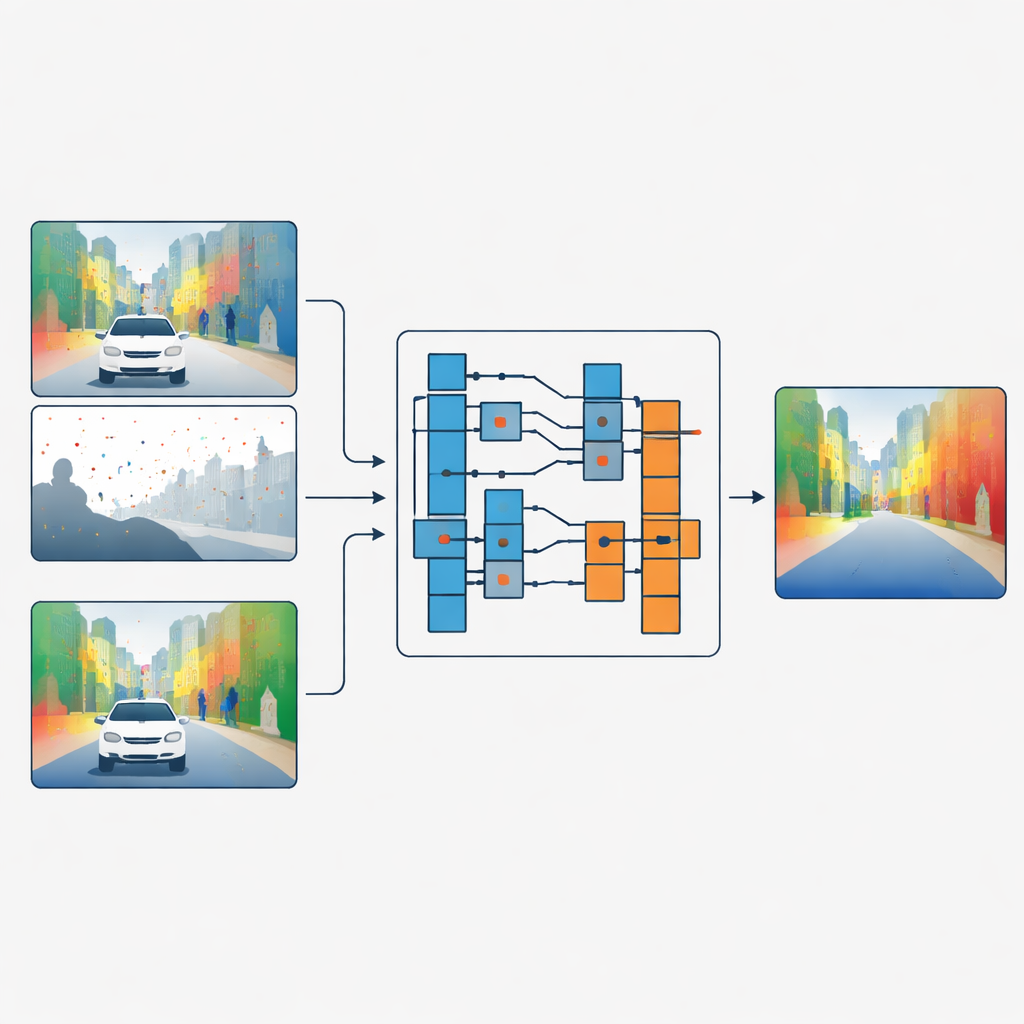
Separando formas de detalhes de superfície
Os autores propõem uma estratégia diferente: em vez de misturar as características de cor e profundidade, eles deixam a imagem colorida decidir como os dados de profundidade devem ser filtrados, sem nunca mesclar os dois diretamente. A rede deles primeiro processa a profundidade esparsa e a cor em ramos separados. Em estágios-chave da rede, um módulo chamado Módulo de Refinamento Guiado (“Guided Refinement Module”) observa as características de cor através de uma lente de frequência. Usando uma transformada wavelet, ele separa a informação de cor em partes suaves de baixa frequência que capturam formas amplas e regiões de variação lenta, e partes de alta frequência que capturam bordas nítidas e texturas finas como folhas ou caixilhos de janela.
Filtros inteligentes que se adaptam a cada região
Uma vez que a informação de cor é dividida dessa forma, o método aprende uma família de pequenos filtros de imagem de diferentes tamanhos. Para cada região e cada banda de frequência, a rede escolhe qual tamanho de filtro aplicar e com que intensidade aplicá-lo. Filtros grandes são favorecidos em áreas suaves onde a profundidade deve variar gradualmente, ajudando a espalhar medidas confiáveis por regiões vazias. Filtros pequenos são usados perto de bordas fortes, de modo que o mapa de profundidade mantenha contornos claros em vez de espalhar um objeto sobre outro. Crucialmente, os filtros sempre combinam apenas valores de profundidade com outros valores de profundidade; os dados de cor apenas orientam qual filtro usar e onde. Essa conexão “operador, mas não valor” atua como um gargalo que impede que texturas de superfície da imagem colorida sejam impressas como profundidade falsa.
