Clear Sky Science · es
Detección de enfermedades gastroenterológicas mediante imágenes médicas basadas en transformadores para una atención sanitaria sostenible
Por qué los escaneos del intestino necesitan ayuda más inteligente
Los dolores de estómago, el sangrado o la pérdida de peso inexplicada pueden a veces señalar problemas serios en el tracto digestivo, desde inflamación crónica hasta cáncer. Los médicos dependen de cámaras diminutas, como las usadas en colonoscopias o cápsulas ingeribles, para detectar zonas anómalas. Pero miles de imágenes por paciente hacen que esta tarea sea agotadora y que sea fácil pasar por alto señales sutiles. Este estudio explora un nuevo tipo de inteligencia artificial (IA) que puede leer estas imágenes con una precisión notable, ayudando a detectar antes las enfermedades gastrointestinales y aliviando la carga de sistemas sanitarios sobrecargados.
Ver más en las imágenes del intestino
El tracto digestivo puede verse afectado por muchas condiciones, incluidas la colitis ulcerosa, la esofagitis y los pólipos que pueden evolucionar hacia cáncer colorrectal. Estos problemas a menudo aparecen como pequeños cambios de color o textura en la superficie interna del intestino. Las herramientas informáticas tradicionales basadas en redes neuronales “convolucionales” ya han ayudado a señalar áreas sospechosas en imágenes médicas, pero presentan dificultades cuando los patrones son complejos o están dispersos por toda la imagen. Como resultado, los sistemas existentes pueden pasar por alto signos sutiles de enfermedad, especialmente cuando los datos de entrenamiento son limitados o están desigualmente distribuidos entre tipos de diagnóstico.
Un nuevo tipo de lector digital
