Clear Sky Science · ru
Обнаружение заболеваний гастроэнтерологической сферы с помощью трансформерной обработки медицинских изображений для устойчивого здравоохранения
Почему сканирования кишечника нуждаются в более умной помощи
Боли в животе, кровотечение или необъяснимая потеря веса иногда могут указывать на серьёзные проблемы в пищеварительном тракте — от хронического воспаления до рака. Врачи полагаются на миниатюрные камеры, такие как при колоноскопии или в проглатываемых капсулах, чтобы обнаруживать аномальные участки. Но тысячи изображений на пациента делают эту задачу утомительной, и легко пропустить тонкие признаки. В этом исследовании изучается новый тип искусственного интеллекта (ИИ), который способен читать эти изображения с высокой точностью, помогая выявлять заболевания ЖКТ раньше и снижая нагрузку на перегруженные системы здравоохранения.
Увидеть больше на изображениях кишечника
Пищеварительный тракт подвержен множеству заболеваний, включая язвенный колит, эзофагит и полипы, которые могут развиться в колоректальный рак. Эти проблемы часто проявляются небольшими изменениями цвета или текстуры на внутренней поверхности кишки. Традиционные компьютерные инструменты на основе сверточных нейронных сетей уже помогают отмечать подозрительные участки на медицинских изображениях, но они испытывают трудности, когда паттерны сложные или распределены по всему кадру. В результате существующие системы могут пропускать тонкие признаки болезни, особенно при ограниченных или неравномерно распределённых обучающих данных по разным диагнозам.
Новый цифровой «читатель»