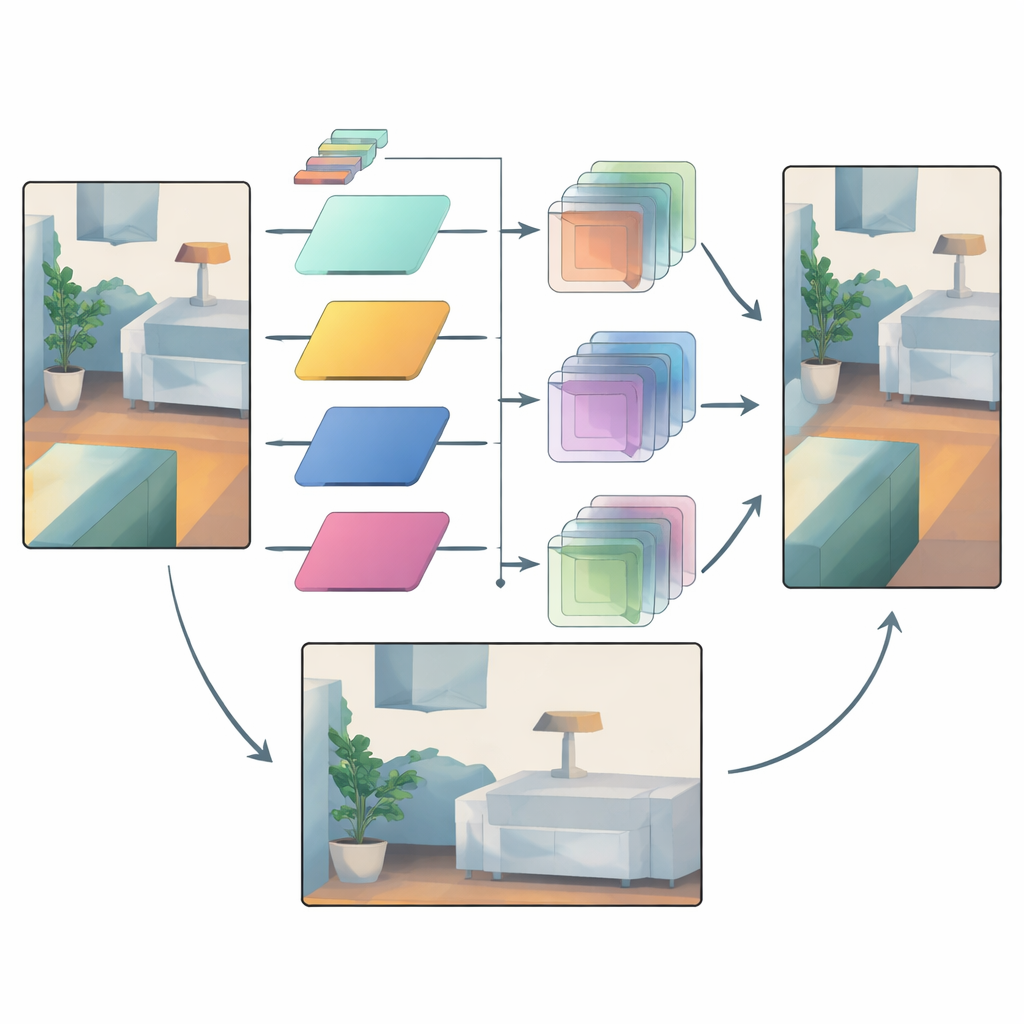
Confiando em sinais confiáveis enquanto doma a incerteza
Mesmo com filtragem adaptativa, algumas áreas permanecem incertas — pense em objetos distantes vistos através de chuva, ou regiões onde muito poucos pontos de laser estão disponíveis. Para lidar com isso, a rede usa um segundo mecanismo que compara características intermediárias de profundidade de estágios iniciais e finais. As características iniciais estão mais próximas da entrada bruta do sensor e carregam uma noção de quais regiões são confiáveis. O modelo constrói máscaras de atenção que destacam onde a estrutura é confiável e quais canais de característica importam mais. Essas máscaras então reforçam suavemente detalhes confiáveis e atenuam mudanças suspeitas introduzidas mais tarde no pipeline, reduzindo o excesso de suavização e artefatos indesejados.
Ganho comprovado em estradas e ambientes internos
A equipe testa sua abordagem em dois benchmarks padrão: KITTI para cenas externas de direção e NYUv2 para cômodos internos. Seu método consistentemente iguala ou supera concorrentes de ponta em múltiplas medidas de erro, usando menos parâmetros do que alguns dos modelos mais pesados. Ele se sai particularmente bem quando as leituras de profundidade são extremamente esparsas, como ao simular sensores a laser mais baratos com apenas algumas linhas de varredura ou pontos. Comparações visuais mostram estruturas mais finas, como postes de iluminação, preservadas com nitidez, e carros ou móveis separados mais claramente de seus fundos, com muito menos ondulações falsas originadas da cópia de textura.
O que isso significa para a visão 3D no mundo real
Ao repensar como imagens de câmera guiam a complementação de profundidade, este trabalho mostra que é possível manter as pistas úteis da cor — como bordas e o layout geral — sem herdar suas texturas enganosas. A chave é usar análise de frequência e interações cuidadosamente restritas para que a cor decida como os valores de profundidade são combinados, não quais devem ser os valores. Como resultado, robôs, veículos e dispositivos de AR podem obter mapas de profundidade mais densos e nítidos a partir dos mesmos sensores esparsos, aproximando navegação mais segura e experiências 3D mais estáveis da realidade cotidiana.
Citação: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Palavras-chave: complementação de profundidade, lidar, percepção 3D, visão computacional, condução autônoma