Clear Sky Science · pl
Zrównoważone regionalne prognozowanie plonów kukurydzy w Stanach Zjednoczonych za pomocą interpretowalnego uczenia maszynowego
Dlaczego prognozowanie zbiorów kukurydzy ma znaczenie
Kukurydza znajduje się w samym centrum amerykańskiego systemu żywnościowego — karmi ludzi, zwierzęta gospodarskie, a nawet zasila samochody. Jednak każdego roku rolnicy i decydenci muszą podejmować ważne decyzje — ile wysiać, co przechować, jak wycenić ziarno — nie znając dokładnie, ile kukurydzy zostanie zebrane. W miarę jak pogoda staje się coraz mniej przewidywalna, a rynki bardziej zmienne, zdolność do dokładnego i zrównoważonego prognozowania regionalnych plonów kukurydzy staje się kluczowa dla bezpieczeństwa żywnościowego, opłacalności gospodarstw i stabilności łańcucha dostaw.
Od prostych szacunków do inteligentniejszych prognoz
Przez dekady eksperci polegali na stosunkowo prostych narzędziach statystycznych do przewidywania plonów, wykorzystując dane historyczne, podstawowe informacje pogodowe i nieco danych o glebach. Metody te uchwycały szerokie trendy, ale miały trudności z rzeczywistością dzisiejszych czasów: ogromnymi wolumenami danych i złożonymi, nieliniowymi zależnościami między klimatem, zdrowiem gleby, praktykami uprawowymi a wzrostem roślin. Nowe badanie wypełnia tę lukę, budując potężniejsze, a jednocześnie interpretowalne modele uczenia maszynowego, które potrafią przetwarzać bogate, wieloźródłowe dane, zachowując przy tym wgląd zrozumiały i godny zaufania dla rolników, handlowców i decydentów.
Łączenie wielu strumieni danych
Naukowcy koncentrują się na plonach kukurydzy na poziomie hrabstw w amerykańskim Corn Belt, gdzie wiarygodne dane i duże areały upraw czynią prognozy regionalne szczególnie wartościowymi. Tworzą kompleksowy zestaw danych obejmujący lata 2010–2020, łączący kilka typów informacji: szczegółowe zapisy pogodowe, takie jak opady, temperatura, wilgotność i wskaźniki suszy; właściwości gleby, takie jak typ, wilgotność i poziomy składników odżywczych; satelitarne wskaźniki wegetacji śledzące zdrowie i zieleń pól kukurydzianych w czasie; oraz historyczne plony hrabstw pochodzące ze statystyk federalnych. Dodają też dane o notowaniach kontraktów terminowych na kukurydzę jako sygnał uzupełniający dotyczący warunków rynkowych, przy czym cel predykcji pozostaje ściśle rolniczy: czy plon danego hrabstwa w danym roku będzie powyżej czy poniżej jego historycznej mediany.
Jak inteligentny model podejmuje decyzję
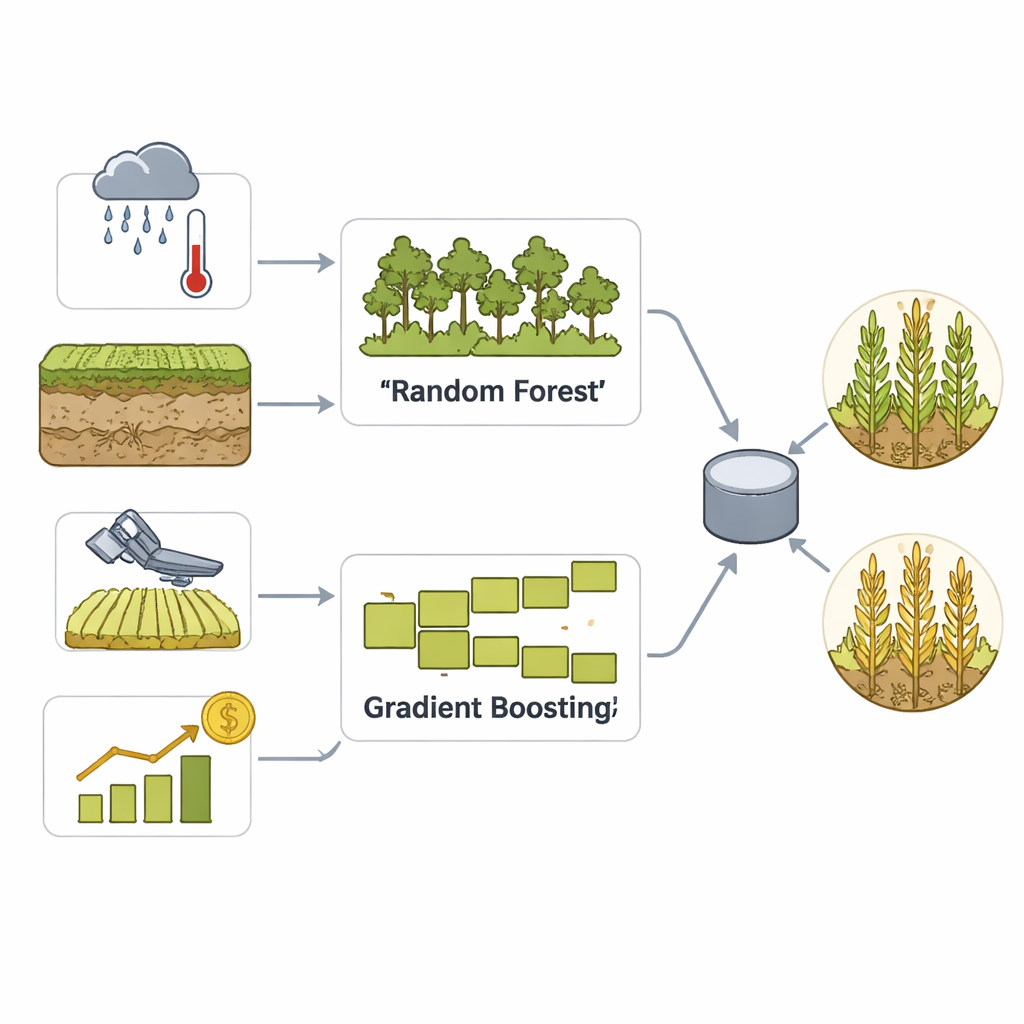
