Clear Sky Science · zh
通过可解释的机器学习方法对美国区域性玉米产量进行可持续预测
为何预测玉米收成至关重要
玉米处于美国食品体系的核心,既养活人类和牲畜,也可作为燃料来源。但每年农民和政策制定者在做出重要决策时——比如播种多少、储存多少、如何定价——往往无法确切知道会收获多少玉米。随着天气变得更不可预测、市场更易波动,能够准确且可持续地预测区域性玉米产量,对于粮食安全、农场盈利和稳定供应链都变得至关重要。
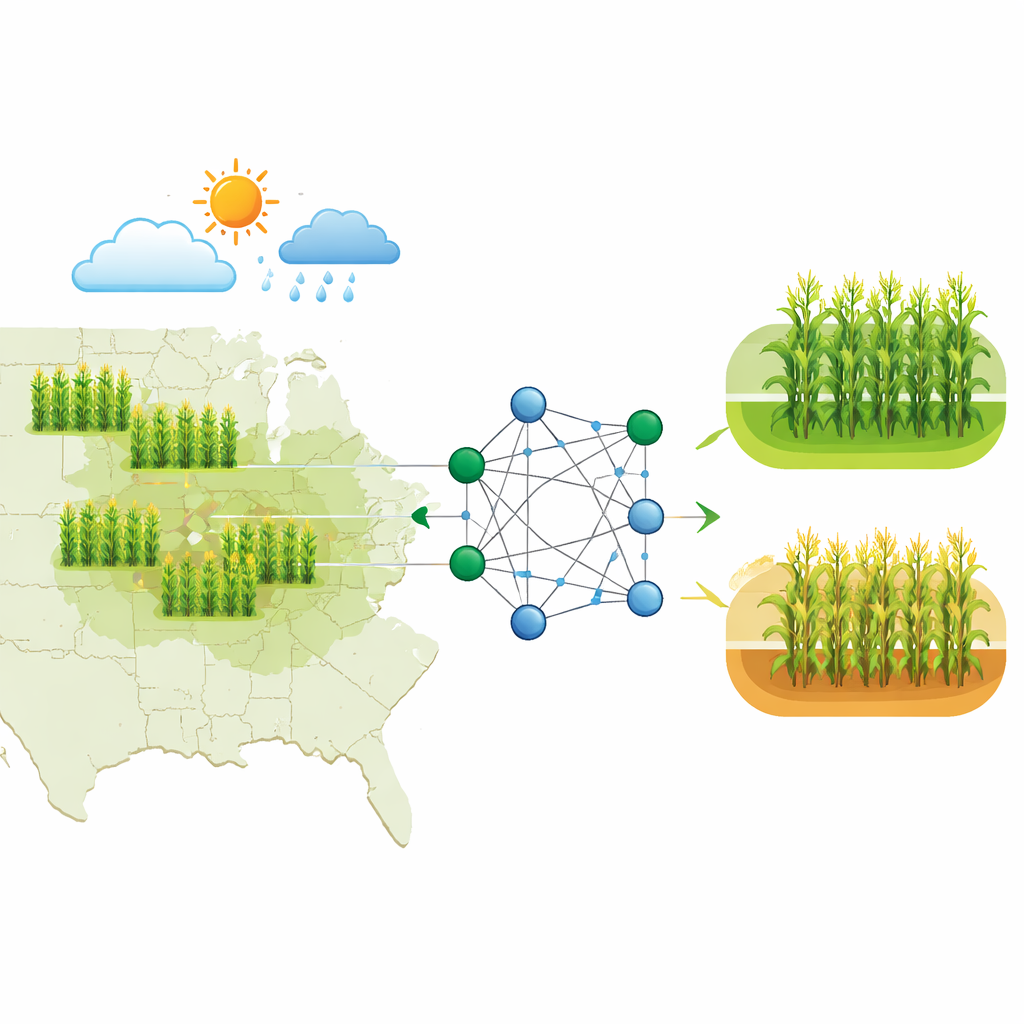
从简单猜测到更智能的预测
几十年来,专家们依赖相对简单的统计工具来预测作物产量,使用过往收成、基本气象数据以及一些土壤信息。这些方法能够捕捉总体趋势,但难以应对今天的现实:海量数据以及气候、土壤健康、管理措施和植物生长之间复杂的非线性关系。本研究填补了这一空白,构建了更强大且可解释的机器学习模型,既能处理丰富的多源数据,又能提供农民、交易员和决策者可以理解和信赖的洞见。
汇集多种数据流
研究者将重点放在美国玉米带的县级玉米产量上,这里的数据可靠且种植面积大,使得区域预测尤其有价值。他们构建了覆盖2010–2020年的综合数据集,融合了多类信息:详尽的气象记录(如降雨、温度、湿度和干旱指标);土壤属性(如土壤类型、含水量和养分水平);基于卫星的植被指数,用于跟踪玉米地随时间的健康状况;以及来自联邦统计的历史县级产量。他们还加入了玉米期货价格数据,作为市场状况的补充信号,同时将预测目标严格限定为农业范畴:判断某县当年产量是否高于或低于其自身历史中位数。
智能模型如何做出判断
