Clear Sky Science · pt
Detecção de doenças gastroenterológicas usando imagens médicas baseadas em transformers para um atendimento de saúde sustentável
Por que exames do intestino precisam de auxílio mais inteligente
Dores no estômago, sangramentos ou perda de peso inexplicada podem, às vezes, indicar problemas sérios no trato digestivo, desde inflamação prolongada até câncer. Os médicos dependem de pequenas câmeras, como as usadas em colonoscopias ou cápsulas ingeríveis, para identificar áreas anormais. Mas milhares de imagens por paciente tornam essa tarefa cansativa e aumentam a chance de se perder sinais sutis. Este estudo explora um novo tipo de inteligência artificial (IA) capaz de ler essas imagens com notável precisão, ajudando a detectar doenças gastrointestinais mais cedo e aliviando a carga sobre sistemas de saúde sobrecarregados.
Enxergando mais nas imagens do intestino
O trato digestivo pode ser afetado por várias condições, incluindo colite ulcerativa, esofagite e pólipos que podem evoluir para câncer colorretal. Esses problemas costumam se manifestar como pequenas mudanças de cor ou textura na superfície interna do intestino. Ferramentas computacionais tradicionais baseadas em redes neurais convolucionais já ajudaram a sinalizar pontos suspeitos em imagens médicas, mas têm dificuldades quando os padrões são complexos ou se estendem por grande parte da imagem. Como resultado, sistemas existentes podem deixar passar sinais sutis de doença, especialmente quando os dados de treinamento são limitados ou distribuídos de forma desigual entre os tipos de diagnóstico.
Um novo tipo de leitor digital
Esta pesquisa testa um projeto de IA mais recente conhecido como Vision Transformer, especificamente um modelo chamado ViT-B16, para classificar imagens gastroenterológicas. Em vez de analisar as imagens pedaço a pedaço de forma rígida, este modelo divide cada imagem em pequenos blocos e aprende como todos os blocos se relacionam entre si ao mesmo tempo. Os autores montaram uma coleção balanceada de 10.000 imagens de endoscopia em quatro grupos: tecido normal, colite ulcerativa, pólipos e esofagite. Filtraram cuidadosamente imagens de baixa qualidade ou rotuladas incorretamente, redimensionaram-nas para um formato padrão e as aumentaram com reflexões, rotações e alterações de brilho para que o modelo fosse robusto a variações do mundo real. 
Como a IA aprende e decide
No interior do Vision Transformer, cada pequeno bloco de imagem é convertido em um “token” numérico, e camadas de módulos de atenção aprendem quais blocos devem influenciar-se mutuamente com mais intensidade. Isso permite que o sistema pese regiões distantes, mas relacionadas, em uma única visão do intestino, de modo semelhante a como um clínico conecta mentalmente padrões ao longo do quadro. A equipe ajustou um modelo ViT-B16 pré-treinado usando técnicas modernas de treinamento, como otimização adaptativa e validação cruzada, e o comparou com arquiteturas de deep learning amplamente usadas, como EfficientNet, e com ensembles populares de múltiplas redes. Também utilizaram ferramentas explicativas que produzem mapas de calor, destacando as regiões exatas da mucosa em que a IA se concentra ao identificar uma área inflamada ou um pólipo.
