Clear Sky Science · tr
Sürdürülebilir sağlık hizmetleri için dönüştürücü tabanlı tıbbi görüntüleme ile gastroenterolojik hastalık tespiti
Bağırsak Taramalarının Daha Akıllı Yardıma İhtiyacı Neden Var
Mide ağrıları, kanama veya açıklanamayan kilo kaybı bazen sindirim kanalında uzun süreli iltihaptan kansere kadar ciddi sorunların işareti olabilir. Doktorlar, kolonoskopi veya yutulan kapsül gibi küçük kameralarla anormal bölgeleri tespit etmeye güvenirler. Ancak hasta başına binlerce görüntü bu görevi yorucu hale getirir ve ince uyarı işaretlerinin kaçırılmasını kolaylaştırır. Bu çalışma, bu görüntüleri olağanüstü doğrulukla okuyabilen yeni bir yapay zeka (YZ) türünü inceliyor; böylece gastroenterolojik hastalıkları daha erken yakalamaya yardımcı olurken aşırı yüklenmiş sağlık sistemlerinin yükünü azaltıyor.
Bağırsak Görüntülerinde Daha Fazlasını Görmek
Sindirim yolu; ülseratif kolit, özofajit ve kolorektal kansere dönüşebilecek polipler dahil olmak üzere birçok durumdan etkilenebilir. Bu sorunlar genellikle bağırsak iç yüzeyinde renk veya doku değişiklikleri şeklinde küçük işaretler olarak ortaya çıkar. Konvolüsyonel sinir ağlarına dayanan geleneksel bilgisayar araçları tıbbi görüntülerde şüpheli noktaları işaretlemeye yardımcı oldu, ancak desenler karmaşık veya görüntüye yayılmış olduğunda zorlanırlar. Sonuç olarak mevcut sistemler, özellikle eğitim verileri sınırlı veya farklı tanı türleri arasında dengesiz dağıtılmışsa, hastalığın ince işaretlerini kaçırabilir.
Yeni Tip Dijital Okuyucu
Bu araştırma, ViT‑B16 adlı bir model de dahil olmak üzere Vision Transformer olarak bilinen daha yeni bir YZ tasarımını gastroenterolojik görüntüleri sınıflandırmak için test ediyor. Bu model, görüntüleri parça parça katı bir şekilde taramak yerine her bir görüntüyü küçük yamalara böler ve tüm yamaların birbirleriyle nasıl ilişkili olduğunu aynı anda öğrenir. Yazarlar, normal doku, ülseratif kolit, polipler ve özofajit olmak üzere dört grupta dengelenmiş 10.000 endoskopi görüntüsünden oluşan bir koleksiyon oluşturdular. Düşük kaliteli veya yanlış etiketlenmiş görüntüleri dikkatle filtrelediler, standart bir formata yeniden boyutlandırdılar ve modeli gerçek dünya çeşitliliğine karşı dayanıklı kılmak için görüntüleri döndürme, çevirme ve parlaklık değişiklikleriyle artırdılar. 
YZ Nasıl Öğrenir ve Karar Verir
Vision Transformer içinde her küçük görüntü yaması sayısal bir "token"a dönüştürülür ve dikkat modüllerinden oluşan katmanlar hangi yamaların birbirini en güçlü şekilde etkilemesi gerektiğini öğrenir. Bu, sistemin bir klinisyenin çerçeve boyunca desenleri zihnen ilişkilendirmesine benzer şekilde uzak ama ilişkili bölgeleri tek bir görünümde ağırlıklandırmasına olanak tanır. Ekip, önceden eğitilmiş bir ViT‑B16 modelini uyarlayıcı optimizasyon ve çapraz doğrulama gibi modern eğitim teknikleriyle ince ayarladı ve onu EfficientNet gibi yaygın derin öğrenme mimarileri ve çoklu ağlardan oluşan popüler topluluklarla karşılaştırdı. Ayrıca, yapay zekanın iltihaplı bir bölgeyi veya bir polipi işaretlerken odaklandığı mukozal bölgeleri vurgulayan ısı haritaları üreten açıklama araçları kullandılar.