В этом исследовании тестируется более новая архитектура ИИ, известная как Vision Transformer, в частности модель ViT‑B16, для классификации гастроэнтерологических изображений. Вместо того чтобы жёстко сканировать картинку фрагмент за фрагментом, модель разбивает изображение на мелкие патчи и одновременно изучает взаимосвязи между ними. Авторы собрали сбалансированную коллекцию из 10 000 эндоскопических изображений по четырём группам: нормальная ткань, язвенный колит, полипы и эзофагит. Они тщательно отфильтровали изображения низкого качества и ошибочно помеченные кадры, привели их к стандартному размеру и увеличили набор данных с помощью зеркалирования, поворотов и изменений яркости, чтобы модель была устойчива к реальным вариациям. 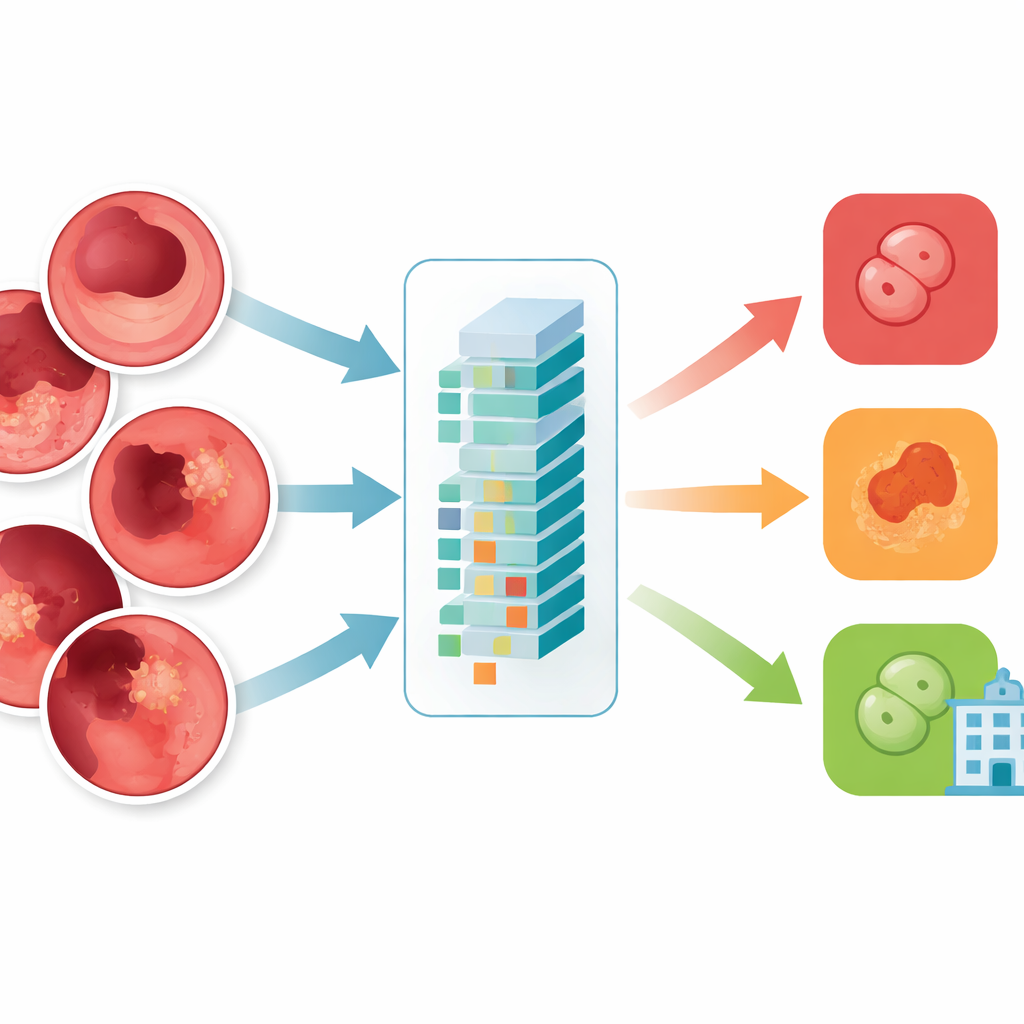
Как ИИ обучается и принимает решения
Внутри Vision Transformer каждый маленький патч изображения преобразуется в числовой «токен», а слои механизмов внимания учатся определять, какие патчи должны сильнее влиять друг на друга. Это позволяет системе взвешивать отдалённые, но связанные области в одном кадре кишечника, подобно тому, как клиницист мысленно связывает паттерны по всему изображению. Команда дообучила предварительно натренированную модель ViT‑B16, используя современные приёмы обучения — адаптивную оптимизацию и кросс‑валидацию, — затем сравнила её с широко используемыми архитектурами глубокого обучения, такими как EfficientNet, и популярными ансамблями сетей. Они также применили инструменты объяснимости, генерирующие тепловые карты, которые подсвечивают точные участки слизистой, на которые ИИ обращает внимание при обнаружении воспаления или полипа.
Точность, доверие и реальная применимость
