Clear Sky Science · es
Predicción sostenible del rendimiento regional del maíz en Estados Unidos mediante un enfoque de aprendizaje automático interpretable
Por qué importa predecir las cosechas de maíz
El maíz está en el centro del sistema alimentario estadounidense: alimenta a personas, ganado e incluso abastece combustibles. Pero cada año, agricultores y responsables de políticas deben tomar decisiones importantes—cuánto sembrar, qué almacenar, cómo fijar precios—sin saber con exactitud cuánto maíz se cosechará. A medida que el clima se vuelve más impredecible y los mercados más volátiles, la capacidad de pronosticar con precisión y sostenibilidad los rendimientos regionales de maíz se vuelve crucial para la seguridad alimentaria, la rentabilidad agrícola y la estabilidad de la cadena de suministro.
De conjeturas simples a pronósticos más inteligentes
Durante décadas, los expertos se apoyaron en herramientas estadísticas relativamente simples para predecir rendimientos de cultivos, usando cosechas pasadas, datos meteorológicos básicos y alguna información sobre suelos. Estos métodos captaban tendencias generales pero tenían dificultades con la realidad actual: volúmenes enormes de datos y relaciones complejas y no lineales entre clima, salud del suelo, prácticas de manejo y crecimiento vegetal. El nuevo estudio aborda esta brecha construyendo modelos de aprendizaje automático más potentes pero interpretables, capaces de manejar datos ricos y multisource al tiempo que ofrecen ideas que agricultores, operadores de mercado y responsables de políticas puedan entender y en las que puedan confiar.
Integrando múltiples flujos de datos
Los investigadores se centran en el rendimiento del maíz a nivel de condado en el Corn Belt de Estados Unidos, donde los datos fiables y las grandes superficies sembradas hacen que los pronósticos regionales sean especialmente valiosos. Compilan un conjunto de datos exhaustivo que cubre 2010–2020 y combina varios tipos de información: registros meteorológicos detallados como precipitación, temperatura, humedad e indicadores de sequía; propiedades del suelo como tipo, humedad y niveles de nutrientes; índices de vegetación derivados de satélites que rastrean la salud y el verdor de los cultivos a lo largo del tiempo; y rendimientos históricos por condado procedentes de estadísticas federales. También añaden datos de precios de futuros del maíz como señal complementaria de las condiciones de mercado, manteniendo el objetivo de predicción estrictamente agrícola: si el rendimiento de un condado estará por encima o por debajo de su mediana histórica en un año determinado.
Cómo el modelo inteligente toma su decisión
Para convertir estos datos ricos en pronósticos prácticos, el equipo construye un modelo en ensamblaje que combina dos enfoques consolidados de aprendizaje automático: Random Forest y Gradient Boosting. Ambos son buenos encontrando patrones sutiles entre muchas variables, pero funcionan de manera diferente—uno promedia muchos árboles de decisión y el otro corrige progresivamente sus propios errores. Un paso de votación luego fusiona sus puntos fuertes en una sola decisión sobre si un condado probablemente tendrá un rendimiento alto o bajo. Una limpieza cuidadosa de datos, escalado y ingeniería de características ayuda al modelo a reconocer patrones estacionales y eventos climáticos extremos, mientras que una validación cruzada extensa evita que simplemente memorice el pasado.
