Clear Sky Science · sv
RGB-betingad förfining i frekvensdomänen för täthet från gles till tät djupkomplettering
Skarpare digitalt djup för vardagliga maskiner
Självkörande bilar, leveransrobotar och augmented reality-headsets behöver alla förstå hur långt bort saker är, inte bara hur de ser ut. Moderna lasersensorer ger bara enstaka avståndspunkter, vilket är för glest för säker navigation eller trovärdig 3D-grafik. Denna artikel presenterar ett nytt sätt att "fylla i" den saknade djupinformationen med hjälp av kamerabilder, och skapar detaljerade avståndskartor som behåller skarpa objektskanter utan att luras av ytors texturer.
Varför det är så svårt att fylla i avstånd
Djupkomplettering försöker förvandla en mycket gles uppsättning avståndsprover till en fullständig djupbild med hjälp av ett vanligt färgfoto som vägledning. Tidigare system blandar ofta färg- och djupinformation direkt i ett neuralt nätverk. Den genvägen skapar två motsatta problem. Å ena sidan kan nätverket kopiera tegelmönster, ränder eller logotyper från färgbilden in i djupkartan som falska gupp och fördjupningar. Å andra sidan tenderar metoder som aggressivt avlägsnar dessa falska detaljer att sudda ut de verkliga gränserna mellan objekt, som konturen av en bil eller en vägskylt. Att balansera detaljrikedom och tillförlitlighet har blivit ett centralt hinder för tillämpningar i verkliga miljöer.
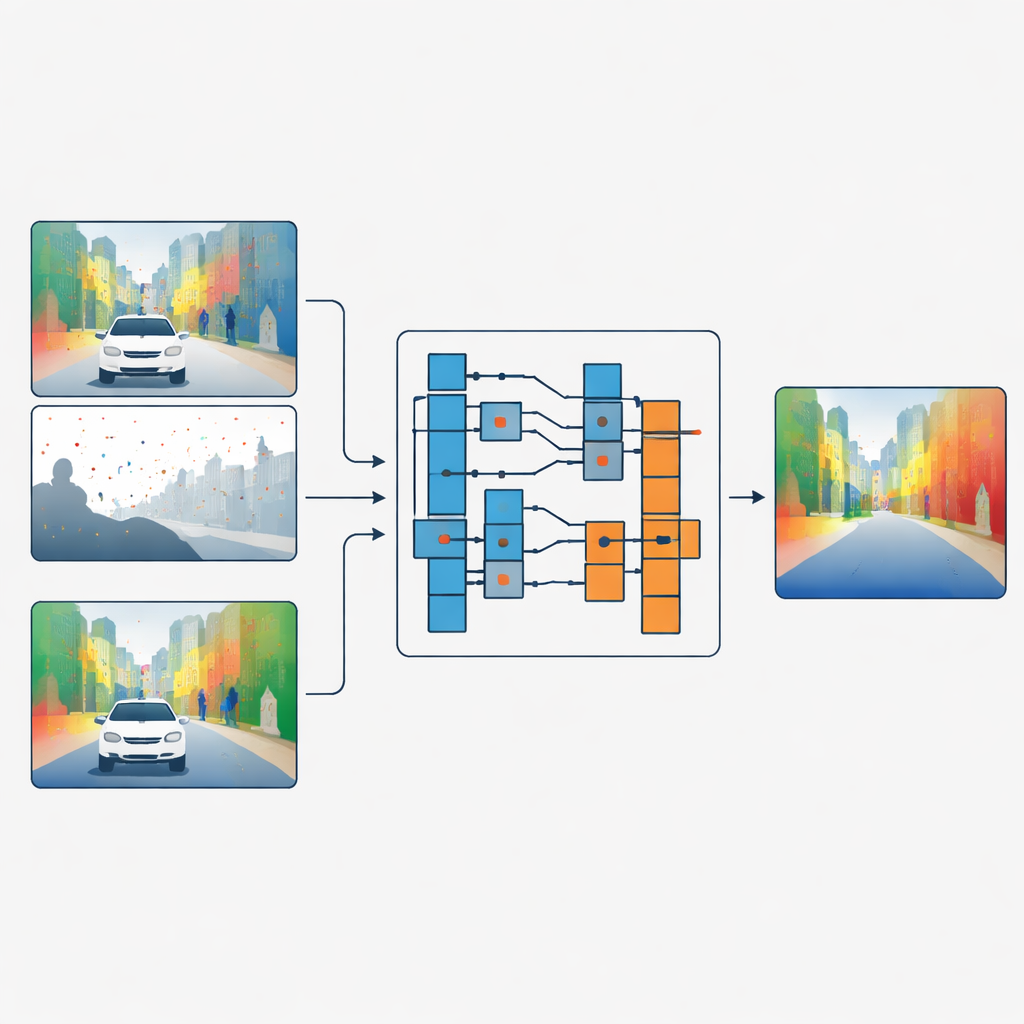
Separera former från ytstruktur
Författarna föreslår en annan strategi: istället för att blanda färg- och djupfunktioner låter de färgbilden bestämma hur djupdata ska filtreras, utan att de två någonsin blandas direkt. Deras nätverk bearbetar först glesa djup- och färgdata i separata grenar. I viktiga