Vision Transformer достиг примерно 99,5% общей точности на сбалансированном тестовом наборе, немного превзойдя лучшие конкурирующие модели и значительно опередив ранее применявшиеся методы. Для каждой из четырёх категорий показатели precision, recall и F1‑score составляли около 99,4%, а кривые, оценивающие способность различать болезни, были близки к идеальным. Было неправильно классифицировано лишь несколько изображений из тысячи тестовых случаев. При проверке на внешнем наборе данных, собранном в других условиях, система всё ещё показала около 96,8% точности, демонстрируя обнадёживающую обобщаемость. Карты визуализации показали, что «внимание» модели сосредоточено на клинически значимых областях — например, на поверхности полипов или воспалённых участках — что укрепляет доверие врачей к тому, что ИИ смотрит на нужные места, а не на посторонний фон. 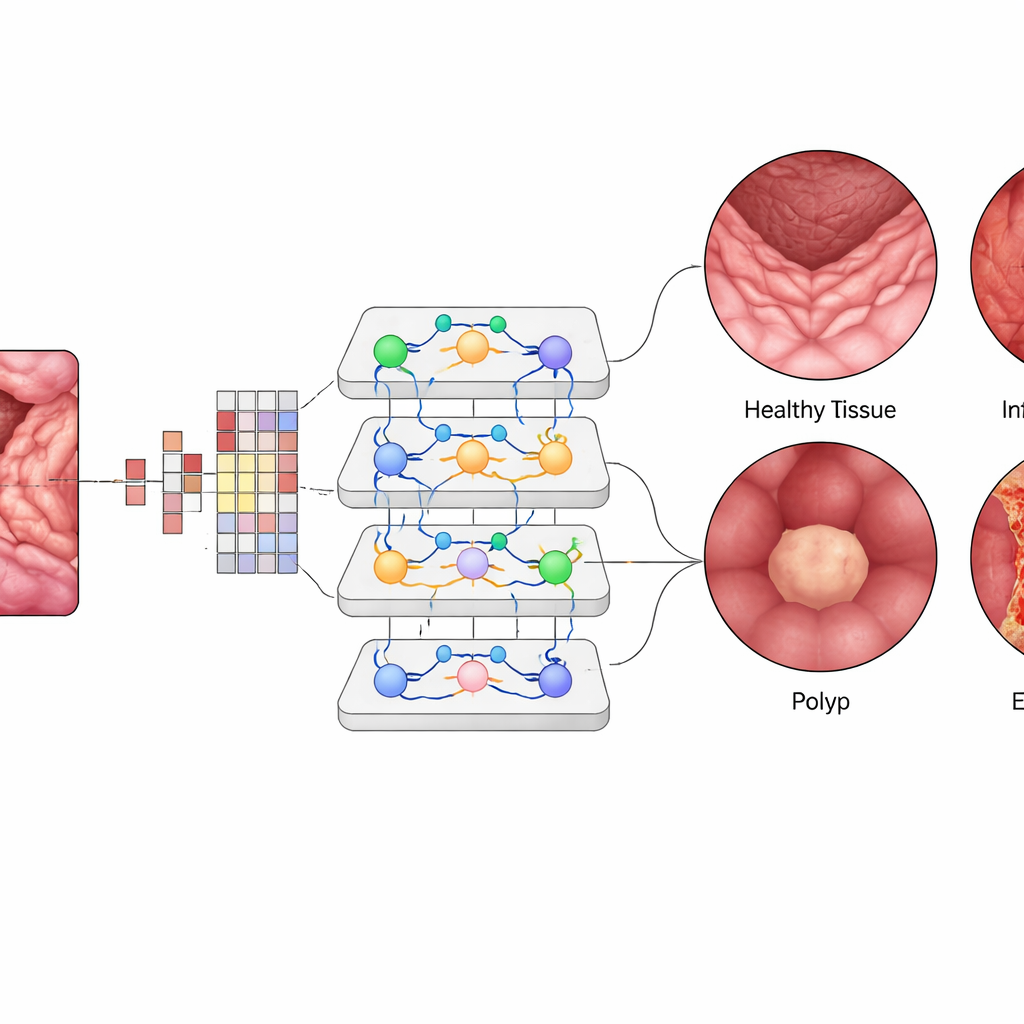
Что это означает для пациентов и клиник
Авторы приходят к выводу, что системы на базе Vision Transformer могут выступать в роли высокоэффективных ассистентов для врачей, читающих изображения ЖКТ. Надёжно и быстро обнаруживая тонкие аномалии, они могут обеспечить раннюю диагностику, более последовательное лечение в разных больницах и сократить число пропущенных поражений. Поскольку модель достаточно эффективна для запуска на стандартном графическом оборудовании, её можно интегрировать в рутинные скрининговые потоки, автоматически помечая кадры, требующие более пристального человеческого рассмотрения. Хотя остаются вызовы — валидация работы в разных клиниках, обработка редких заболеваний и этические вопросы, связанные с автоматизированным диагнозом — работа показывает, что ИИ‑«соавторы» вскоре могут стать практичным инструментом для более безопасного и устойчивого ухода за больными ЖКТ.
Цитирование: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Ключевые слова: изображения желудочно‑кишечного тракта, vision transformer, ИИ для эндоскопии, обнаружение полипов, классификация медицинских изображений