Aby przekształcić te bogate dane w praktyczne prognozy, zespół buduje model zespołowy łączący dwa dobrze ugruntowane podejścia uczenia maszynowego: Random Forest i Gradient Boosting. Oba dobrze odnajdują subtelne wzorce w wielu zmiennych, ale działają inaczej — jeden przez uśrednianie wielu drzew decyzyjnych, drugi przez stopniowe korygowanie własnych błędów. Etap głosowania łączy ich zalety w jedną decyzję o tym, czy hrabstwo prawdopodobnie będzie miało wysoki, czy niski plon. Staranna obróbka danych, skalowanie i inżynieria cech pomagają modelowi rozpoznać wzorce sezonowe i ekstremalne zjawiska pogodowe, a rozbudowana walidacja krzyżowa zapobiega jedynie mechanicznemu „zapamiętaniu” przeszłości.
Wgląd w „czarną skrzynkę”
Zaawansowane modele często budzą obawy: mogą być dokładne, ale nieprzejrzyste. Aby temu zaradzić, autorzy wykorzystują SHAP — nowoczesną technikę wyjaśniania, które wejścia najsilniej wpływają na każdą prognozę. SHAP przypisuje każdej cechy wynikowy wkład, pokazując na przykład, jak nietypowe wzory opadów czy sygnały wegetacyjne przesuwają prognozę w stronę wyższego lub niższego plonu. W badaniu kluczowymi czynnikami okazały się czynniki czasowe, miary zmienności oraz satelitarne wskaźniki stanu roślin. Ta przejrzystość sprawia, że model jest czymś więcej niż prostym predyktorem — staje się narzędziem wspierającym decyzje, które może wskazać, dlaczego określone regiony są narażone i gdzie interwencje — takie jak nawadnianie, ubezpieczenia czy planowanie magazynów — mogą mieć największe znaczenie.
Co wyniki oznaczają w praktyce
Końcowy model działa silnie, klasyfikując poprawnie lata o wysokich i niskich plonach hrabstw z około 92% precyzją, czułością i dokładnością testową, oraz z 97% dokładnością na danych treningowych, co wskazuje zarówno na moc, jak i dobrą generalizację. Dane rynkowe poprawiają wyniki tylko nieznacznie, co sugeruje, że większość siły predykcyjnej pochodzi z czynników agronomicznych i środowiskowych, a nie ze sygnałów finansowych. Chociaż podejście jest dostosowane do amerykańskiego Corn Belt i upraszcza plon do dwu poziomowego wyniku, oferuje skalowalny, energooszczędny sposób przekształcania złożonych danych w użyteczne prognozy regionalne. Dla planistów i menedżerów łańcucha dostaw oznacza to wcześniejsze i bardziej niezawodne ostrzeżenia o niedoborach lub nadwyżkach, wspierające mądrzejsze decyzje dotyczące siewu, ubezpieczeń, przechowywania i handlu w zmieniającym się klimacie.
Cytowanie: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Słowa kluczowe: prognozowanie plonów kukurydzy, uczenie maszynowe w rolnictwie, dane z teledetekcji, bezpieczeństwo żywnościowe, klimat i uprawy