Clear Sky Science · pl
Wykrywanie chorób gastroenterologicznych z użyciem transformera w obrazowaniu medycznym dla zrównoważonej opieki zdrowotnej
Dlaczego skany jelit potrzebują inteligentniejszej pomocy
Bóle brzucha, krwawienia lub niewyjaśniona utrata masy ciała mogą czasem wskazywać na poważne problemy w przewodzie pokarmowym, od przewlekłego zapalenia po nowotwory. Lekarze polegają na małych kamerach, takich jak te używane podczas kolonoskopii czy połykanych kapsułek, aby wykrywać nieprawidłowe obszary. Jednak tysiące obrazów na pacjenta sprawiają, że zadanie to jest męczące i łatwo przeoczyć subtelne oznaki choroby. W tym badaniu analizuje się nowy rodzaj sztucznej inteligencji (AI), która potrafi odczytywać te obrazy z niezwykłą dokładnością, pomagając wychwycić choroby gastroenterologiczne wcześniej i zmniejszając obciążenie przeciążonych systemów opieki zdrowotnej.
Więcej w obrazach jelit
Przewód pokarmowy może być dotknięty wieloma schorzeniami, w tym wrzodziejącym zapaleniem jelita grubego, zapaleniem przełyku czy polipami, które mogą przekształcić się w raka jelita grubego. Problemy te często objawiają się jako drobne zmiany koloru lub tekstury na wewnętrznej powierzchni jelita. Tradycyjne narzędzia komputerowe oparte na splotowych sieciach neuronowych (CNN) już pomagają wskazywać podejrzane miejsca na obrazach medycznych, ale mają trudności, gdy wzorce są złożone lub rozproszone po całym obrazie. W efekcie istniejące systemy mogą przeoczyć subtelne oznaki choroby, zwłaszcza gdy dane treningowe są ograniczone lub nierównomiernie rozłożone między różne typy rozpoznań.
Nowy rodzaj cyfrowego czytnika
W niniejszych badaniach testowano nowszą architekturę AI znaną jako Vision Transformer, w szczególności model o nazwie ViT-B16, do klasyfikacji obrazów gastroenterologicznych. Zamiast przeglądać zdjęcia kawałek po kawałku w sztywny sposób, model dzieli każdy obraz na małe łatki i jednocześnie uczy się wzajemnych relacji między tymi łatkami. Autorzy zbudowali zrównoważony zbiór 10 000 obrazów endoskopowych w czterech kategoriach: tkanka prawidłowa, wrzodziejące zapalenie jelita grubego, polipy i zapalenie przełyku. Starannie odfiltrowali obrazy niskiej jakości lub źle oznaczone, przeskalowali je do standardowego formatu i wzbogacili zestaw o obroty, odbicia i zmiany jasności, aby model był odporny na rzeczywiste wariacje. 
Jak AI się uczy i podejmuje decyzje
W obrębie Vision Transformera każda mała łatka obrazu zostaje przekształcona w numeryczny „token”, a warstwy modułów uwagi uczą się, które łatki powinny wzajemnie na siebie najsilniej wpływać. Pozwala to systemowi brać pod uwagę odległe, lecz powiązane rejony w pojedynczym obrazie jelita, podobnie jak klinicysta mentalnie łączy wzorce w całej ramce. Zespół dopracował (fine‑tuned) uprzednio wytrenowany model ViT-B16, stosując nowoczesne techniki treningowe, takie jak adaptacyjne optymalizatory i walidacja krzyżowa, a następnie porównał go z powszechnie używanymi architekturami głębokiego uczenia, takimi jak EfficientNet, oraz popularnymi zespołami kilku sieci. Użyto także narzędzi wyjaśniających, które tworzą mapy cieplne, wskazując dokładne rejony błony śluzowej, na które AI zwraca uwagę, gdy wykrywa obszar zapalny lub polip.
