Clear Sky Science · de
RGB-konditionierte Verfeinerung im Frequenzbereich für die Tiefenkompletion von spärlich zu dicht
Scharfere digitale Tiefe für Alltagsmaschinen
Autonome Fahrzeuge, Lieferroboter und Augmented-Reality-Headsets müssen wissen, wie weit Objekte entfernt sind, nicht nur wie sie aussehen. Moderne Lasersensoren liefern oft nur vereinzelte Distanzpunkte, was für sichere Navigation oder überzeugende 3D-Grafik zu spärlich ist. Dieses Paper stellt eine neue Methode vor, um die fehlenden Tiefeninformationen mithilfe von Kamerabildern „aufzufüllen“ und detaillierte Entfernungszuschreibungen zu erzeugen, die Objektkanten scharf halten, ohne durch Oberflächentexturen getäuscht zu werden.
Warum das Auffüllen von Entfernungen so schwer ist
Tiefenkompletion versucht, aus einer sehr spärlichen Menge von Distanzmessungen ein vollständiges Tiefenbild zu erzeugen, wobei ein gewöhnliches Farbfoto als Leitbild dient. Frühere Systeme vermischten oft Farb- und Tiefeninformationen direkt innerhalb eines neuronalen Netzes. Diese Abkürzung erzeugt zwei entgegengesetzte Probleme. Einerseits kann das Netz Ziegelmuster, Streifen oder Logos aus dem Farbbild in die Tiefenkarte kopieren und dort als falsche Unebenheiten erscheinen lassen. Andererseits neigen Methoden, die solche falschen Details aggressiv glätten, dazu, echte Objektgrenzen zu verwischen, etwa die Kontur eines Autos oder eines Straßenschilds. Das richtige Gleichgewicht zwischen Detailtreue und Zuverlässigkeit ist zu einem zentralen Hindernis für Anwendungen in der Praxis geworden.
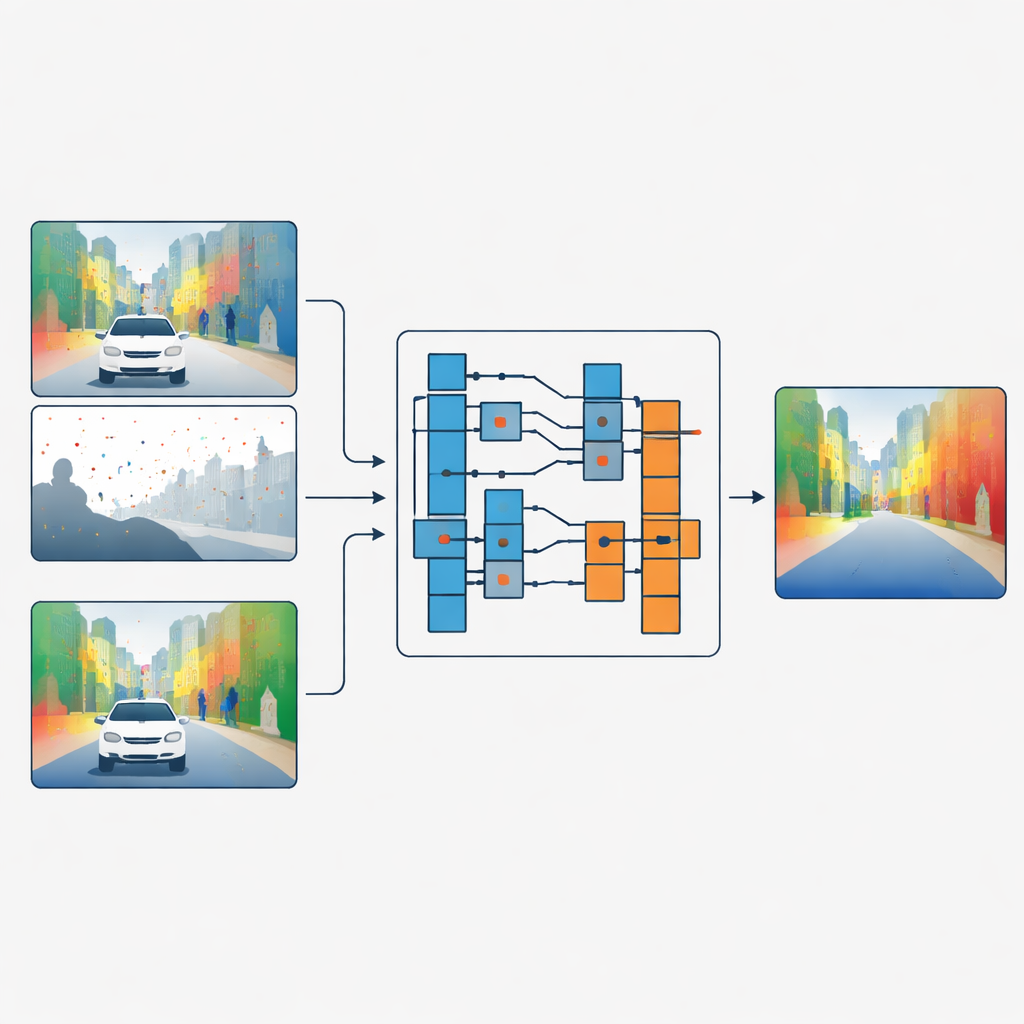
Formen von Oberflächendetails trennen
Die Autor:innen schlagen eine andere Strategie vor: Anstatt Farb- und Tiefenfeatures zu vermischen, lassen sie das Farbbild lediglich entscheiden, wie die Tiefendaten gefiltert werden sollen, ohne die beiden direkt zu verschränken. Ihr Netzwerk verarbeitet die spärliche Tiefe und die Farbe zunächst