为了将这些丰富数据转化为实用预测,团队构建了一个集成模型,结合了两种成熟的机器学习方法:随机森林和梯度提升。这两种方法都擅长在众多变量中发现细微模式,但工作原理不同——一种通过平均许多决策树,另一种通过逐步纠正自身错误。随后通过投票步骤将它们的优势融合为一个关于某县是高产还是低产的最终决策。细致的数据清洗、标准化和特征工程帮助模型识别季节性模式和极端天气事件,而广泛的交叉验证则防止模型简单地记住过去数据。
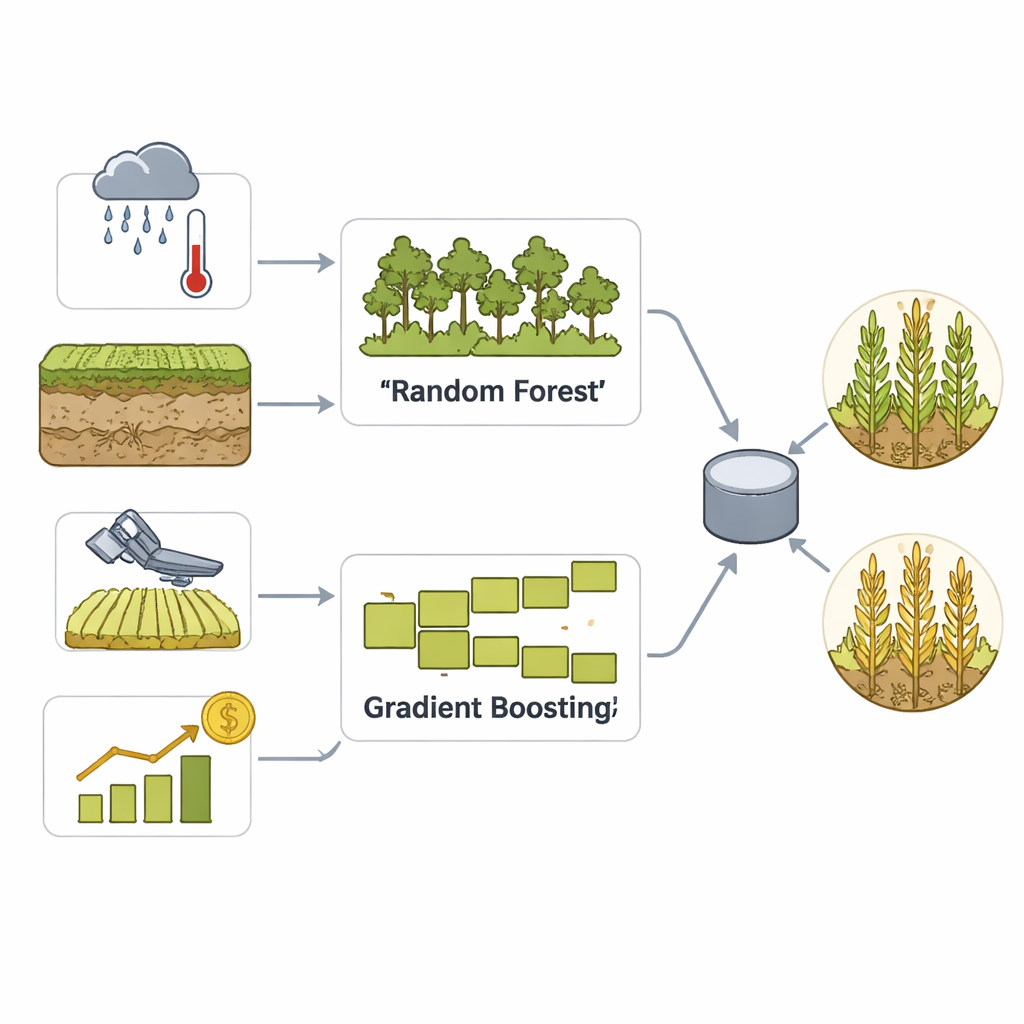
看透“黑箱”内部
先进模型常被诟病:它们可能准确却不透明。为了解决这一问题,作者使用了SHAP(一种现代解释技术),以说明哪些输入对每次预测影响最大。SHAP为每个特征分配贡献分数,展示例如异常降雨模式或植被信号如何将预测推向高产或低产。在本研究中,时间性因素、变化性度量以及基于卫星的植被健康指标成为关键驱动因素。这种透明性使模型不仅仅是一个预测器;它成为决策支持工具,能够指出为何某些地区存在风险以及在何处采取干预(如灌溉、保险或储存规划)可能最为关键。
结果对现实世界的意义
最终模型表现强劲,在区分县级高产与低产年份时,精确率、召回率和测试准确率约为92%,训练数据准确率为97%,表明模型既强大又具有良好泛化能力。市场数据仅略微提升了性能,这表明大部分预测力来自农业学和环境因素,而非金融信号。尽管该方法针对美国玉米带并将产量简化为二元结果,它提供了一种可扩展且节能的方式,将复杂数据转化为可操作的区域预测。对于规划者和供应链管理者而言,这意味着能更早、更可靠地发出缺口或过剩的预警,从而在种植、保险、储存和贸易方面在气候变化背景下作出更明智的决策。
引用: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
关键词: 玉米产量预测, 农业中的机器学习, 遥感数据, 粮食安全, 气候与作物