Clear Sky Science · it
Raffinamento nel dominio delle frequenze condizionato su RGB per la completazione della profondità da sparso a denso
Profondità digitale più nitida per le macchine di tutti i giorni
Auto a guida autonoma, robot per le consegne e visori per realtà aumentata devono tutti capire quanto distano gli oggetti, non solo come appaiono. I sensori laser moderni forniscono solo un’irragionevole trama di punti di distanza, troppo scarsa per una navigazione sicura o per grafica 3D credibile. Questo articolo presenta un nuovo modo per «riempire» le informazioni di profondità mancanti usando immagini della camera, producendo mappe di distanza dettagliate che mantengono i contorni degli oggetti netti senza lasciarsi ingannare dalle texture delle superfici.
Perché è così difficile colmare le distanze
La completazione della profondità cerca di trasformare un insieme molto sparso di campioni di distanza in un’immagine di profondità completa, usando una fotografia a colori ordinaria come guida. I sistemi precedenti spesso mescolano direttamente informazioni di colore e profondità all’interno di una rete neurale. Questo stratagemma crea due problemi opposti. Da una parte, la rete può copiare motivi di mattoni, strisce o loghi dall’immagine a colori nella mappa di profondità come finti rilievi o avvallamenti. Dall’altra, i metodi che attenuano aggressivamente questi falsi dettagli tendono a sfocare i veri confini tra gli oggetti, come il profilo di un’auto o di un cartello stradale. Bilanciare dettaglio e affidabilità è diventato un ostacolo centrale per le applicazioni nel mondo reale.
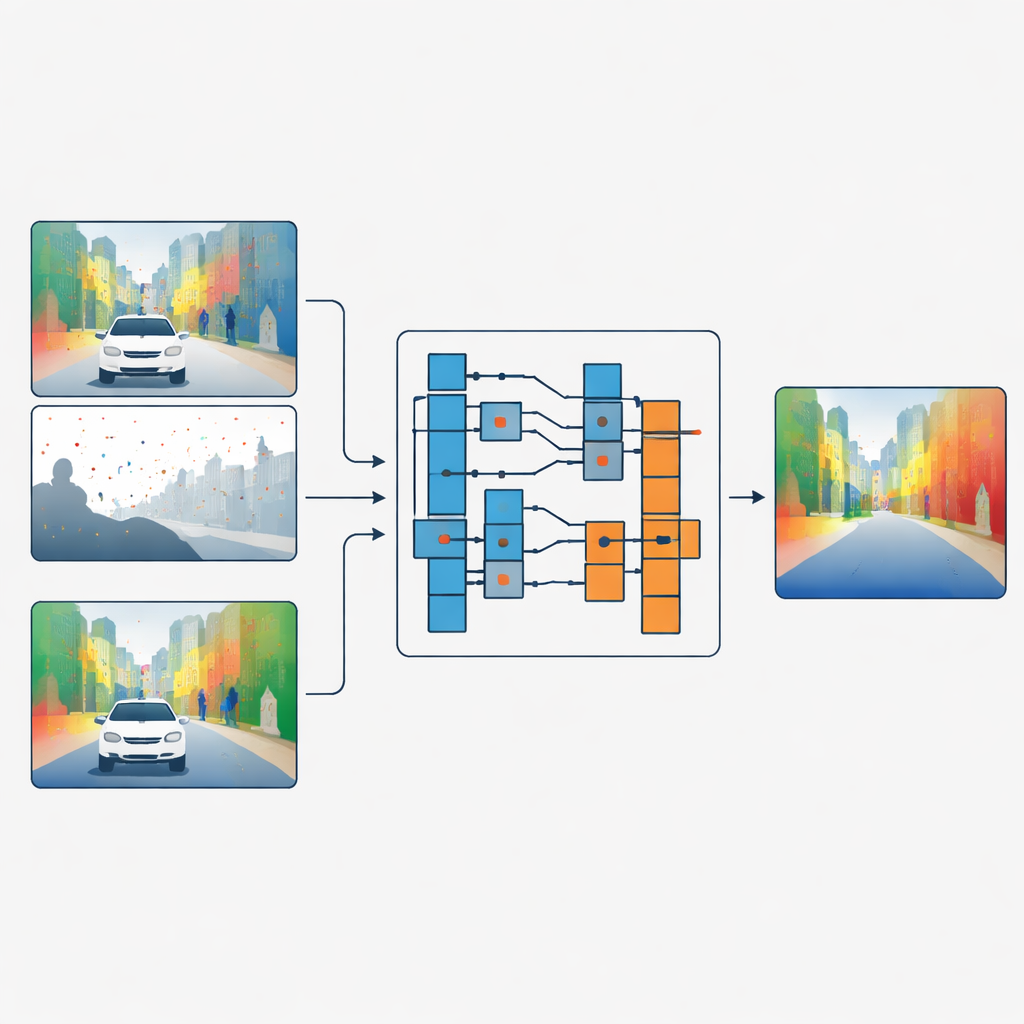
Separare le forme dai dettagli di superficie
Gli autori propongono una strategia diversa: invece di fondere caratteristiche di colore e profondità, lasciano che l’immagine a colori decida come i dati di profondità debbano essere filtrati, senza mai mescolare direttamente i due. La loro rete elabora per prima la profondità sparsa e il colore in rami separati. In fasi chiave della rete, un modulo