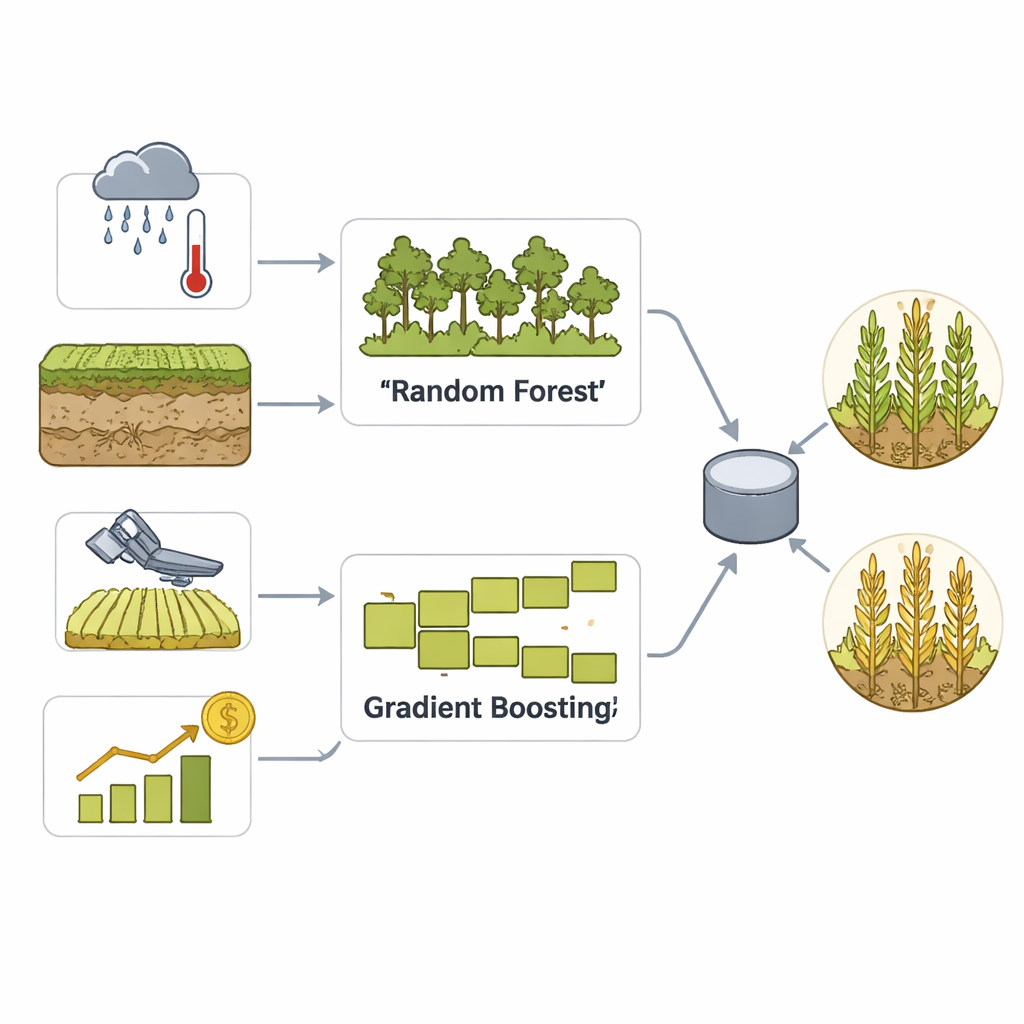
Ver dentro de la caja negra
Los modelos avanzados suelen plantear una preocupación: pueden ser precisos pero opacos. Para abordarlo, los autores usan SHAP, una técnica moderna para explicar qué entradas influyen más en cada predicción. SHAP asigna a cada característica una puntuación de contribución, mostrando, por ejemplo, cómo patrones inusuales de precipitación o señales de vegetación empujan un pronóstico hacia un rendimiento alto o bajo. En este estudio, factores temporales, medidas de variabilidad e indicadores de salud vegetal derivados de satélite emergen como impulsores clave. Esta transparencia convierte al modelo en algo más que un simple predictor: se transforma en una herramienta de apoyo a la decisión que puede resaltar por qué ciertas regiones están en riesgo y dónde intervenciones—como riego, seguros o planificación de almacenamiento—podrían ser más relevantes.
Lo que los resultados significan para el mundo real
El modelo final tiene un buen desempeño, clasificando correctamente años de condado con rendimientos altos frente a bajos con aproximadamente 92% de precisión, recall y exactitud en prueba, y 97% de exactitud en los datos de entrenamiento, lo que indica potencia y buena generalización. Los datos de mercado mejoran el rendimiento solo ligeramente, lo que sugiere que la mayor parte de la capacidad predictiva proviene de factores agronómicos y ambientales más que de señales financieras. Si bien el enfoque está adaptado al Corn Belt estadounidense y simplifica el rendimiento en un resultado binario, ofrece una forma escalable y energéticamente eficiente de convertir datos complejos en pronósticos regionales accionables. Para planificadores y gestores de la cadena de suministro, eso significa advertencias más tempranas y fiables sobre déficits o excedentes, que respaldan decisiones más inteligentes sobre siembra, seguros, almacenamiento y comercio en un clima cambiante.
Cita: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Palabras clave: predicción del rendimiento del maíz, aprendizaje automático en agricultura, datos de teledetección, seguridad alimentaria, clima y cultivos