Clear Sky Science · es
Refinamiento en el dominio de la frecuencia condicionado por RGB para la finalización de profundidad de escaso a denso
Profundidad digital más nítida para máquinas cotidianas
Los coches autónomos, los robots de reparto y las gafas de realidad aumentada necesitan saber a qué distancia están las cosas, no solo cómo se ven. Los sensores láser modernos proporcionan solo un puñado de puntos de distancia, lo que resulta demasiado escaso para una navegación segura o gráficos 3D convincentes. Este trabajo presenta una nueva forma de “rellenar” la información de profundidad faltante usando imágenes de cámara, produciendo mapas de distancia detallados que mantienen los bordes de los objetos nítidos sin dejarse engañar por las texturas de las superficies.
Por qué es tan difícil rellenar la distancia
La finalización de profundidad intenta convertir un conjunto muy escaso de muestras de distancia en una imagen de profundidad completa, usando una foto a color ordinaria como guía. Los sistemas anteriores a menudo mezclan información de color y profundidad directamente dentro de una red neuronal. Ese atajo crea dos problemas opuestos. Por un lado, la red puede copiar patrones de ladrillo, franjas o logotipos de la imagen en color al mapa de profundidad como protuberancias y huecos falsos. Por otro, los métodos que suavizan agresivamente esos falsos detalles tienden a difuminar los límites reales entre objetos, como el contorno de un coche o una señal de tráfico. Equilibrar detalle y fiabilidad se ha convertido en un obstáculo central para aplicaciones del mundo real.
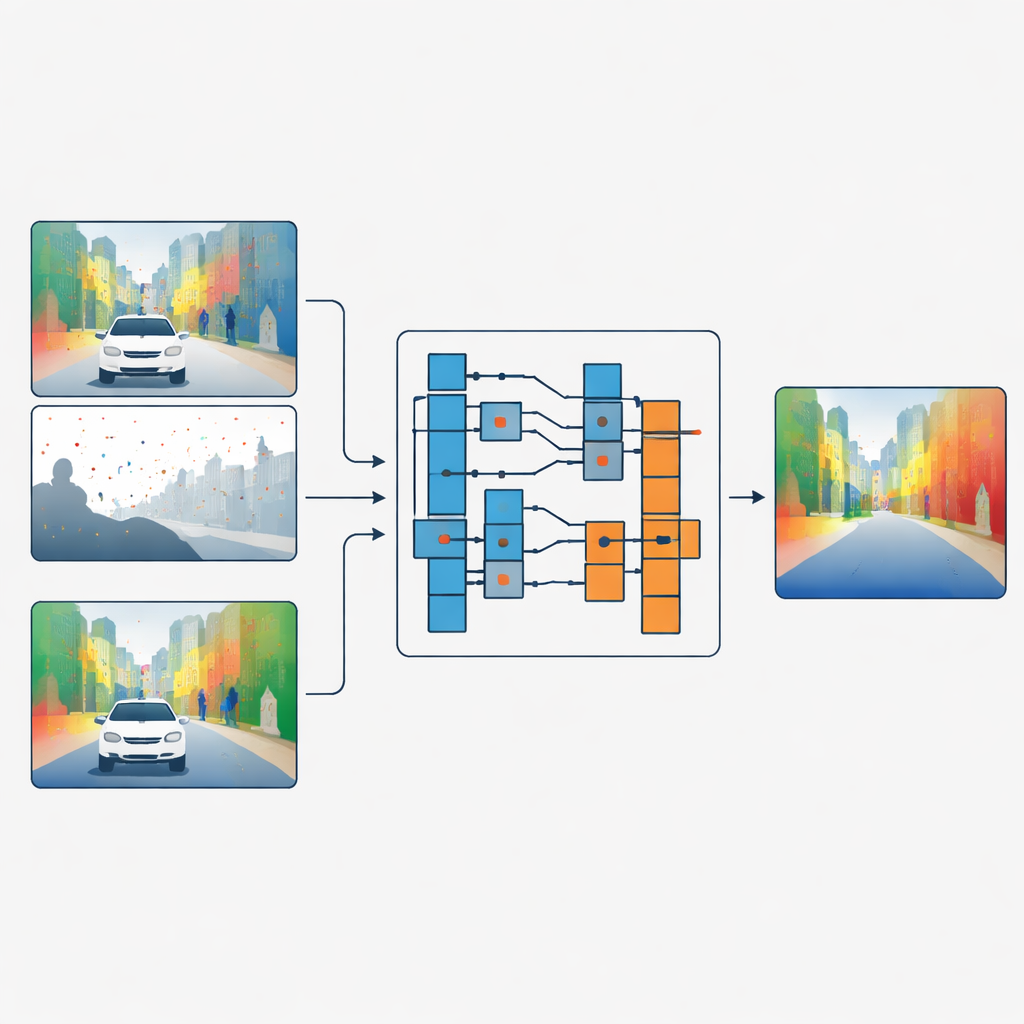
Separar las formas del detalle superficial