Esta investigación prueba un diseño de IA más reciente conocido como Vision Transformer, concretamente un modelo llamado ViT-B16, para clasificar imágenes gastroenterológicas. En lugar de escanear las imágenes pieza por pieza de forma rígida, este modelo divide cada imagen en pequeños parches y aprende cómo se relacionan todos los parches entre sí a la vez. Los autores construyeron una colección equilibrada de 10.000 imágenes endoscópicas repartidas en cuatro grupos: tejido normal, colitis ulcerosa, pólipos y esofagitis. Filtraron cuidadosamente las imágenes de baja calidad o mal etiquetadas, las redimensionaron a un formato estándar y las aumentaron con volteos, rotaciones y cambios de brillo para que el modelo fuera robusto frente a variaciones del mundo real. 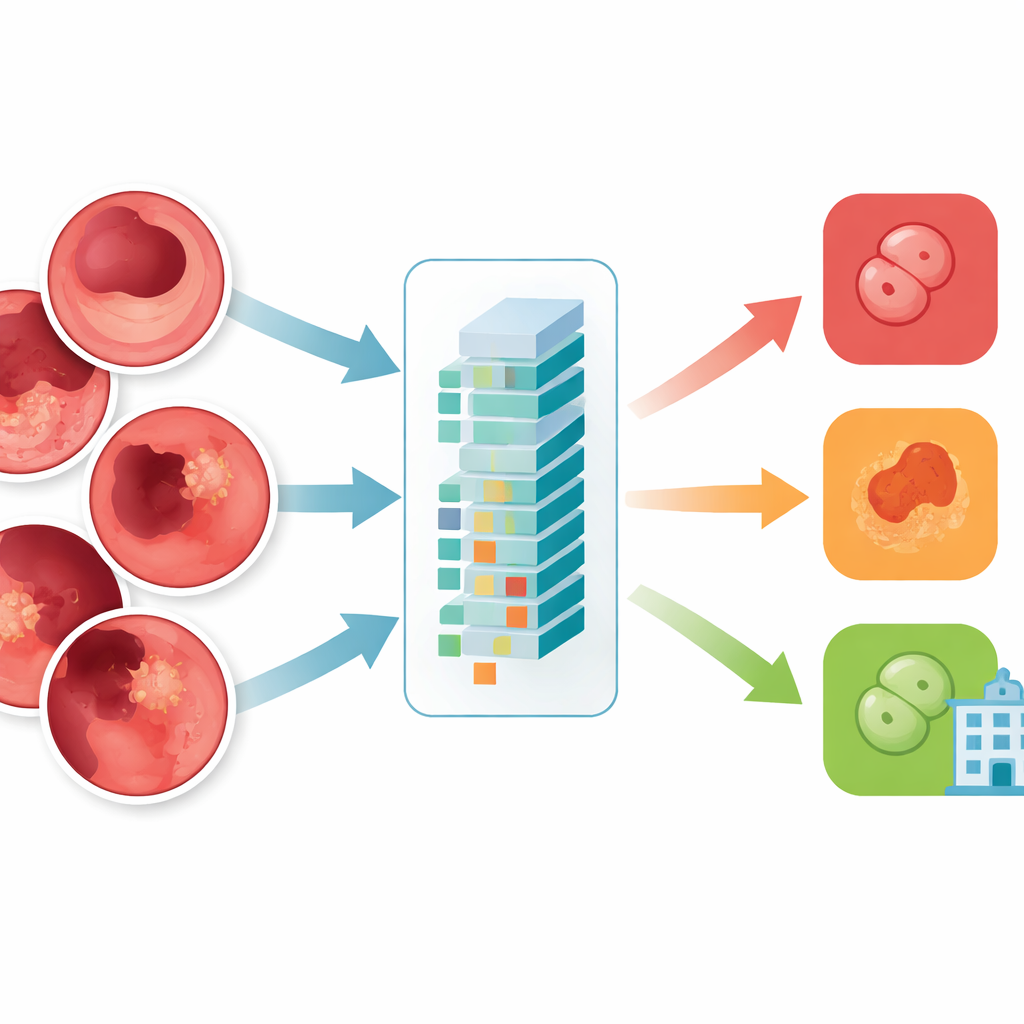
Cómo la IA aprende y decide
Dentro del Vision Transformer, cada pequeño parche de imagen se convierte en un “token” numérico, y capas de módulos de atención aprenden qué parches deben influir más entre sí. Esto permite al sistema ponderar regiones distantes pero relacionadas en una sola vista del intestino, de forma similar a cómo un clínico conecta mentalmente patrones a lo largo del encuadre. El equipo afinó un modelo ViT-B16 preentrenado usando técnicas modernas de entrenamiento como optimización adaptativa y validación cruzada, y lo comparó con arquitecturas de aprendizaje profundo ampliamente usadas como EfficientNet y con conjuntos populares de múltiples redes. También emplearon herramientas de explicación que generan mapas de calor, destacando las regiones exactas de la mucosa en las que la IA se centra cuando señala un área inflamada o un pólipo.
Precisión, confianza y alcance en el mundo real
El Vision Transformer alcanzó aproximadamente un 99,5% de precisión global en el conjunto de prueba balanceado, superando ligeramente a los mejores modelos competidores y superando con creces métodos anteriores. Para cada una de las cuatro clases, la precisión, la sensibilidad y las puntuaciones F1 rondaron el 