Clear Sky Science · fr
Détection des maladies gastro-entérologiques utilisant l’imagerie médicale basée sur des transformers pour des soins durables
Pourquoi les explorations digestives ont besoin d’aide plus intelligente
Les maux d’estomac, les saignements ou une perte de poids inexpliquée peuvent parfois indiquer des problèmes sérieux dans le tube digestif, depuis des inflammations chroniques jusqu’au cancer. Les médecins s’appuient sur de petites caméras, comme celles utilisées en coloscopie ou dans des capsules ingérables, pour repérer les zones anormales. Mais des milliers d’images par patient rendent cette tâche fatigante et facile à rater des signes subtils. Cette étude explore un nouveau type d’intelligence artificielle (IA) capable d’analyser ces images avec une grande précision, aidant à détecter plus tôt les maladies gastro-intestinales tout en allégeant la charge des systèmes de santé surmenés.
Voir davantage dans les images digestives
Le tube digestif peut être affecté par de nombreuses affections, notamment la rectocolite hémorragique, l’oesophagite et les polypes susceptibles d’évoluer en cancer colorectal. Ces problèmes se manifestent souvent par de petites modifications de couleur ou de texture de la surface interne de l’intestin. Les outils informatiques traditionnels basés sur des réseaux neuronaux « convolutionnels » ont déjà aidé à signaler des zones suspectes sur les images médicales, mais ils peinent lorsque les motifs sont complexes ou répartis sur l’image. En conséquence, les systèmes existants peuvent manquer des signes subtils de maladie, notamment lorsque les données d’entraînement sont limitées ou inégalement réparties entre les types de diagnostics.
Un nouveau type de lecteur numérique
Cette recherche teste une architecture d’IA plus récente connue sous le nom de Vision Transformer, en particulier un modèle appelé ViT-B16, pour classer des images gastro-entérologiques. Plutôt que d’analyser l’image morceau par morceau de façon rigide, ce modèle découpe chaque image en petits patchs et apprend simultanément les relations entre tous les patchs. Les auteurs ont constitué un corpus équilibré de 10 000 images endoscopiques réparties en quatre groupes : tissu normal, rectocolite hémorragique, polypes et œsophagite. Ils ont soigneusement éliminé les images de mauvaise qualité ou mal étiquetées, les ont redimensionnées à un format standard et les ont augmentées par rotations, retournements et modifications de luminosité afin que le modèle soit robuste aux variations du monde réel. 
Comment l’IA apprend et décide
À l’intérieur du Vision Transformer, chaque petit patch d’image est converti en un « token » numérique, et des couches de modules d’attention apprennent quels patchs doivent s’influencer mutuellement le plus. Cela permet au système de pondérer des régions éloignées mais liées dans une seule vue de l’intestin, de manière similaire à la façon dont un clinicien relie mentalement des motifs à travers le cadre. L’équipe a affiné un modèle ViT-B16 pré-entraîné en utilisant des techniques d’entraînement modernes comme l’optimisation adaptative et la validation croisée, puis l’a comparé à des architectures profondes largement utilisées comme EfficientNet et à des ensembles populaires de plusieurs réseaux. Ils ont aussi utilisé des outils d’explicabilité qui produisent des cartes de chaleur, mettant en évidence les régions exactes de la muqueuse sur lesquelles l’IA se concentre lorsqu’elle signale une zone enflammée ou un polype.
