Clear Sky Science · zh
使用基于Transformer的医学影像进行胃肠疾病检测以实现可持续医疗
为何肠道影像需要更智能的帮助
腹痛、出血或无法解释的体重下降有时可能表明消化道内存在严重问题,从长期炎症到癌症不等。医生依赖小型摄像装置,例如结肠镜或可吞服胶囊,来发现异常区域。但每位患者产生的数千张图像使得这一工作既枯燥又容易错过细微的预警信号。本研究探讨了一种能够以显著精度解读这些图像的新型人工智能(AI),旨在帮助更早发现胃肠疾病,同时减轻人手紧张的医疗系统负担。
在肠道影像中看见更多细节
消化道可能遭受多种病况的影响,包括溃疡性结肠炎、食管炎以及可能发展为结直肠癌的息肉。这些问题常在肠道内表面以颜色或质地的细微变化表现出来。基于卷积神经网络的传统计算工具已经在医疗图像中帮助标记可疑区域,但当模式复杂或分布在图像各处时,这类工具会遇到困难。因此,现有系统在训练数据有限或不同诊断类型分布不均时,容易错过疾病的微妙迹象。
一种新的数字“读片器”
本研究测试了一种较新的AI结构,被称为视觉Transformer(Vision Transformer),具体采用名为ViT-B16的模型来对胃肠影像进行分类。与逐块刚性扫描图像的方式不同,该模型将每张图像切成小块并同时学习这些小块之间的关系。作者构建了一个平衡的1万张内镜图像集,分为四组:正常组织、溃疡性结肠炎、息肉和食管炎。他们仔细筛除了低质量或标注错误的图像,将图像统一为标准尺寸,并通过翻转、旋转和亮度调整等增强手段扩充数据,以使模型对真实世界的变化更具有鲁棒性。 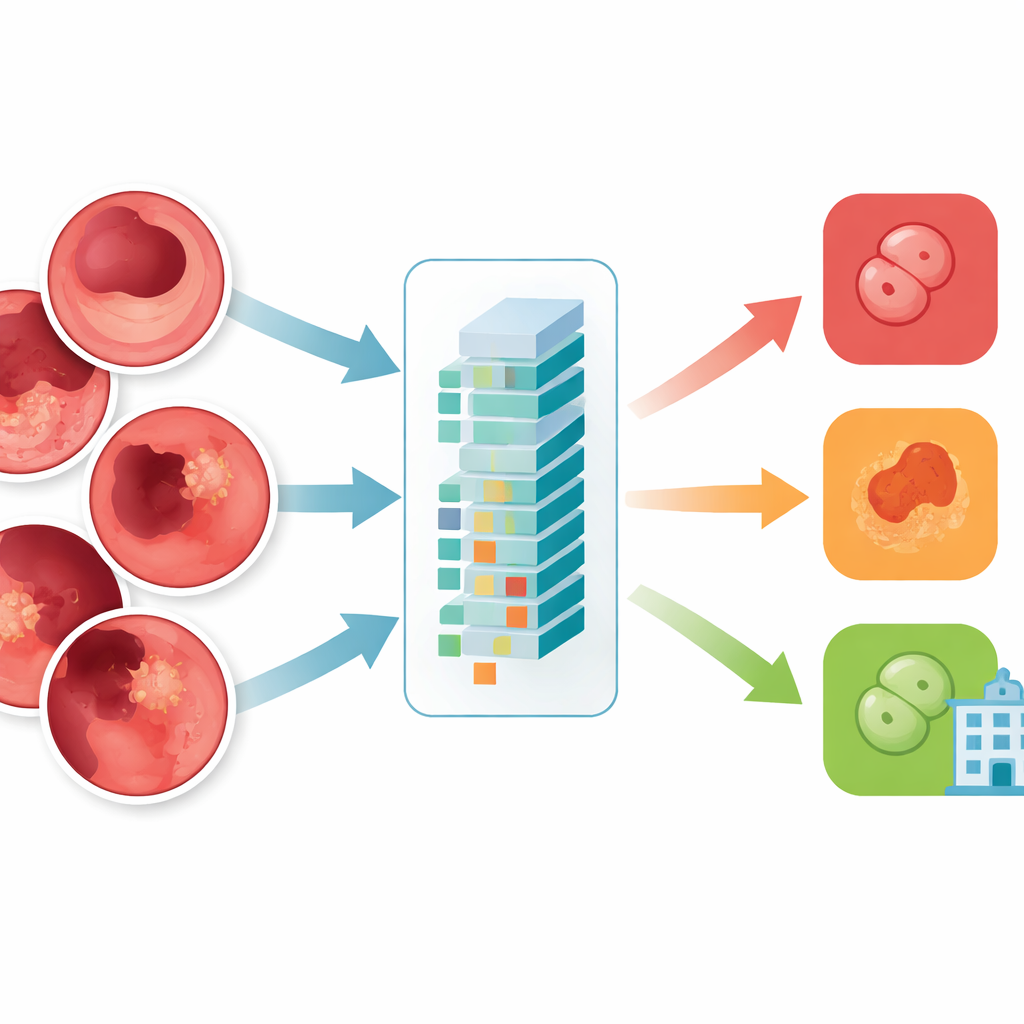
AI如何学习与决策
