Clear Sky Science · de
Erkennung gastroenterologischer Erkrankungen mithilfe transformerbasierter medizinischer Bildgebung für eine nachhaltige Gesundheitsversorgung
Warum Darmaufnahmen intelligentere Unterstützung brauchen
Bauchschmerzen, Blutungen oder unerklärlicher Gewichtsverlust können manchmal auf ernsthafte Probleme im Verdauungstrakt hinweisen, von langanhaltenden Entzündungen bis hin zu Krebs. Ärztinnen und Ärzte verlassen sich auf winzige Kameras, wie sie bei Koloskopien oder verschluckten Kapseln verwendet werden, um auffällige Bereiche zu erkennen. Tausende Bilder pro Patient machen diese Aufgabe jedoch ermüdend und es ist leicht, subtile Warnsignale zu übersehen. Diese Studie untersucht eine neue Form künstlicher Intelligenz (KI), die diese Bilder mit bemerkenswerter Genauigkeit lesen kann, früher gastrointestinale Erkrankungen erkennt und gleichzeitig die Belastung überforderter Gesundheitssysteme verringert.
Mehr sehen in Darmbildern
Der Verdauungstrakt kann von vielen Erkrankungen betroffen sein, darunter Colitis ulcerosa, Ösophagitis und Polypen, die sich zu kolorektalem Krebs entwickeln können. Diese Probleme zeigen sich oft als kleine Veränderungen in Farbe oder Textur an der inneren Oberfläche des Darms. Traditionelle Computerwerkzeuge, die auf konvolutionellen neuronalen Netzen basieren, haben bereits geholfen, verdächtige Stellen in medizinischen Bildern zu markieren, doch sie tun sich schwer, wenn Muster komplex sind oder sich über das Bild verteilen. Daher können bestehende Systeme subtile Krankheitsanzeichen übersehen, besonders wenn Trainingsdaten begrenzt oder ungleich über verschiedene Diagnosetypen verteilt sind.
Eine neue Art digitaler Leser