Los autores proponen una estrategia distinta: en lugar de fusionar características de color y profundidad, permiten que la imagen en color decida cómo debe filtrarse la información de profundidad, sin mezclar nunca ambas directamente. Su red procesa primero la profundidad dispersa y el color en ramas separadas. En etapas clave de la red, un módulo llamado Guided Refinement Module observa las características de color a través de una lente de frecuencia. Usando una transformada wavelet, divide la información de color en partes de baja frecuencia y suaves que capturan formas amplias y regiones de cambio lento, y en partes de alta frecuencia que capturan bordes nítidos y texturas finas como hojas o marcos de ventanas.
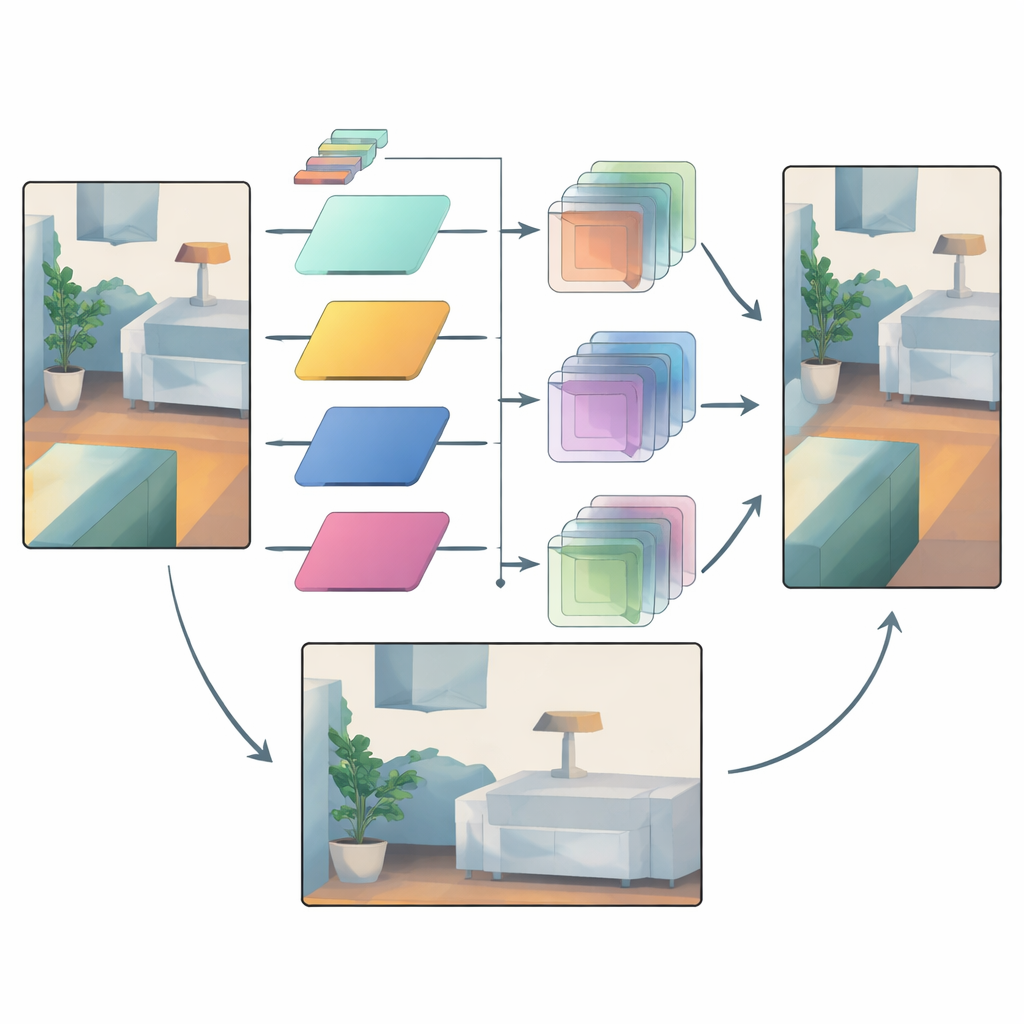
Filtros inteligentes que se adaptan a cada región
Una vez que la información de color se divide de esta manera, el método aprende una familia de pequeños filtros de imagen de distintos tamaños. Para cada región y cada banda de frecuencia, la red elige qué tamaño de filtro aplicar y con qué intensidad. Los filtros grandes se favorecen en áreas suaves donde la profundidad debe cambiar gradualmente, ayudando a propagar mediciones fiables a través de regiones vacías. Los filtros pequeños se usan cerca de bordes fuertes, de modo que el mapa de profundidad conserva fronteras claras en lugar de difuminar un objeto con otro. Crucialmente, los filtros siempre combinan solo valores de profundidad con otros valores de profundidad; los datos de color únicamente orientan qué filtro usar y dónde. Esta conexión de “operador pero no valor” actúa como un cuello de botella que evita que las texturas superficiales de la imagen en color se graben como profundidad falsa.
Confiar en señales fiables mientras se domina la incertidumbre
Incluso con filtrado adaptativo, algunas áreas siguen siendo inciertas —piense en objetos lejanos vistos a través de la lluvia, o regiones donde hay muy pocos puntos láser disponibles—. Para manejar esto, la red usa un segundo mecanismo que compara características intermedias de profundidad de etapas tempranas y tardías. Las características tempranas están más cercanas a la entrada cruda del sensor y transmiten una idea de qué regiones son dignas de confianza. El modelo