Clear Sky Science · it
Rilevamento delle malattie gastroenterologiche tramite imaging medico basato su transformer per un'assistenza sanitaria sostenibile
Perché le scansioni intestinali hanno bisogno di un aiuto più intelligente
I dolori di stomaco, il sanguinamento o una perdita di peso inspiegabile possono talvolta segnalare problemi seri all’interno del tratto digestivo, dall’infiammazione cronica al cancro. I medici si affidano a piccole videocamere, come quelle utilizzate nelle colonscopie o nelle pillole ingerite, per individuare aree anomale. Ma migliaia di immagini per paziente rendono questo compito stancante e facile da non notare segnali sottili. Questo studio esplora un nuovo tipo di intelligenza artificiale (IA) capace di leggere queste immagini con notevole accuratezza, aiutando a intercettare prima le malattie gastrointestinali e alleggerendo al contempo il carico sui sistemi sanitari sotto pressione.
Vedere di più nelle immagini intestinali
Il tratto digestivo può essere interessato da molte condizioni, tra cui colite ulcerosa, esofagite e polipi che possono evolvere in cancro colorettale. Questi problemi si manifestano spesso come piccoli cambiamenti di colore o texture sulla superficie interna dell’intestino. Gli strumenti informatici tradizionali basati su reti neurali “convoluzionali” hanno già aiutato a segnalare punti sospetti nelle immagini mediche, ma faticano quando i pattern sono complessi o distribuiti sull’intera immagine. Di conseguenza, i sistemi esistenti possono perdere segnali sottili di malattia, soprattutto quando i dati di addestramento sono limitati o distribuiti in modo disomogeneo tra i diversi tipi di diagnosi.
Un nuovo tipo di lettore digitale
Questa ricerca testa un design di IA più recente noto come Vision Transformer, in particolare un modello chiamato ViT-B16, per classificare immagini gastroenterologiche. Invece di scansionare le immagini pezzo per pezzo in modo rigido, questo modello suddivide ogni immagine in piccole patch e apprende come tutte le patch si relazionano tra loro contemporaneamente. Gli autori hanno costruito una raccolta bilanciata di 10.000 immagini endoscopiche suddivise in quattro gruppi: tessuto normale, colite ulcerosa, polipi ed esofagite. Hanno filtrato con cura immagini di scarsa qualità o etichettate in modo errato, ridimensionato le immagini a un formato standard e le hanno aumentate con ribaltamenti, rotazioni e variazioni di luminosità in modo che il modello fosse robusto alle variazioni del mondo reale. 
Come l’IA impara e decide
All’interno del Vision Transformer, ogni piccola patch dell’immagine viene trasformata in un “token” numerico, e strati di moduli di attenzione apprendono quali patch debbano influenzarsi reciprocamente in modo più marcato. Questo permette al sistema di dare peso a regioni distanti ma correlate in una singola vista dell’intestino, in modo simile a come un clinico collega mentalmente i pattern all’interno del fotogramma. Il team ha messo a punto un modello ViT-B16 pre‑addestrato usando tecniche moderne di training come ottimizzazione adattiva e cross‑validation, quindi lo ha confrontato con architetture di deep‑learning largamente usate come EfficientNet e popolari ensemble di più reti. Hanno inoltre impiegato strumenti di spiegazione che producono mappe di calore, evidenziando le esatte regioni della mucosa su cui l’IA si concentra quando identifica un’area infiammata o un polipo.