Diese Forschung prüft ein neueres KI‑Design, bekannt als Vision Transformer, konkret ein Modell namens ViT‑B16, zur Klassifizierung gastroenterologischer Bilder. Statt Bilder starr Stück für Stück zu scannen, zerlegt dieses Modell jedes Bild in kleine Patches und lernt gleichzeitig, wie alle Patches zueinander in Beziehung stehen. Die Autorinnen und Autoren stellten eine ausgeglichene Sammlung von 10.000 Endoskopiebildern in vier Gruppen zusammen: normales Gewebe, Colitis ulcerosa, Polypen und Ösophagitis. Sie filterten sorgfältig minderwertige oder falsch beschriftete Bilder heraus, brachten sie auf ein einheitliches Format und augmentierten sie durch Spiegelungen, Rotationen und Helligkeitsänderungen, damit das Modell robust gegenüber realen Variationen wird. 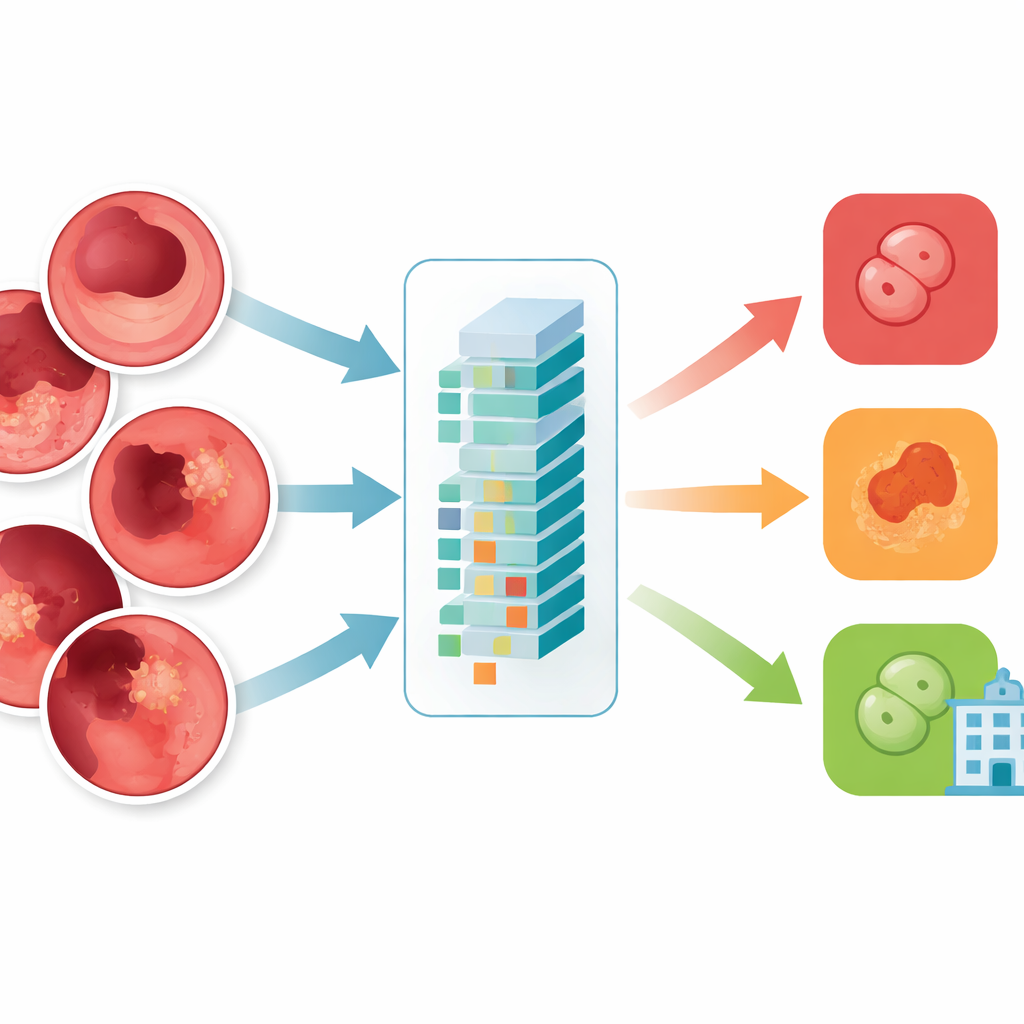
Wie die KI lernt und entscheidet
Im Vision Transformer wird jeder kleine Bildpatch in ein numerisches „Token“ umgewandelt, und Schichten von Attention‑Modulen lernen, welche Patches sich am stärksten gegenseitig beeinflussen sollten. Das erlaubt dem System, weit auseinanderliegende, aber zusammenhängende Regionen in einer Aufnahme des Darms zu gewichten, ähnlich wie eine Klinikerin Muster über das Bild hinweg mental verbindet. Das Team feinabgestimmte ein vortrainiertes ViT‑B16‑Modell unter Verwendung moderner Trainingsmethoden wie adaptiver Optimierung und Kreuzvalidierung und verglich es dann mit weit verbreiteten Deep‑Learning‑Architekturen wie EfficientNet sowie mit beliebten Ensemble‑Methoden mehrerer Netze. Sie nutzten außerdem Erklärungswerkzeuge, die Heatmaps erzeugen und genau die Bereiche der Mukosa hervorheben, auf die die KI achtet, wenn sie eine entzündete Stelle oder einen Polypen erkennt.
Genauigkeit, Vertrauen und reale Reichweite
Der Vision Transformer erreichte auf dem ausgeglichenen Testset eine Gesamtgenauigkeit von etwa 99,5 % und übertraf damit leicht die besten Konkurrenzmodelle und frühere Verfahren bei weitem. Für jede der vier Klassen lagen Präzision, Recall und F1‑Werte bei etwa 99,4 %, und die Kurven zur Unterscheidung der