in getrennten Zweigen. In wichtigen Netzwerkphasen betrachtet ein Modul namens Guided Refinement Module die Farbfeatures durch eine Frequenzlinse. Mittels Wavelet-Transformation teilt es die Farbinformation in glatte, niederfrequente Anteile, die grobe Formen und langsam veränderliche Regionen erfassen, und hochfrequente Anteile, die scharfe Kanten und feine Texturen wie Blätter oder Fensterrahmen abbilden.
Schlaue Filter, die sich an jede Region anpassen
Sobald die Farbinformation auf diese Weise aufgespalten ist, lernt die Methode eine Familie kleiner Bildfilter unterschiedlicher Größe. Für jede Region und jede Frequenzbande wählt das Netzwerk, wie groß ein Filter sein soll und wie stark er angewendet wird. Große Filter werden in glatten Bereichen bevorzugt, wo die Tiefe allmählich wechseln sollte, und helfen dabei, verlässliche Messungen über leere Regionen zu verbreiten. Kleine Filter kommen in der Nähe starker Kanten zum Einsatz, sodass die Tiefenkarte klare Grenzen bewahrt, anstatt ein Objekt in ein anderes zu verwischen. Entscheidenderweise kombinieren die Filter stets nur Tiefenwerte mit anderen Tiefenwerten; die Farbdaten steuern lediglich, welcher Filter wo verwendet wird. Diese „Operator, aber nicht Wert“-Verbindung wirkt als Engpass, der verhindert, dass Oberflächentexturen aus dem Farbbild als falsche Tiefeninformationen übernommen werden.
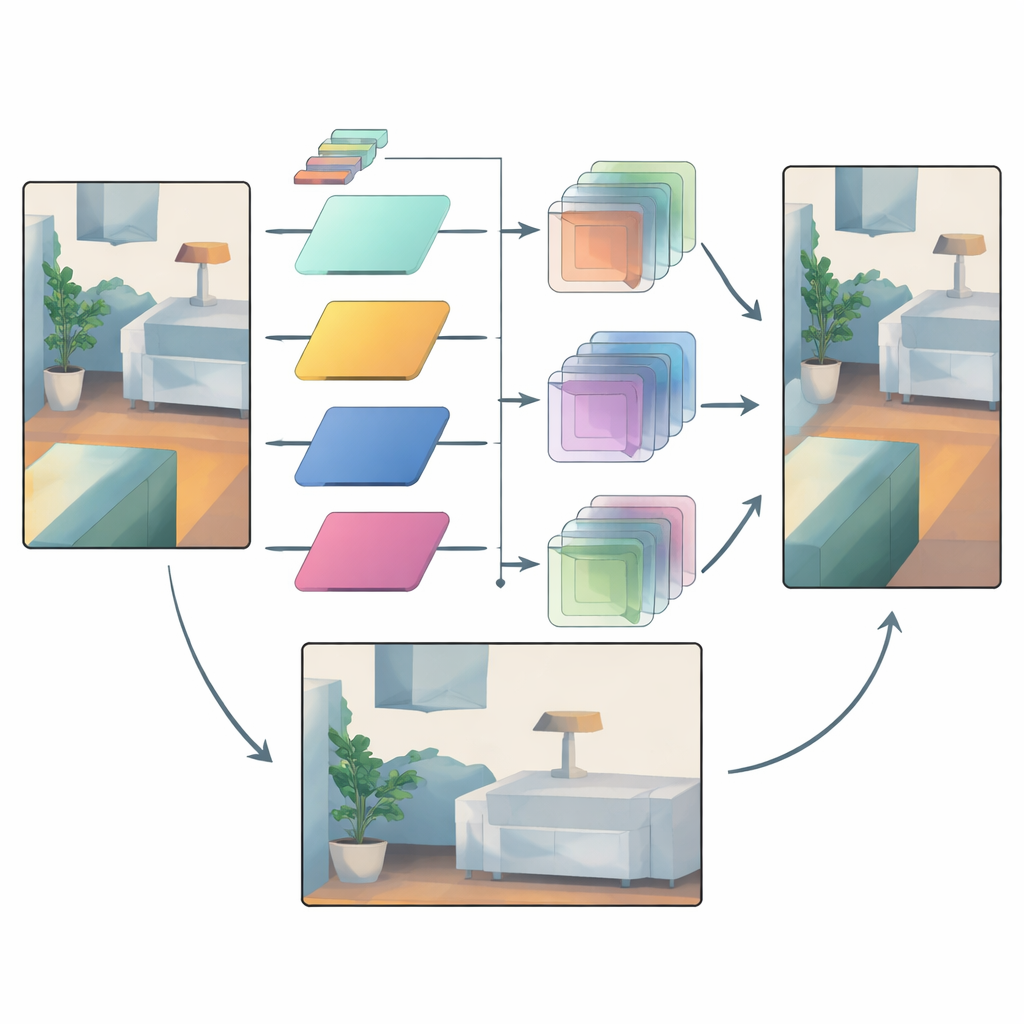
Verlässliche Signale nutzen und Unsicherheit zähmen
Selbst mit adaptiver Filterung bleiben manche Bereiche unsicher – denken Sie an entfernte Objekte, die durch Regen gesehen werden, oder Regionen, in denen nur sehr wenige Laserpunkte verfügbar sind. Um damit umzugehen, nutzt das Netzwerk einen zweiten Mechanismus, der zwischengeschaltete Tiefenfeatures aus frühen und späten Stadien vergleicht. Frühe Features stehen näher am Rohsensoreingang und tragen eine Einschätzung darüber, welche Regionen vertrauenswürdig sind. Das