Clear Sky Science · sv
Detection av gastroenterologiska sjukdomar med transformer‑baserad medicinsk bildanalys för hållbar vård
Varför tarmundersökningar behöver smartare stöd
Magsmärtor, blödningar eller oförklarlig viktminskning kan ibland vara tecken på allvarliga problem i matsmältningskanalen, från långvarig inflammation till cancer. Läkare förlitar sig på små kameror, som de som används vid koloskopier eller upplösliga kapslar, för att upptäcka avvikande områden. Men tusentals bilder per patient gör uppgiften tröttande och det är lätt att missa subtila varningssignaler. Denna studie undersöker en ny typ av artificiell intelligens (AI) som kan läsa dessa bilder med anmärkningsvärd noggrannhet, hjälpa till att fånga gastroenterologiska sjukdomar tidigare och samtidigt lätta bördan på redan hårt ansträngda vårdsystem.
Se mer i tarmbilder
Matsmältningskanalen kan drabbas av många tillstånd, inklusive ulcerös kolit, esofagit och polyper som kan utvecklas till kolorektal cancer. Dessa problem visar sig ofta som små förändringar i färg eller textur på tarmens insida. Traditionella datorverktyg baserade på konvolutionella neurala nätverk har redan hjälpt till att markera misstänkta områden i medicinska bilder, men de har svårt när mönstren är komplexa eller spridda över bilden. Som ett resultat kan befintliga system missa subtila tecken på sjukdom, särskilt när träningsdata är begränsade eller ojämnt fördelade mellan olika diagnosgrupper.
En ny sorts digital läsare
Denna forskning testar en nyare AI‑arkitektur känd som Vision Transformer, specifikt en modell kallad ViT‑B16, för att klassificera gastroenterologiska bilder. Istället för att skanna bilder bit för bit på ett stelbent sätt delar denna modell upp varje bild i små patchar och lär sig hur alla patchar förhåller sig till varandra samtidigt. Författarna byggde en balanserad samling på 10 000 endoskopibilder fördelade på fyra grupper: normal vävnad, ulcerös kolit, polyper och esofagit. De filtrerade noggrant bort lågkvalitativa eller felaktigt märkta bilder, ändrade storlek till ett standardformat och förstärkte dem med speglingar, rotationer och ljushetsvariationer så att modellen skulle bli robust mot verkliga variationer. 
Hur AI:n lär sig och fattar beslut
Inuti Vision Transformer omvandlas varje liten bildpatch till en numerisk "token", och lager av attention‑moduler lär sig vilka patchar som bör påverka varandra starkast. Det gör att systemet kan väga avlägsna men relaterade regioner i en enda vy av tarmen, liknande hur en kliniker mentalt kopplar samman mönster över bilden. Teamet finjusterade en förtränad ViT‑B16‑modell med moderna träningsmetoder såsom adaptiv optimering och korsvalidering, och jämförde den sedan med välanvända djupinlärningsarkitekturer som EfficientNet och populära ensemblemetoder med flera nätverk. De använde även förklaringsverktyg som producerar värmekartor och framhäver de exakta regioner i slemhinnan som AI:n fokuserar på när den identifierar ett inflammerat område eller en polyp.