steg i nätverket tittar en modul kallad Guided Refinement Module på färgegenskaperna genom en frekvenslins. Med hjälp av en vågtransform delar den upp färginformationen i mjuka, lågfreventa delar som fångar breda former och långsamt föränderliga regioner, och högfrekventa delar som fångar skarpa kanter och fina texturer som löv eller fönsterkarmar.
Smarta filter som anpassar sig till varje region
När färginformationen har delats på detta sätt lär sig metoden en familj av små bildfilter i olika storlekar. För varje region och varje frekvensband väljer nätverket hur stort filter som ska användas och hur starkt det ska tillämpas. Stora filter föredras i jämna områden där djupet ska förändras gradvis och hjälper till att sprida tillförlitliga mätningar över tomma regioner. Små filter används nära starka kanter så att djupkartan behåller tydliga gränser istället för att blanda ihop ett objekt med ett annat. Avgörande är att filtren alltid kombinerar endast djupvärden med andra djupvärden; färgdata styr bara vilket filter som ska användas och var. Denna "operator men inte värde"-koppling fungerar som en flaskhals som förhindrar att ytors texturer i färgbilden avbildas som falskt djup.
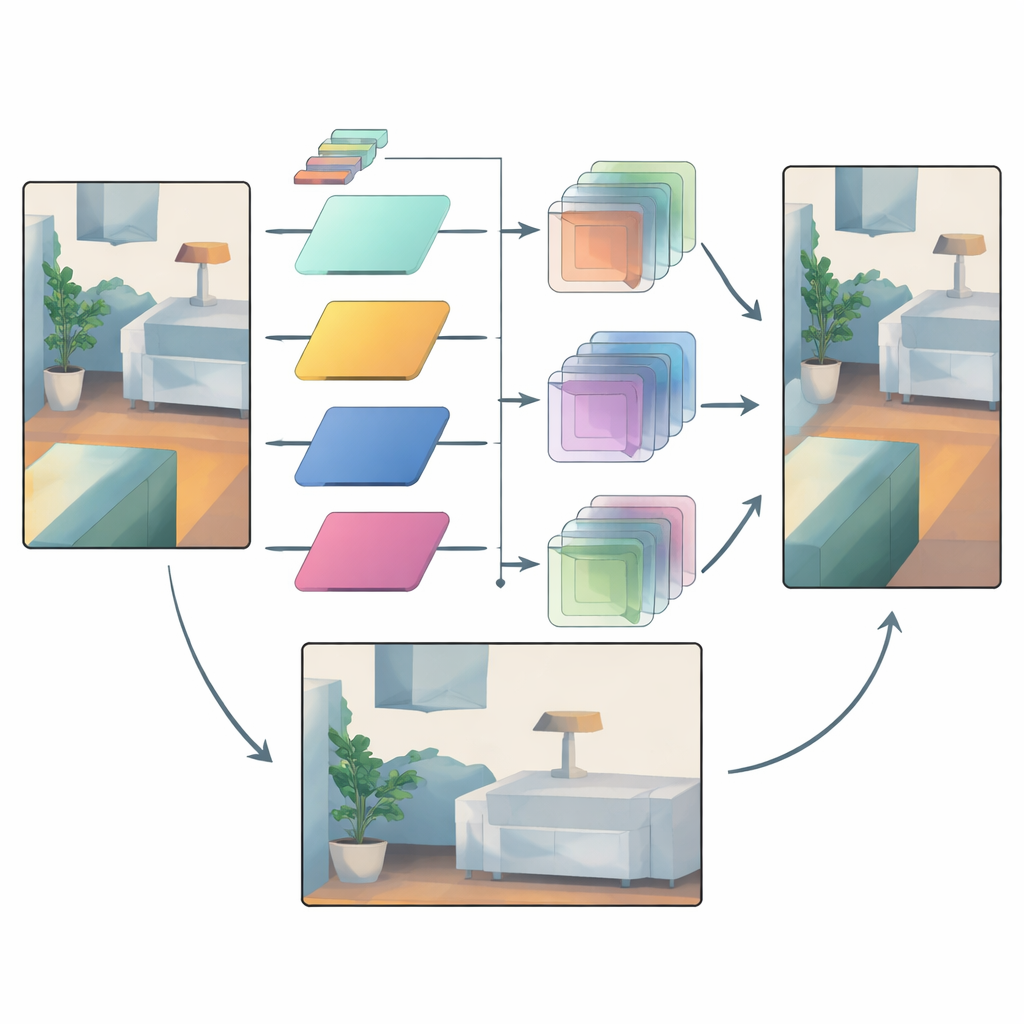
Att lita på tillförlitliga signaler samtidigt som osäkerhet temmas
Även med adaptiv filtrering förblir vissa områden osäkra—tänk på avlägsna objekt sedda genom regn, eller regioner där väldigt få laserpunkter finns tillgängliga. För att hantera detta använder nätverket en andra mekanism som jämför mellanliggande djupfunktioner från tidiga och sena steg. Tidiga funktioner ligger närmare råsensorinmatningen och bär en känsla av vilka regioner som är pålitliga. Modellen bygger upp attentionsmasker