chiamato Guided Refinement Module osserva le caratteristiche cromatiche attraverso una lente di frequenza. Utilizzando una trasformata wavelet, divide l’informazione di colore in parti a bassa frequenza, lisce, che catturano le forme ampie e le regioni a variazione lenta, e parti ad alta frequenza che catturano bordi netti e texture fini come foglie o telai di finestre.
Filtri intelligenti che si adattano a ogni regione
Una volta che l’informazione di colore è stata suddivisa in questo modo, il metodo impara una famiglia di piccoli filtri di immagine di diverse dimensioni. Per ogni regione e per ciascuna banda di frequenza, la rete sceglie quanto grande applicare il filtro e con quale intensità applicarlo. I filtri grandi sono preferiti nelle aree lisce dove la profondità dovrebbe variare gradualmente, aiutando a diffondere misure affidabili attraverso regioni vuote. I filtri piccoli sono usati vicino a bordi forti, in modo che la mappa di profondità mantenga contorni chiari invece di sfumare un oggetto nell’altro. Fondamentalmente, i filtri combinano sempre solo valori di profondità con altri valori di profondità; i dati di colore si limitano a dirigere quale filtro usare e dove. Questa connessione di tipo «operatore ma non valore» agisce come un collo di bottiglia che impedisce alle texture delle superfici nell’immagine a colori di essere impresse come profondità false.
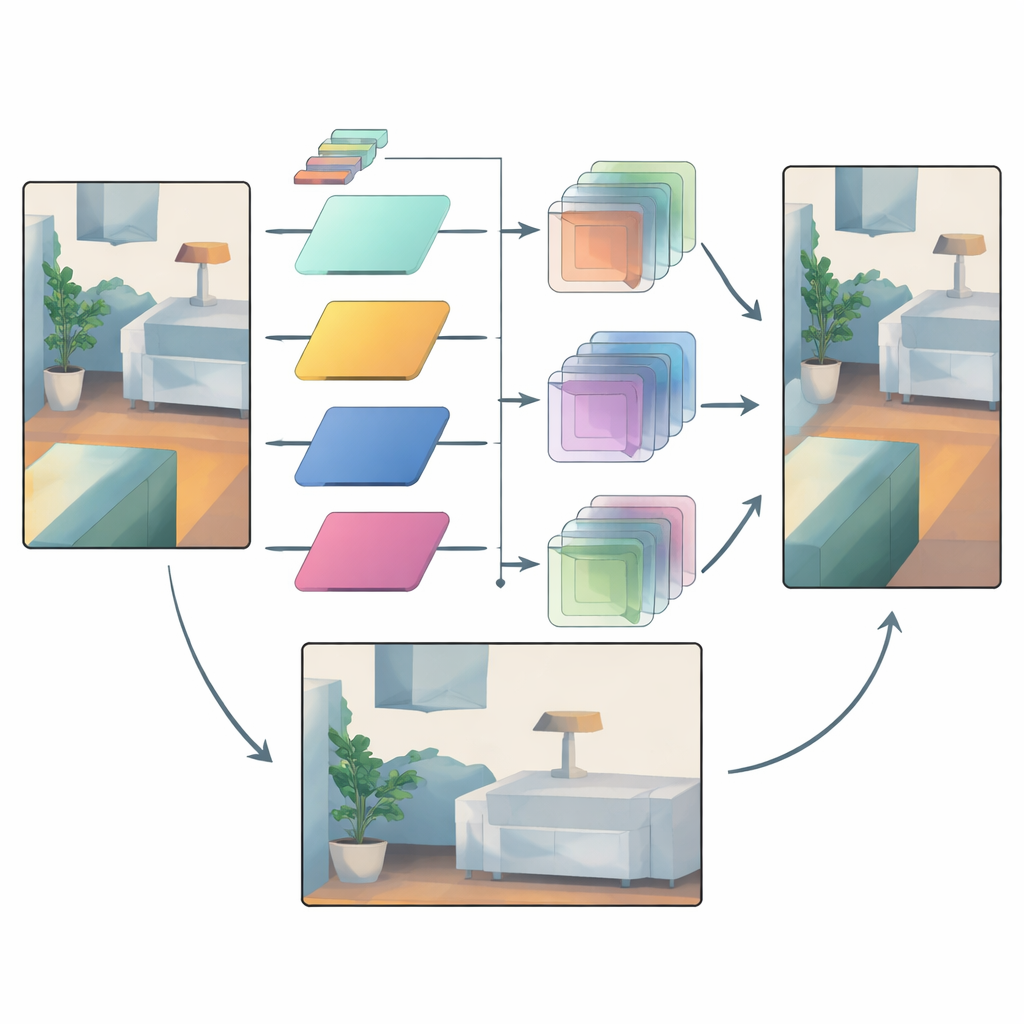
Fidarsi dei segnali affidabili mentre si domano le incertezze
Anche con il filtraggio adattivo, alcune aree restano incerte — pensate a oggetti lontani visti sotto la pioggia, o a regioni dove sono disponibili pochissimi punti laser. Per gestire questo, la rete utilizza un secondo meccanismo che confronta caratteristiche di profondità intermedie provenienti da stadi precoci e tardivi. Le caratteristiche precoci sono più vicine all’ingresso grezzo del sensore e portano un’indicazione di quali regioni sono degne di fiducia. Il modello costruisce maschere di attenzione che evidenziano dove la struttura è affidabile e quali canali di feature hanno maggiore importanza. Queste maschere quindi potenziano delicatamente i dettagli affidabili e attenuano i cambiamenti sospetti introdotti più tardi nella pipeline, riducendo l’eccessiva levigatura e gli artefatti isolati.
