Clear Sky Science · fr
Affinement en domaine fréquentiel conditionné par RVB pour la complétion de profondeur de sparse à dense
Profondeur numérique plus nette pour les machines du quotidien
Les voitures autonomes, les robots de livraison et les casques de réalité augmentée doivent tous estimer les distances, pas seulement reconnaître l'apparence des objets. Les capteurs laser modernes fournissent seulement une poignée de points de distance, trop peu pour une navigation sûre ou des rendus 3D convaincants. Cet article présente une nouvelle méthode pour « combler » les informations de profondeur manquantes à l’aide d’images caméra, produisant des cartes de distance détaillées qui conservent la netteté des contours d’objets sans se laisser tromper par les textures de surface.
Pourquoi il est si difficile de remplir les distances
La complétion de profondeur tente de transformer un ensemble très clairsemé d’échantillons de distance en une image de profondeur complète, en se servant d’une photo couleur ordinaire comme guide. Les systèmes antérieurs mêlent souvent directement les informations de couleur et de profondeur au sein d’un réseau neuronal. Ce raccourci crée deux problèmes opposés. D’une part, le réseau peut copier des motifs de briques, des rayures ou des logos de l’image couleur dans la carte de profondeur sous forme de bosses et creux factices. D’autre part, les méthodes qui lissent agressivement ces faux détails ont tendance à estomper les véritables limites entre les objets, comme le contour d’une voiture ou d’un panneau. Trouver l’équilibre entre détail et fiabilité est devenu un obstacle central pour les applications réelles.
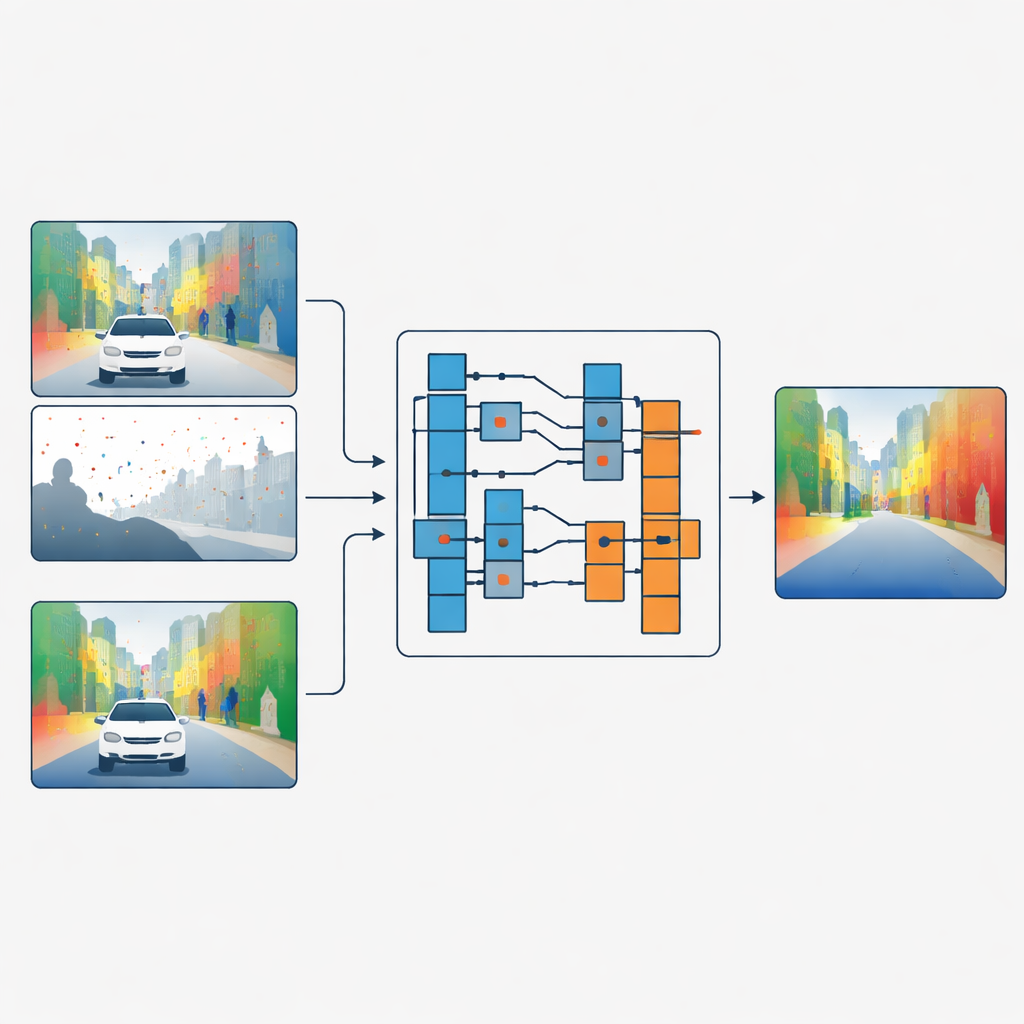
Séparer les formes du détail de surface
Les auteurs proposent une stratégie différente : au lieu de fusionner les caractéristiques de couleur et de profondeur, ils laissent l’image couleur décider comment les données de profondeur doivent être filtrées, sans jamais mélanger les deux directement. Leur réseau traite d’abord la profondeur sparse et la couleur dans des branches séparées. À