Modell erstellt Aufmerksamkeitsmasken, die hervorheben, wo Struktur verlässlich ist und welche Feature-Kanäle am wichtigsten sind. Diese Masken verstärken dann behutsam vertrauenswürdige Details und dämpfen verdächtige Änderungen, die später in der Pipeline eingeführt werden, wodurch Überschmierungen und Fehlartefakte reduziert werden.
Erprobte Verbesserungen für Straßen und Innenräume
Das Team testet seinen Ansatz auf zwei gängigen Benchmarks: KITTI für Außenaufnahmen im Straßenverkehr und NYUv2 für Innenraumszenen. Ihre Methode erreicht durchweg vergleichbare oder bessere Ergebnisse als führende Konkurrenten über mehrere Fehlermetriken hinweg, und das bei weniger Parametern als manche der schwergewichtigsten Modelle. Sie zeigt besonders starke Leistungen, wenn Tiefenmessungen extrem spärlich sind, etwa beim Simulieren günstigerer Lasersensoren mit nur wenigen Scanlinien oder Punkten. Visuelle Vergleiche zeigen dünnere Strukturen wie Laternenpfähle klar erhalten und Autos oder Möbel stärker vom Hintergrund getrennt, mit deutlich weniger falschen Wellen durch Textureinfluss.
Was das für die reale 3D-Wahrnehmung bedeutet
Indem sie neu überdenken, wie Kamerabilder die Tiefenkompletion leiten, zeigt diese Arbeit, dass es möglich ist, hilfreiche Hinweise aus der Farbe – etwa Kanten und die grobe Anordnung – zu nutzen, ohne deren irreführende Texturen zu übernehmen. Der Schlüssel liegt in der Frequenzanalyse und sorgfältig eingeschränkten Interaktionen, sodass die Farbe entscheidet, wie Tiefenwerte kombiniert werden, nicht welche Werte sie haben sollen. In der Folge können Roboter, Fahrzeuge und AR-Geräte dichtere, schärfere Tiefenkarten aus denselben spärlichen Sensoren erhalten, was sicherere Navigation und stabilere 3D-Erlebnisse näher an den Alltag bringt.
Zitation: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Schlüsselwörter: Tiefenkompletion, Lidar, 3D-Wahrnehmung, Computer Vision, Autonomes Fahren