Noggrannhet, förtroende och verklig räckvidd
Vision Transformer uppnådde cirka 99,5 % total noggrannhet på den balanserade testuppsättningen, något bättre än de bästa konkurrerande modellerna och långt över tidigare metoder. För var och en av de fyra klasserna låg precision, recall och F1‑poäng runt 99,4 %, och kurvor som mäter dess förmåga att skilja sjukdomar åt var nästan perfekta. Endast ett fåtal bilder klassificerades fel av tusen testfall. När det tränade systemet utmanades med en extern dataset insamlad under andra förhållanden nådde det fortfarande cirka 96,8 % noggrannhet, vilket visar uppmuntrande generaliseringsförmåga. Visualiseringskartor visade att modellens "attention" klustrade kring kliniskt meningsfulla regioner — såsom ytan på polyper eller inflammerade fläckar — vilket stärker klinikernas förtroende för att AI:n tittar på rätt ställen snarare än på irrelevant bakgrund. 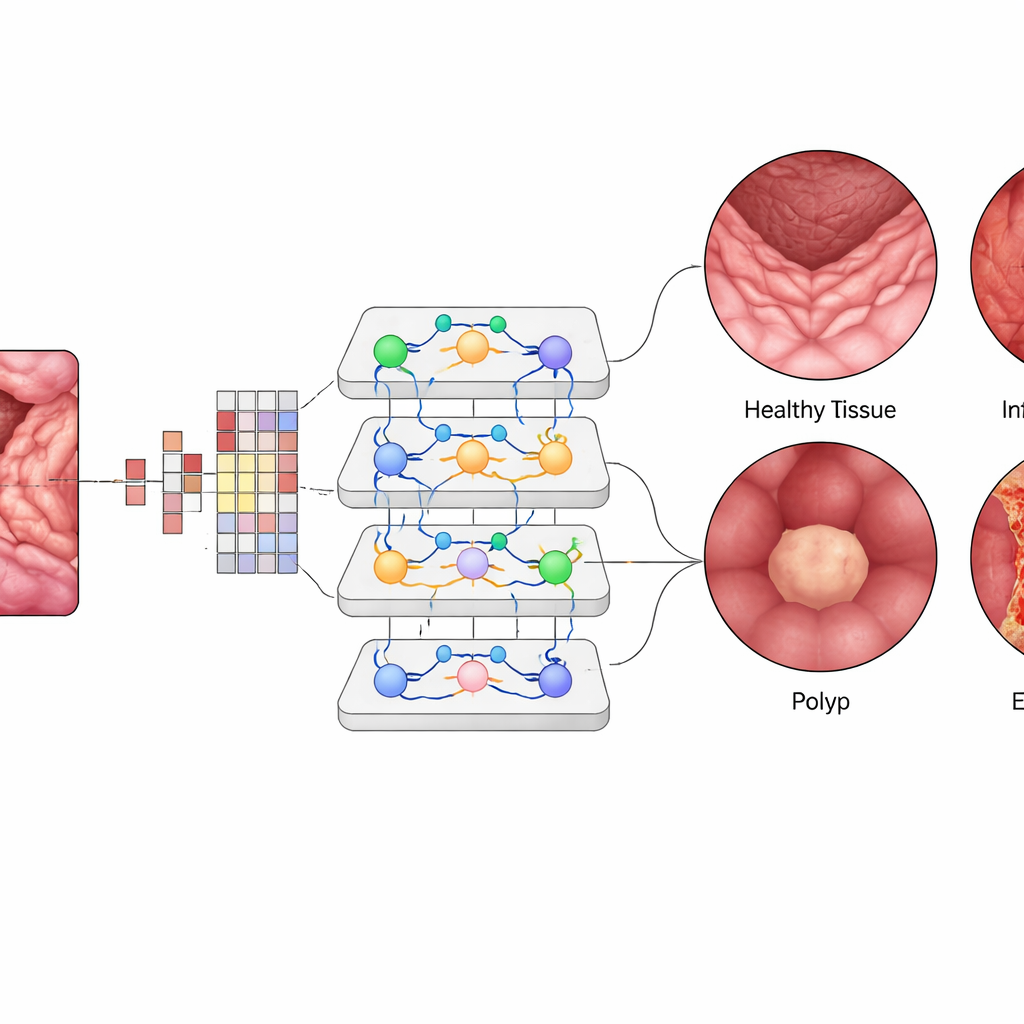
Vad detta betyder för patienter och mottagningar
Studien drar slutsatsen att system baserade på Vision Transformer kan fungera som mycket kapabelt stöd för läkare som tolkar gastrointestinala bilder. Genom att upptäcka subtila avvikelser på ett tillförlitligt och snabbt sätt skulle de kunna möjliggöra tidigare diagnos, mer konsekvent vård mellan sjukhus och färre missade lesioner. Eftersom modellen är tillräckligt effektiv för att köras på standard grafikhårdvara kan den integreras i rutinmässiga screeningsflöden och automatiskt markera bildrutor som förtjänar närmare manuell granskning. Trots att utmaningar kvarstår — såsom att validera prestanda över många sjukhus, hantera sällsynta sjukdomar och ta itu med etiska frågor kring automatiserade diagnoser — tyder detta arbete på att AI‑”medläsare” snart kan bli ett praktiskt verktyg för säkrare och mer hållbar vård inom gastroenterologi.
Citering: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Gastroenterological disease detection using transformer-based medical imaging for sustainable healthcare. Sci Rep 16, 10672 (2026). https://doi.org/10.1038/s41598-026-45222-9
Nyckelord: gastrointestinal bildtagning, vision transformer, endoskopi‑AI, polypdetektion, klassificering av medicinska bilder