construye máscaras de atención que resaltan dónde la estructura es fiable y qué canales de características importan más. Estas máscaras luego refuerzan suavemente los detalles confiables y atenúan los cambios sospechosos introducidos más adelante en la tubería, reduciendo el sobre-suavizado y los artefactos esporádicos.
Ganancias demostradas en carretera y en interiores
El equipo evalúa su enfoque en dos bancos de pruebas estándar: KITTI para escenas de conducción al aire libre y NYUv2 para habitaciones interiores. Su método iguala o supera consistentemente a los competidores líderes en varias medidas de error, mientras usa menos parámetros que algunos de los modelos más pesados. Funciona especialmente bien cuando las lecturas de profundidad son extremadamente escasas, como al simular sensores láser más económicos con solo unas pocas líneas de escaneo o puntos. Las comparaciones visuales muestran estructuras más delgadas, como postes de luz, preservadas con claridad, y coches o muebles separados más claramente de sus fondos, con muchas menos ondas falsas por copia de texturas.
Qué significa esto para la visión 3D en el mundo real
Al replantear cómo las imágenes de cámara guían la finalización de profundidad, este trabajo demuestra que es posible conservar las pistas útiles del color —como los bordes y la disposición general— sin heredar sus texturas engañosas. La clave es usar análisis en frecuencia e interacciones cuidadosamente restringidas para que el color decida cómo se combinan los valores de profundidad, no cuáles deben ser esos valores. Como resultado, robots, vehículos y dispositivos de RA pueden obtener mapas de profundidad más densos y nítidos a partir de los mismos sensores escasos, acercando una navegación más segura y experiencias 3D más estables a la realidad cotidiana.
Cita: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Palabras clave: completado de profundidad, lidar, percepción 3D, visión por computador, conducción autónoma