Clear Sky Science · en
Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare
Why Gut Scans Need Smarter Help
Stomach aches, bleeding, or unexplained weight loss can sometimes signal serious problems inside the digestive tract, from long‑lasting inflammation to cancer. Doctors rely on tiny cameras, such as those used in colonoscopies or swallowed capsules, to spot abnormal areas. But thousands of images per patient make this task tiring and easy to miss subtle warning signs. This study explores a new kind of artificial intelligence (AI) that can read these images with remarkable accuracy, helping catch gastrointestinal disease earlier while easing the load on overstretched healthcare systems.
Seeing More in Gut Images
The digestive tract can suffer from many conditions, including ulcerative colitis, esophagitis, and polyps that may develop into colorectal cancer. These problems often show up as small changes in color or texture on the inner surface of the bowel. Traditional computer tools based on “convolutional” neural networks have already helped flag suspicious spots on medical images, but they struggle when the patterns are complex or spread out across the picture. As a result, existing systems can miss subtle signs of disease, especially when training data are limited or unevenly distributed across different diagnosis types.
A New Kind of Digital Reader
This research tests a newer AI design known as a Vision Transformer, specifically a model called ViT-B16, to classify gastroenterological images. Instead of scanning pictures piece by piece in a rigid way, this model cuts each image into small patches and learns how all patches relate to one another at once. The authors built a balanced collection of 10,000 endoscopy images across four groups: normal tissue, ulcerative colitis, polyps, and esophagitis. They carefully filtered out low‑quality or mislabeled images, resized them to a standard format, and augmented them with flips, rotations, and brightness changes so the model would be robust to real‑world variations. 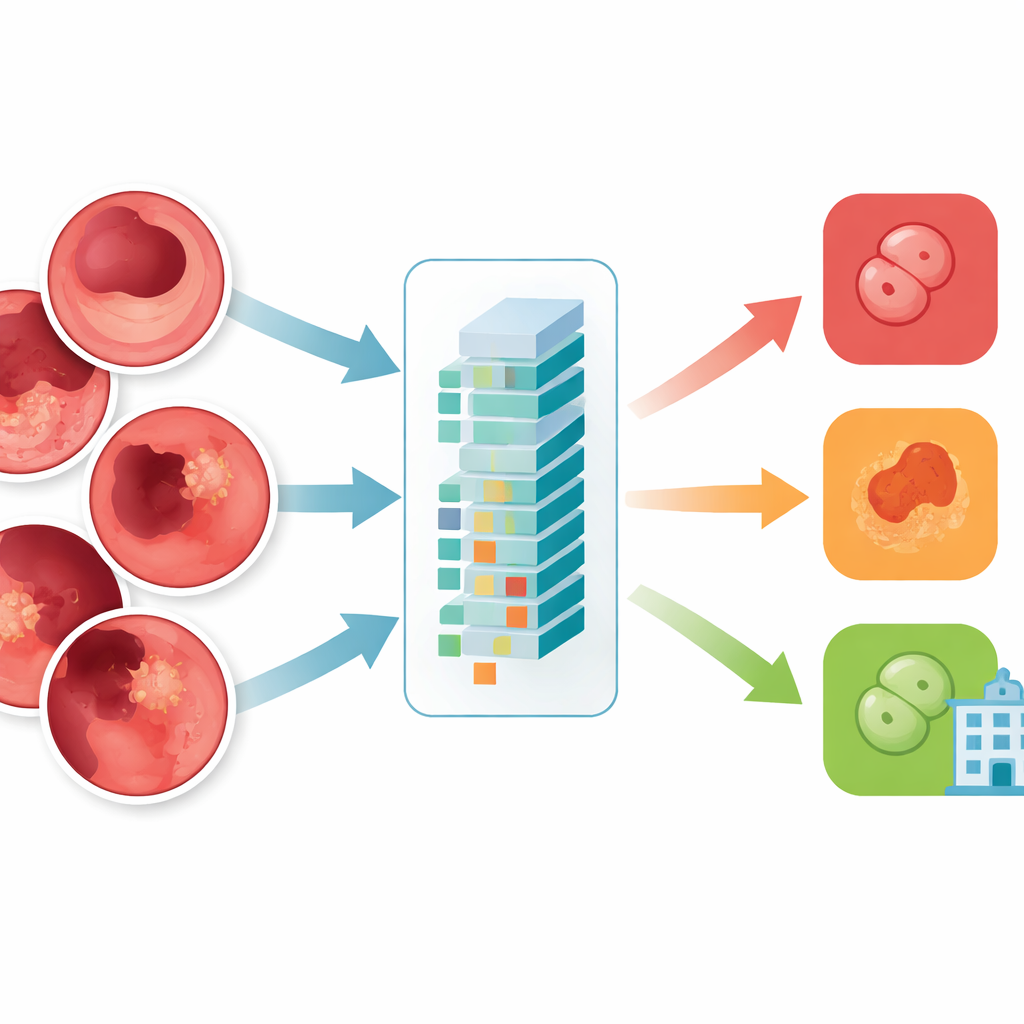
How the AI Learns and Decides
Inside the Vision Transformer, each tiny image patch is turned into a numerical “token,” and layers of attention modules learn which patches should influence each other most strongly. This allows the system to weigh distant but related regions in a single view of the gut, similar to how a clinician mentally connects patterns across the frame. The team fine‑tuned a pre‑trained ViT-B16 model using modern training tricks such as adaptive optimization and cross‑validation, then compared it against widely used deep‑learning architectures like EfficientNet and popular ensembles of multiple networks. They also used explanation tools that produce heat maps, highlighting the exact regions of the mucosa the AI focuses on when it calls out an inflamed area or a polyp.