Accuratezza, fiducia e capacità di impiego reale
Il Vision Transformer ha raggiunto circa il 99,5% di accuratezza complessiva sul set di test bilanciato, superando leggermente i migliori modelli concorrenti e surclassando i metodi precedenti. Per ciascuna delle quattro classi, precisione, richiamo (recall) e punteggi F1 si sono attestati intorno al 99,4%, e le curve che misurano la capacità di distinguere le malattie tra loro erano quasi perfette. Solo una manciata di immagini è stata classificata in modo errato su mille casi di test. Quando il sistema addestrato è stato sfidato con un dataset esterno raccolto in condizioni diverse, ha comunque ottenuto circa il 96,8% di accuratezza, mostrando una generalizzazione incoraggiante. Le mappe di visualizzazione hanno rivelato che l’“attenzione” del modello si concentrava su regioni clinicamente significative — come la superficie dei polipi o le aree infiammate — rafforzando la fiducia dei clinici che l’IA stia guardando i punti giusti piuttosto che lo sfondo irrilevante. 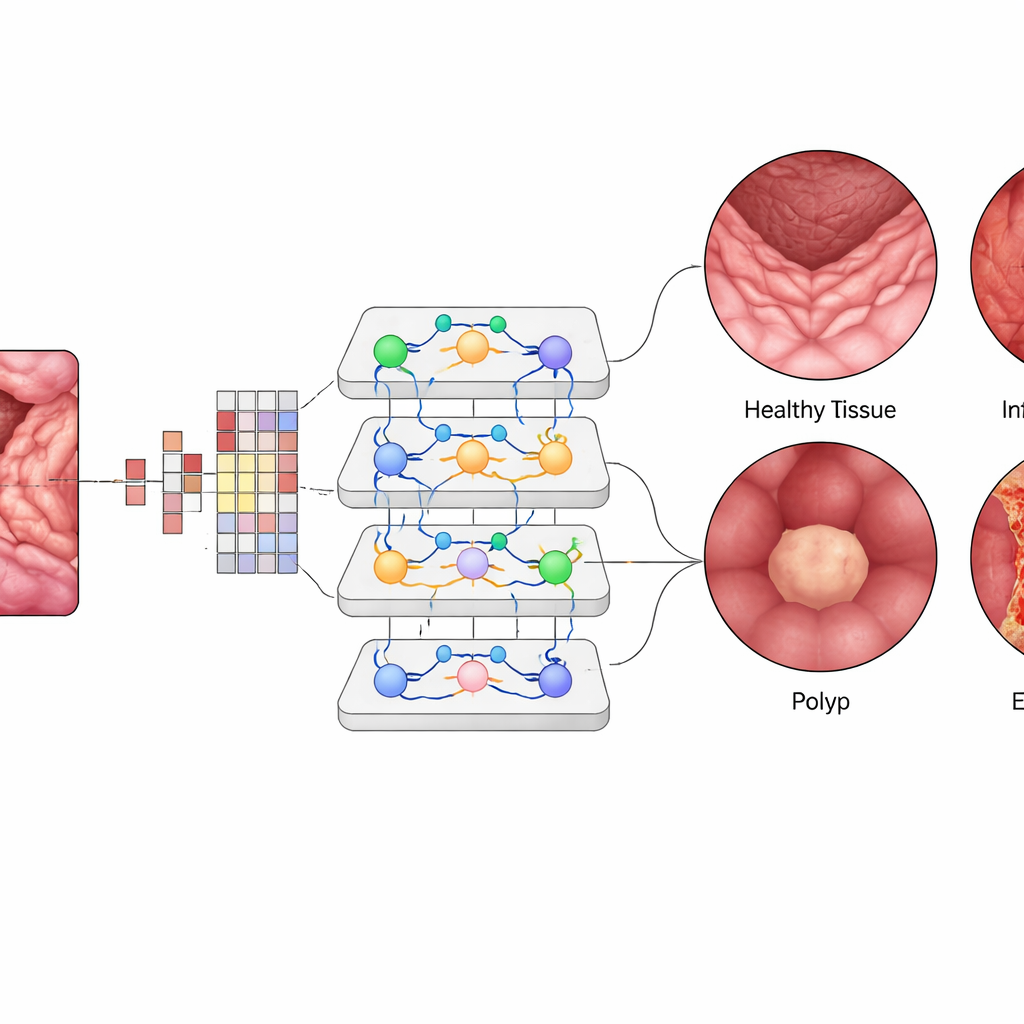
Che cosa significa per i pazienti e le cliniche
Lo studio conclude che i sistemi basati su Vision Transformer possono fungere da assistenti altamente capaci per i medici che leggono le immagini gastroenterologiche. Segnalando anomalie sottili in modo affidabile e rapido, potrebbero consentire diagnosi più precoci, cure più omogenee tra gli ospedali e una riduzione delle lesioni non rilevate. Poiché il modello è sufficientemente efficiente da essere eseguito su hardware grafico standard, potrebbe essere integrato nei flussi di lavoro di screening di routine, segnalando automaticamente i fotogrammi che meritano un esame umano più attento. Pur restando sfide — come la validazione delle prestazioni su molti ospedali, la gestione delle malattie rare e le questioni etiche legate alla diagnosi automatizzata — questo lavoro suggerisce che gli “co‑reader” basati su IA potrebbero presto diventare uno strumento pratico per un’assistenza digestiva più sicura e più sostenibile.
Citazione: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Parole chiave: imaging gastrointestinale, vision transformer, IA per endoscopia, rilevamento dei polipi, classificazione di immagini mediche