Precisão, confiança e alcance no mundo real
O Vision Transformer atingiu cerca de 99,5% de acurácia geral no conjunto de teste balanceado, superando ligeiramente os melhores modelos concorrentes e superando em muito métodos anteriores. Para cada uma das quatro classes, precisão, recall e F1 ficaram em torno de 99,4%, e as curvas que medem sua capacidade de distinguir as doenças entre si ficaram quase perfeitas. Apenas um pequeno número de imagens foi classificado incorretamente entre mil casos de teste. Quando o sistema treinado foi desafiado com um conjunto de dados externo coletado em condições diferentes, ainda alcançou cerca de 96,8% de acurácia, mostrando generalização promissora. Mapas de visualização revelaram que a “atenção” do modelo se concentrava em regiões clinicamente relevantes — como a superfície de pólipos ou áreas inflamadas — reforçando a confiança dos clínicos de que a IA está olhando para os locais corretos, em vez de para o fundo irrelevante. 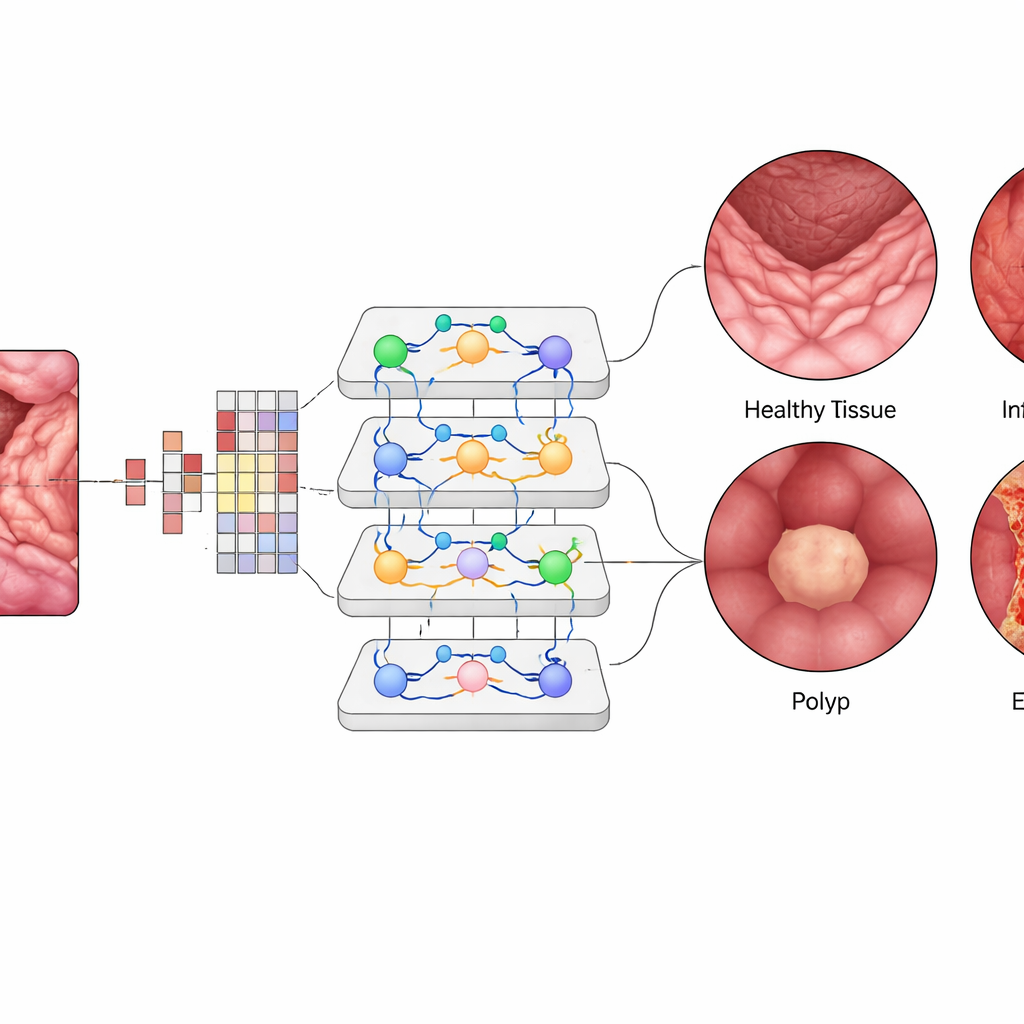
O que isso significa para pacientes e clínicas
O estudo conclui que sistemas baseados em Vision Transformer podem atuar como assistentes altamente capazes para médicos que analisam imagens gastrointestinais. Ao detectar anomalias sutis de modo confiável e rápido, eles podem possibilitar diagnósticos mais precoces, cuidados mais consistentes entre hospitais e redução de lesões não detectadas. Como o modelo é eficiente o suficiente para rodar em hardware gráfico padrão, ele poderia ser integrado a fluxos de triagem de rotina, sinalizando automaticamente quadros que merecem revisão humana mais atenta. Embora desafios permaneçam — como validar o desempenho em muitos hospitais, lidar com doenças raras e abordar questões éticas em torno do diagnóstico automatizado — este trabalho sugere que “co‑leitores” de IA podem se tornar em breve uma ferramenta prática para um cuidado digestivo mais seguro e sustentável.
Citação: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Palavras-chave: imagem gastrointestinal, vision transformer, IA para endoscopia, detecção de pólipos, classificação de imagens médicas