som framhäver var strukturen är tillförlitlig och vilka funktionskanaler som är viktigast. Dessa masker förstärker sedan försiktigt säkra detaljer och dämpar misstänkta förändringar som introducerats senare i kedjan, vilket minskar överutjämning och slumpmässiga artefakter.
Påvisade vinster på vägar och inomhus
Teamet testar sitt tillvägagångssätt på två standardbenchmarks: KITTI för utomhusscener vid körning och NYUv2 för inomhusrum. Deras metod matchar eller överträffar konsekvent ledande konkurrenter över flera felmått, samtidigt som den använder färre parametrar än några av de tyngsta modellerna. Den presterar särskilt bra när djupavläsningarna är extremt glesa, såsom vid simulering av billigare lasersensorer med bara ett fåtal sveplinjer eller punkter. Visuella jämförelser visar tunnare strukturer, som gatlyktor, bevarade klart, och bilar eller möbler separerade tydligare från sina bakgrunder, med betydligt färre falska vågor från texturkopia.
Vad detta innebär för 3D-seende i verkliga världen
Genom att ompröva hur kamerabilder vägleder djupkomplettering visar detta arbete att det är möjligt att behålla de användbara ledtrådarna från färg—som kanter och övergripande layout—utan att ärva vilseledande texturer. Nyckeln är att använda frekvensanalys och noggrant begränsade interaktioner så att färg bestämmer hur djupvärden kombineras, inte vilka värden som ska vara. Som ett resultat kan robotar, fordon och AR-enheter få tätare, skarpare djupkartor från samma glesa sensorer, vilket för dem närmare säkrare navigation och stabilare 3D-upplevelser i vardagen.
Citering: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Nyckelord: djupkomplettering, lidar, 3D-förståelse, datorseende, självkörande fordon