Précision, confiance et portée en conditions réelles
Le Vision Transformer a atteint environ 99,5 % de précision globale sur l’ensemble de test équilibré, dépassant légèrement les meilleurs modèles concurrents et surpassant de loin les méthodes antérieures. Pour chacune des quatre classes, la précision, le rappel et le score F1 se situaient autour de 99,4 %, et les courbes mesurant sa capacité à distinguer les maladies entre elles étaient quasi parfaites. Seules une poignée d’images ont été mal classées sur mille cas testés. Lorsqu’on a mis le système entraîné au défi avec un jeu de données externe collecté dans des conditions différentes, il a tout de même atteint environ 96,8 % de précision, montrant une généralisation encourageante. Les cartes de visualisation ont révélé que l’« attention » du modèle se concentrait sur des régions cliniquement significatives — comme la surface des polypes ou des zones enflammées — renforçant la confiance des cliniciens que l’IA regarde les bonnes zones plutôt que l’arrière-plan non pertinent. 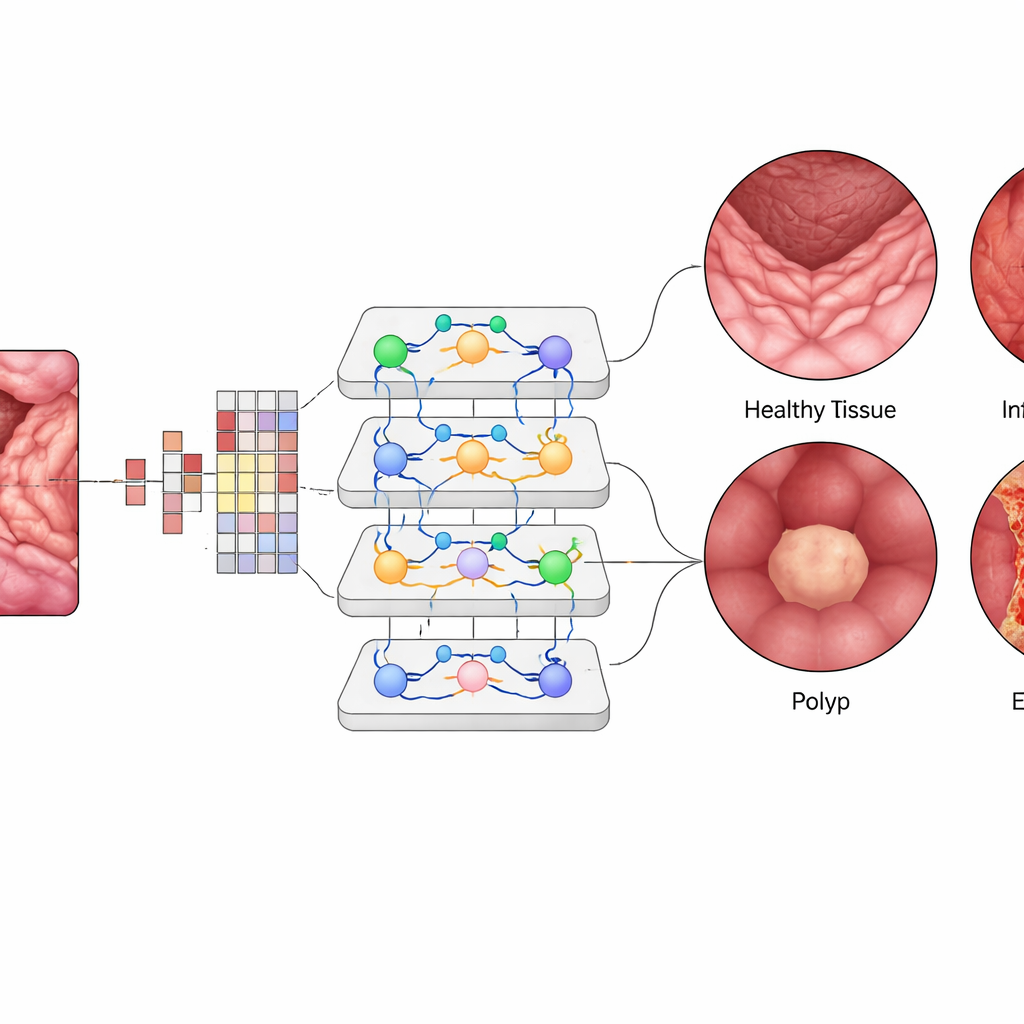
Ce que cela signifie pour les patients et les cliniques
L’étude conclut que les systèmes basés sur Vision Transformer peuvent agir comme des assistants très performants pour les médecins qui lisent des images gastro-intestinales. En détectant de manière fiable et rapide des anomalies subtiles, ils pourraient permettre des diagnostics plus précoces, une prise en charge plus cohérente entre hôpitaux et une réduction des lésions manquées. Étant donné que le modèle est suffisamment efficace pour fonctionner sur du matériel graphique standard, il pourrait être intégré aux flux de dépistage de routine, signalant automatiquement les images qui méritent un examen humain plus approfondi. Bien que des défis subsistent — comme la validation des performances dans de nombreux hôpitaux, la prise en charge des maladies rares et les questions éthiques liées au diagnostic automatisé — ce travail suggère que des « co-lecteurs » IA pourraient bientôt devenir un outil pratique pour des soins digestifs plus sûrs et plus durables.
Citation: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Mots-clés: imagerie gastro-intestinale, vision transformer, IA pour endoscopie, détection de polypes, classification d’images médicales