Doğruluk, Güven ve Gerçek Dünya Etkisi
Vision Transformer, dengelenmiş test setinde yaklaşık %99,5 genel doğruluğa ulaştı; bu, en iyi rakip modelleri hafifçe geride bırakıyor ve önceki yöntemleri çok aşıyordu. Dört sınıfın her biri için hassasiyet, duyarlılık ve F1 skoru yaklaşık %99,4 civarındaydı ve hastalıkları birbirinden ayırt etme yeteneğini ölçen eğriler neredeyse mükemmele yakındı. Bin test vakasından yalnızca birkaçı yanlış sınıflandırıldı. Eğitilmiş sistem farklı koşullar altında toplanmış bir dış veri kümesiyle sınandığında bile yaklaşık %96,8 doğruluk elde ederek cesaret verici bir genellenebilirlik gösterdi. Görselleştirme haritaları, modelin "dikkatini" polip yüzeyi veya iltihaplı yamalar gibi klinik açıdan anlamlı bölgelere yoğunlaştırdığını ortaya koydu; bu da YZ'nin ilgisiz arka plana değil doğru yerlere baktığı konusunda klinisyenlerin güvenini güçlendirdi. 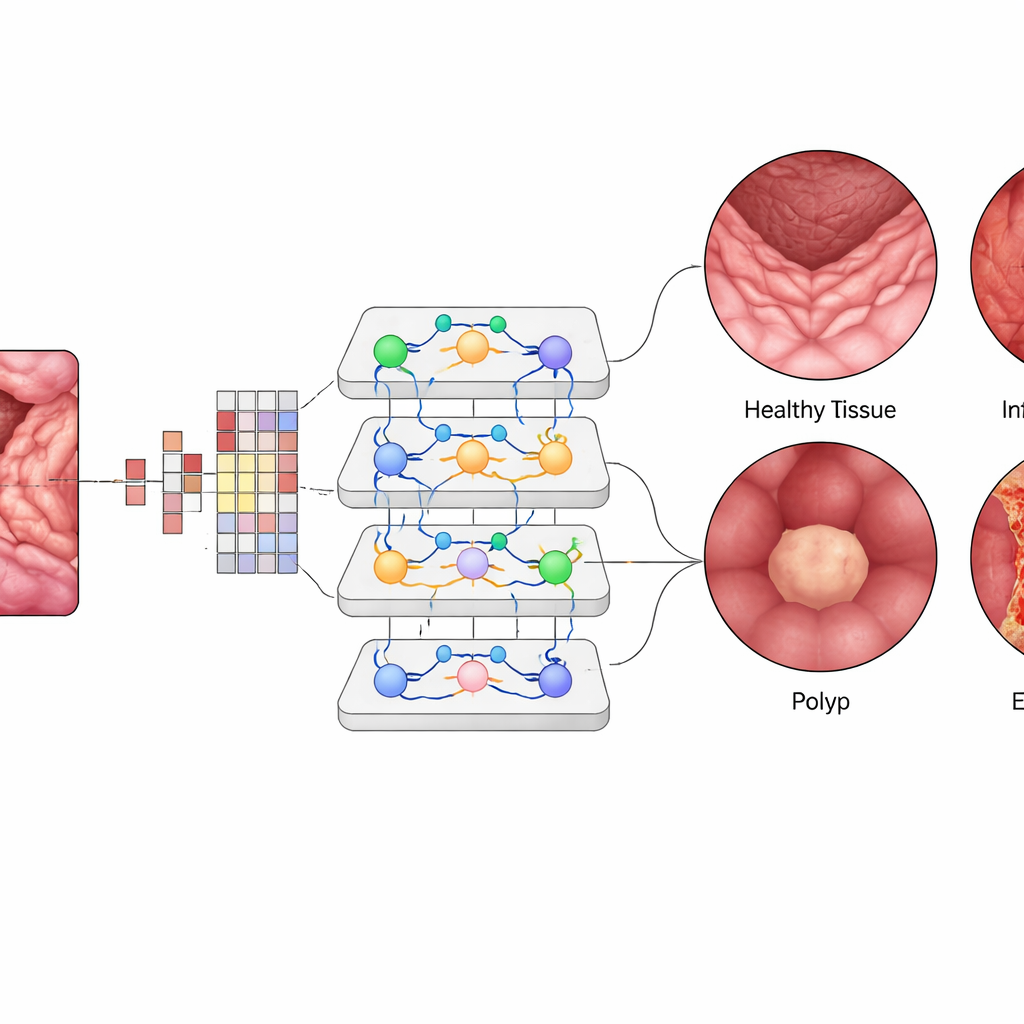
Hastalar ve Klinikler İçin Anlamı
Çalışma, Vision Transformer tabanlı sistemlerin gastroenterolojik görüntüleri okuyan doktorlar için son derece yetenekli asistanlar olarak görev alabileceğini sonucuna varıyor. İnce anormallikleri güvenilir ve hızlı bir şekilde tespit ederek daha erken tanı, hastaneler arasında daha tutarlı bakım ve kaçırılan lezyonların azalmasını mümkün kılabilirler. Model standart grafik donanımında çalışacak kadar verimli olduğundan, rutin tarama iş akışlarına entegre edilerek insan incelemesi gerektiren kareleri otomatik olarak işaretleyebilir. Çok sayıda hastane çapında performansın doğrulanması, nadir hastalıklarla başa çıkma ve otomatik tanı etrafındaki etik konular gibi zorluklar devam etse de, bu çalışma YZ "ortak okuyucularının" yakında daha güvenli ve daha sürdürülebilir sindirim sağlığı hizmetleri için pratik bir araç haline gelebileceğini öne sürüyor.
Atıf: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Anahtar kelimeler: gastrointestinal görüntüleme, vision transformer, endoskopi yapay zekası, polip tespiti, tıbbi görüntü sınıflandırması