des étapes clés du réseau, un module appelé Guided Refinement Module examine les caractéristiques de couleur à travers une lentille fréquentielle. À l’aide d’une transformée en ondelettes, il divise l’information couleur en parties lisses, basse fréquence, qui capturent les formes générales et les régions à variation lente, et en parties haute fréquence qui saisissent les bords nets et les textures fines comme les feuilles ou les encadrements de fenêtres.
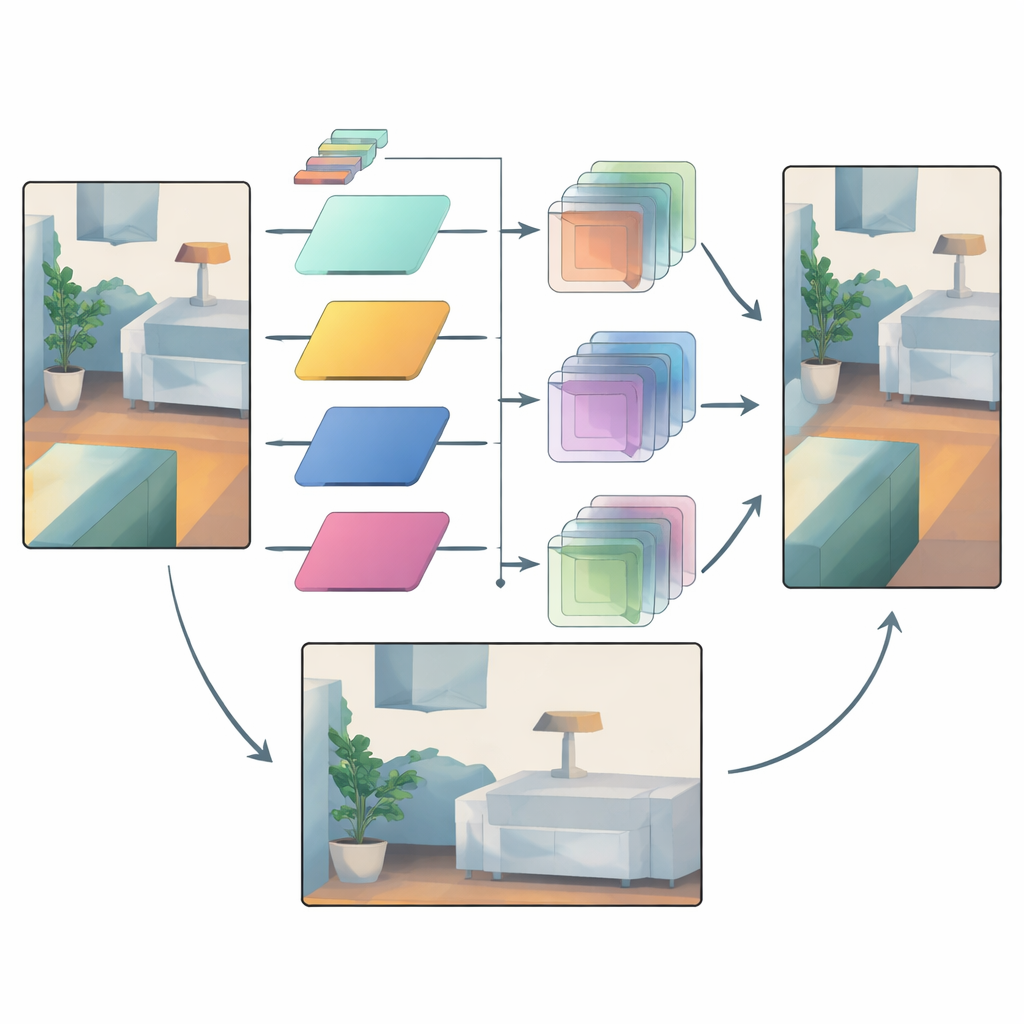
Filtres intelligents qui s’adaptent à chaque région
Une fois l’information couleur ainsi décomposée, la méthode apprend une famille de petits filtres d’image de différentes tailles. Pour chaque région et chaque bande fréquentielle, le réseau choisit la taille du filtre à appliquer et l’intensité de son application. Les gros filtres sont privilégiés dans les zones lisses où la profondeur doit varier progressivement, aidant à diffuser des mesures fiables dans les régions vides. Les petits filtres sont utilisés près des bords marqués, de sorte que la carte de profondeur conserve des frontières nettes au lieu de fusionner un objet avec un autre. Crucialement, les filtres combinent toujours uniquement des valeurs de profondeur entre elles ; les données couleur servent uniquement à orienter quel filtre utiliser et où. Cette connexion « opérateur mais pas valeur » agit comme un goulot d’étranglement qui empêche les textures de surface de l’image couleur d’être imprimées comme des profondeurs factices.
Faire confiance aux signaux fiables tout en maîtrisant l’incertitude
Même avec un filtrage adaptatif, certaines zones restent incertaines — pensez aux objets lointains vus sous la pluie, ou aux régions où très peu de points laser sont disponibles. Pour gérer cela, le réseau utilise un second mécanisme qui compare des caractéristiques de profondeur intermédiaires issues des premières et des dernières étapes. Les caractéristiques précoces sont plus proches de l’entrée capteur brute et portent une idée des régions fiables. Le modèle construit des masques d’attention qui mettent en évidence où la structure est fiable et quels canaux de caractéristiques sont les plus importants. Ces masques renforcent ensuite légèrement les détails confiants et atténuent les changements suspects introduits plus tard dans le pipeline, réduisant la sur-lissage et les artéfacts errants.