Risultati dimostrati su strade e ambienti interni
Il team testa il loro approccio su due benchmark standard: KITTI per scene stradali esterne e NYUv2 per stanze interne. Il loro metodo eguaglia o supera costantemente i concorrenti principali su più misure di errore, pur usando meno parametri rispetto ad alcuni dei modelli più pesanti. Si comporta particolarmente bene quando le letture di profondità sono estremamente scarse, come quando si simulano sensori laser più economici con solo poche linee di scansione o punti. Le comparazioni visive mostrano strutture più sottili, come i pali della luce, conservate nitidamente, e automobili o mobili separati più chiaramente dallo sfondo, con molte meno increspature false dovute alla copia delle texture.
Cosa significa per la visione 3D nel mondo reale
Rivedendo il modo in cui le immagini delle camere guidano la completazione della profondità, questo lavoro dimostra che è possibile mantenere gli indizi utili dal colore — come i bordi e la disposizione generale — senza ereditare le loro texture ingannevoli. La chiave è usare l’analisi in frequenza e interazioni accuratamente vincolate in modo che il colore decida come i valori di profondità sono combinati, non quali debbano essere i valori. Di conseguenza, robot, veicoli e dispositivi AR possono ottenere mappe di profondità più dense e più nette dagli stessi sensori sparsi, avvicinando una navigazione più sicura e esperienze 3D più stabili alla realtà di tutti i giorni.
Citazione: Wang, H., Tang, Z., Pawara, P. et al. RGB-conditioned frequency domain refinement for sparse-to-dense depth completion. Sci Rep 16, 10757 (2026). https://doi.org/10.1038/s41598-026-45432-1
Parole chiave: completamento della profondità, lidar, percezione 3D, visione artificiale, guida autonoma