99,4%, y las curvas que miden su capacidad para distinguir las enfermedades entre sí fueron casi perfectas. Solo un puñado de imágenes fue clasificado erróneamente de entre mil casos de prueba. Cuando el sistema entrenado fue probado con un conjunto de datos externo recogido en condiciones diferentes, aún alcanzó alrededor de un 96,8% de precisión, mostrando una generalización prometedora. Los mapas de visualización revelaron que la “atención” del modelo se concentraba en regiones con significado clínico—como la superficie de los pólipos o áreas inflamadas—reforzando la confianza de los clínicos en que la IA mira los lugares correctos en lugar de fondo irrelevante. 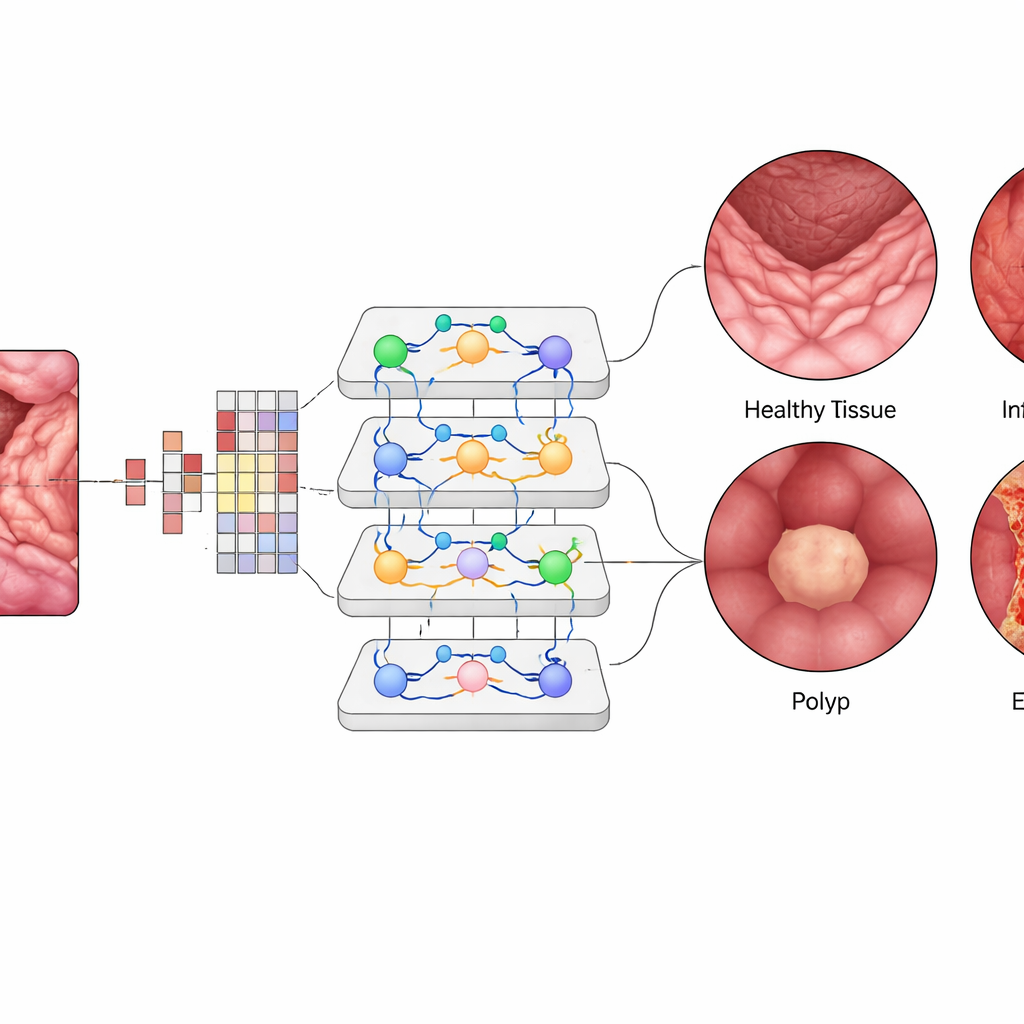
Qué significa esto para pacientes y consultas
El estudio concluye que los sistemas basados en Vision Transformer pueden actuar como asistentes altamente capaces para los médicos que leen imágenes gastrointestinales. Al detectar anomalías sutiles de manera fiable y rápida, podrían permitir un diagnóstico más temprano, una atención más consistente entre hospitales y una reducción de lesiones pasadas por alto. Dado que el modelo es lo bastante eficiente para ejecutarse en hardware gráfico estándar, podría integrarse en flujos de trabajo de cribado de rutina, marcando automáticamente fotogramas que merecen una revisión humana más detallada. Aunque persisten desafíos—como validar el rendimiento en muchos hospitales, manejar enfermedades raras y abordar cuestiones éticas sobre el diagnóstico automatizado—este trabajo sugiere que los “colectores” de lectura por IA pueden convertirse pronto en una herramienta práctica para una atención digestiva más segura y sostenible.
Cita: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Palabras clave: imagen gastrointestinal, vision transformer, IA en endoscopia, detección de pólipos, clasificación de imágenes médicas