Gains prouvés sur la route et en intérieur
L’équipe teste son approche sur deux benchmarks standard : KITTI pour les scènes extérieures de conduite et NYUv2 pour les pièces intérieures. Leur méthode égalise ou dépasse systématiquement les principaux concurrents sur plusieurs mesures d’erreur, tout en utilisant moins de paramètres que certains des modèles les plus lourds. Elle performe particulièrement bien lorsque les relevés de profondeur sont extrêmement clairsemés, comme lorsqu’on simule des capteurs laser moins coûteux avec seulement quelques lignes de balayage ou points. Les comparaisons visuelles montrent des structures fines, comme des poteaux d’éclairage, conservées proprement, et des voitures ou du mobilier mieux détachés de leur arrière-plan, avec beaucoup moins d’ondulations fausses résultant de la copie de textures.
Ce que cela signifie pour la vision 3D dans le monde réel
En repensant la façon dont les images caméra guident la complétion de profondeur, ce travail montre qu’il est possible de conserver les indices utiles de la couleur — tels que les bords et l’organisation générale — sans hériter de leurs textures trompeuses. La clé est d’utiliser l’analyse fréquentielle et des interactions soigneusement contraintes pour que la couleur décide comment les valeurs de profondeur sont combinées, et non quelles doivent être les valeurs. En conséquence, les robots, véhicules et dispositifs AR peuvent obtenir des cartes de profondeur plus denses et plus nettes à partir des mêmes capteurs clairsemés, rapprochant une navigation plus sûre et des expériences 3D plus stables de la réalité quotidienne.
Citation: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Mots-clés: complétion de profondeur, lidar, perception 3D, vision par ordinateur, conduite autonome