Accuracy, Trust, and Real‑World Reach
The Vision Transformer reached about 99.5% overall accuracy on the balanced test set, slightly outperforming the best competing models and far exceeding earlier methods. For each of the four classes, precision, recall, and F1‑scores hovered around 99.4%, and curves measuring its ability to distinguish diseases from one another were near perfect. Only a handful of images were misclassified out of a thousand test cases. When the trained system was challenged with an external dataset collected under different conditions, it still achieved around 96.8% accuracy, showing encouraging generalization. Visualization maps revealed that the model’s “attention” clustered on clinically meaningful regions—such as the surface of polyps or inflamed patches—reinforcing clinicians’ trust that the AI is looking at the right places rather than irrelevant background. 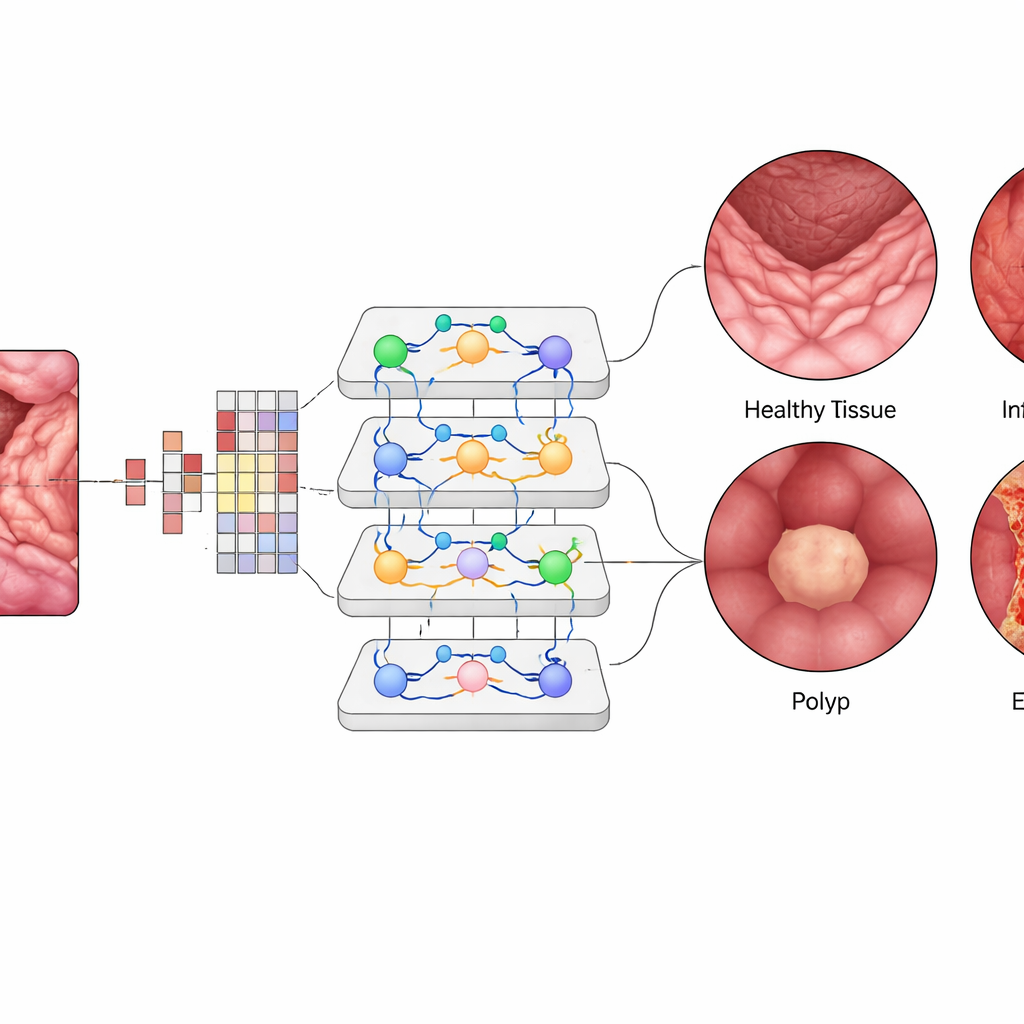
What This Means for Patients and Clinics
The study concludes that Vision Transformer–based systems can act as highly capable assistants for doctors reading gastrointestinal images. By spotting subtle abnormalities reliably and quickly, they could enable earlier diagnosis, more consistent care across hospitals, and reduced missed lesions. Because the model is efficient enough to run on standard graphics hardware, it could be integrated into routine screening workflows, automatically flagging frames that deserve closer human review. While challenges remain—such as validating performance across many hospitals, handling rare diseases, and addressing ethical issues around automated diagnosis—this work suggests that AI “co‑readers” may soon become a practical tool for safer, more sustainable digestive healthcare.
Citation: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Keywords: gastrointestinal imaging, vision transformer, endoscopy AI, polyp detection, medical image classification