Erkrankungen voneinander waren nahezu perfekt. Nur eine Handvoll Bilder wurden in tausend Testfällen falsch klassifiziert. Als das trainierte System mit einem externen Datensatz unter anderen Bedingungen geprüft wurde, erreichte es immer noch rund 96,8 % Genauigkeit, was eine ermutigende Generalisierungsfähigkeit zeigt. Visualisierungskarten zeigten, dass sich die „Attention" des Modells auf klinisch sinnvolle Regionen konzentrierte — etwa die Oberfläche von Polypen oder entzündete Bereiche — und so das Vertrauen von Klinikerinnen und Klinikern stärkte, dass die KI die richtigen Stellen betrachtet und nicht irrelevanten Hintergrund. 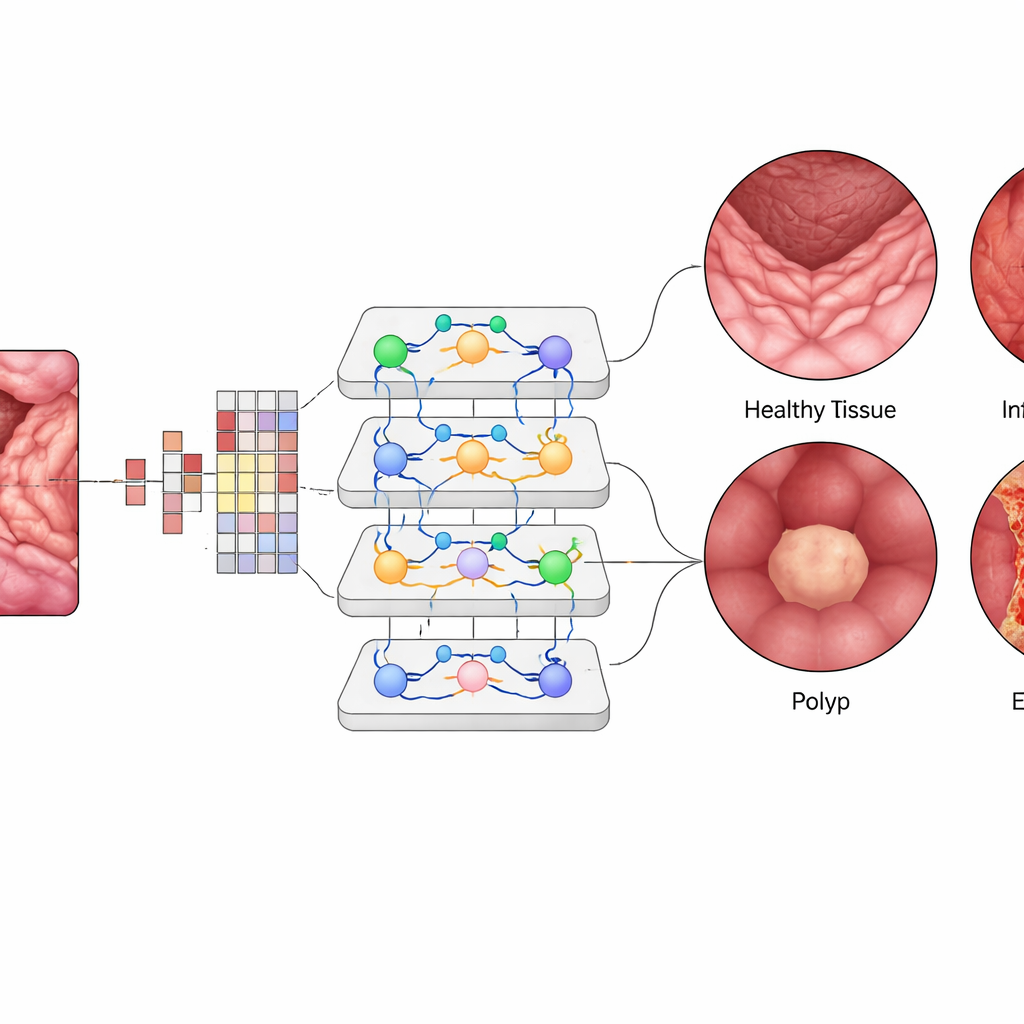
Was das für Patientinnen, Patienten und Kliniken bedeutet
Die Studie kommt zu dem Schluss, dass auf Vision Transformer basierende Systeme als sehr fähige Assistenten für Ärztinnen und Ärzte beim Lesen gastroenterologischer Bilder dienen können. Indem sie subtile Auffälligkeiten zuverlässig und schnell erkennen, könnten sie frühere Diagnosen ermöglichen, gleichmäßigere Versorgung über Krankenhäuser hinweg fördern und verpasste Läsionen reduzieren. Da das Modell effizient genug ist, um auf handelsüblicher Grafikhardware zu laufen, könnte es in routinemäßige Screening‑Abläufe integriert werden und automatisch Frames markieren, die eine genauere menschliche Prüfung verdienen. Zwar bleiben Herausforderungen — wie die Validierung der Leistung über viele Kliniken hinweg, der Umgang mit seltenen Erkrankungen und ethische Fragen zur automatisierten Diagnose — doch diese Arbeit legt nahe, dass KI‑„Co‑Reader" bald ein praktikables Werkzeug für eine sicherere, nachhaltigere gastrointestinale Versorgung werden könnten.
Zitation: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Schlüsselwörter: gastrointestinale Bildgebung, Vision Transformer, Endoskopie‑KI, Polypenerkennung, medizinische Bildklassifikation