Dokładność, zaufanie i zasięg w praktyce
Vision Transformer osiągnął około 99,5% ogólnej dokładności na zrównoważonym zestawie testowym, nieco przewyższając najlepsze modele konkurencyjne i znacznie przewyższając wcześniejsze metody. Dla każdej z czterech klas precyzja, czułość i miary F1 oscylowały wokół 99,4%, a krzywe oceniające zdolność rozróżnienia chorób były bliskie ideału. Spośród tysiąca przypadków testowych tylko garstka obrazów została błędnie zaklasyfikowana. Gdy wytrenowany system zmierzono z zewnętrznym zbiorem danych zebranym w innych warunkach, nadal osiągał około 96,8% dokładności, co świadczy o obiecującej zdolności uogólniania. Mapy wizualizacyjne pokazały, że „uwaga” modelu skupia się na klinicznie istotnych obszarach — takich jak powierzchnia polipów czy zapalne fragmenty — co wzmacnia zaufanie klinicystów, że AI patrzy na właściwe miejsca, a nie na nieistotne tło. 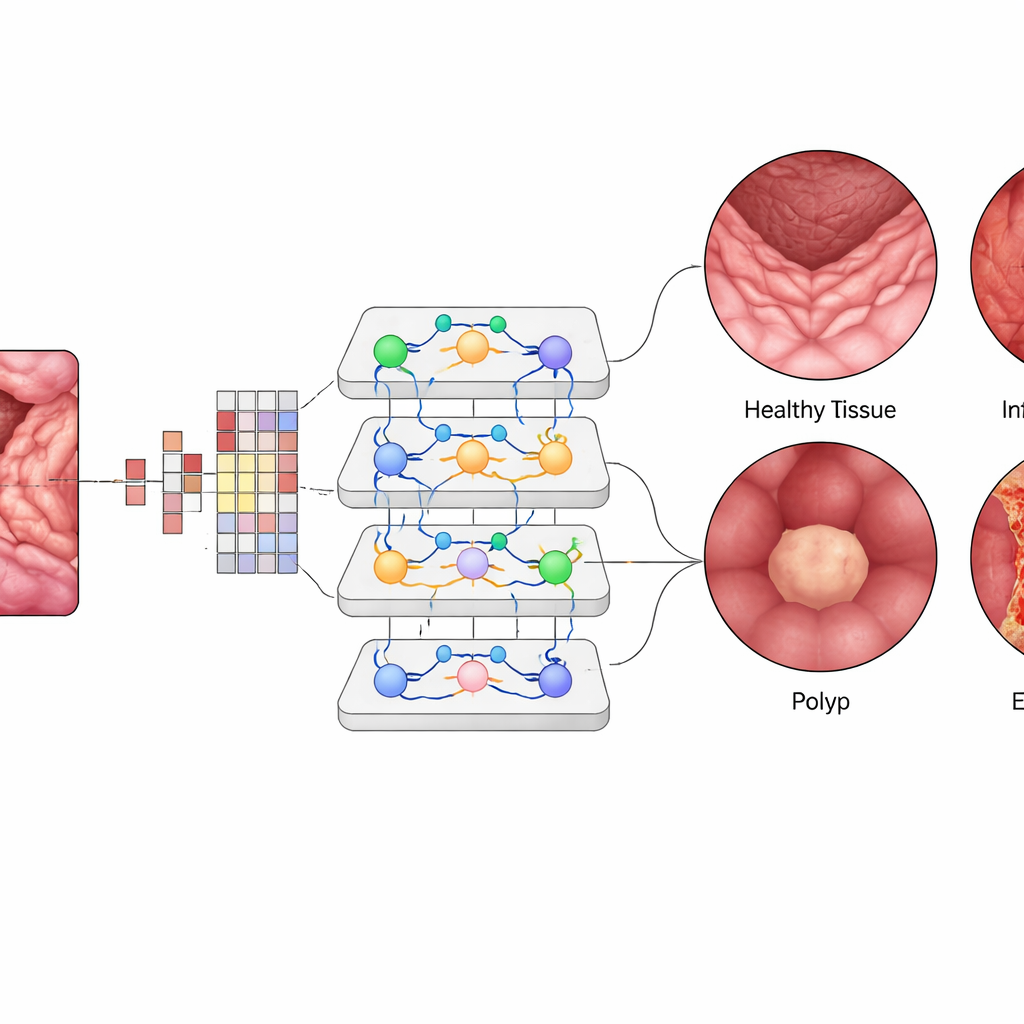
Co to oznacza dla pacjentów i placówek
Badanie dochodzi do wniosku, że systemy oparte na Vision Transformer mogą pełnić rolę wysoce kompetentnych asystentów dla lekarzy oceniających obrazy przewodu pokarmowego. Dzięki wiarygodnemu i szybkiemu wykrywaniu subtelnych nieprawidłowości mogą umożliwić wcześniejszą diagnozę, bardziej spójną opiekę między szpitalami oraz zmniejszenie liczby przeoczonych zmian. Ponieważ model jest na tyle wydajny, by działać na standardowym sprzęcie graficznym, można go zintegrować z rutynowymi procedurami przesiewowymi, automatycznie oznaczając ramki wymagające uważniejszej oceny przez człowieka. Choć pozostają wyzwania — takie jak weryfikacja działania w wielu ośrodkach, obsługa rzadkich chorób i kwestie etyczne związane z automatyczną diagnostyką — praca ta sugeruje, że „współczytające” AI mogą wkrótce stać się praktycznym narzędziem dla bezpieczniejszej, bardziej zrównoważonej opieki gastroenterologicznej.
Cytowanie: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Słowa kluczowe: obrazowanie przewodu pokarmowego, vision transformer, Sztuczna inteligencja w endoskopii, wykrywanie polipów, klasyfikacja obrazów medycznych