在视觉Transformer内部,每个微小的图像块被转换为数值“标记(token)”,多层注意力模块学习哪些图像块应当相互影响更强。这使系统能够在单幅肠道图像中权衡远处但相关的区域,类似临床医生在视野中连贯关联不同模式的方式。团队对预训练的ViT-B16模型进行了微调,采用自适应优化和交叉验证等现代训练技巧,然后将其与广泛使用的深度学习架构(如EfficientNet)以及多网络集成方案进行了比较。他们还使用了可解释性工具生成热图,突出显示AI在判断为发炎区域或息肉时关注的黏膜具体部位。
准确性、可信度与现实可及性
在平衡的测试集上,视觉Transformer达到了约99.5%的总体准确率,略优于最好的竞争模型,并远超早期方法。对于四个类别,每类的精确率、召回率和F1分数均徘徊在约99.4%,其区分不同疾病的曲线接近完美。千例测试中仅有少数图像被错误分类。当将训练好的系统用于在不同条件下收集的外部数据集时,准确率仍约为96.8%,显示出令人鼓舞的泛化能力。可视化热图显示模型的“注意力”集中在具有临床意义的区域——例如息肉表面或发炎斑块——增强了临床医生对AI并非关注无关背景而是查看正确部位的信心。 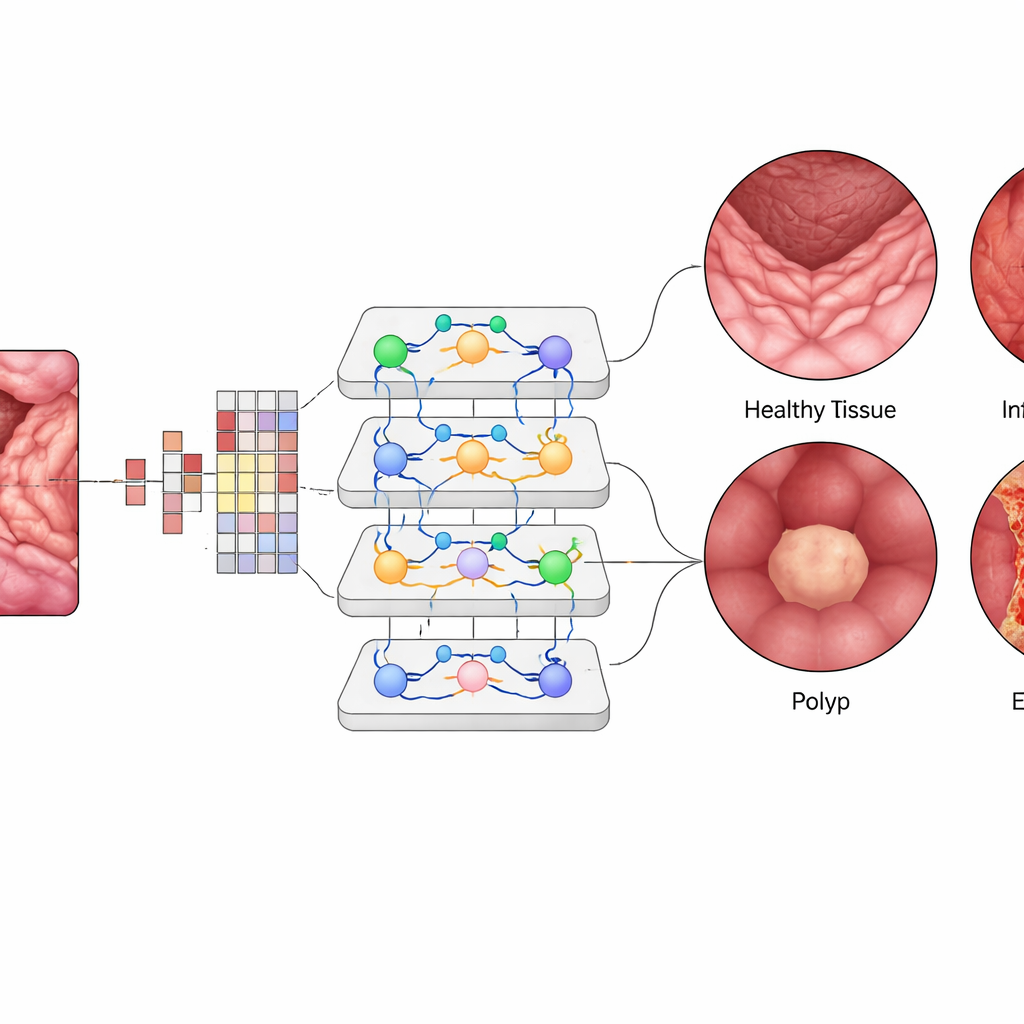
对患者与诊所的意义
研究结论认为,基于视觉Transformer的系统可以成为医生解读胃肠图像时的高效助手。通过可靠且快速地发现细微异常,它们有望实现更早的诊断、在医院间提供更一致的护理并减少漏检。由于该模型在常规图形硬件上具有足够的运行效率,它可以集成到常规筛查工作流程中,自动标记值得人工进一步审查的帧。尽管仍存在诸多挑战——例如在多家医院间验证性能、处理罕见疾病以及应对自动诊断相关的伦理问题——该工作表明AI“共同读片”可能很快成为更安全、更可持续消化系统医疗的实用工具。
引用: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
关键词: 胃肠成像, 视觉Transformer, 内镜人工智能, 息肉检测, 医学图像分类