Clear Sky Science · ru
Устойчивое прогнозирование региональной урожайности кукурузы в США с помощью интерпретируемого машинного обучения
Почему важно предсказывать урожай кукурузы
Кукуруза находится в центре продовольственной системы Америки: она кормит людей и скот, а также используется как топливо. Каждый год фермерам и политикам приходится принимать важные решения — сколько сеять, сколько хранить, как формировать цены — не зная наверняка, какой будет фактический сбор. По мере того как погода становится более непредсказуемой, а рынки — более волатильными, способность точно и устойчиво прогнозировать региональную урожайность кукурузы становится критически важной для продовольственной безопасности, доходов фермеров и стабильности цепочки поставок.
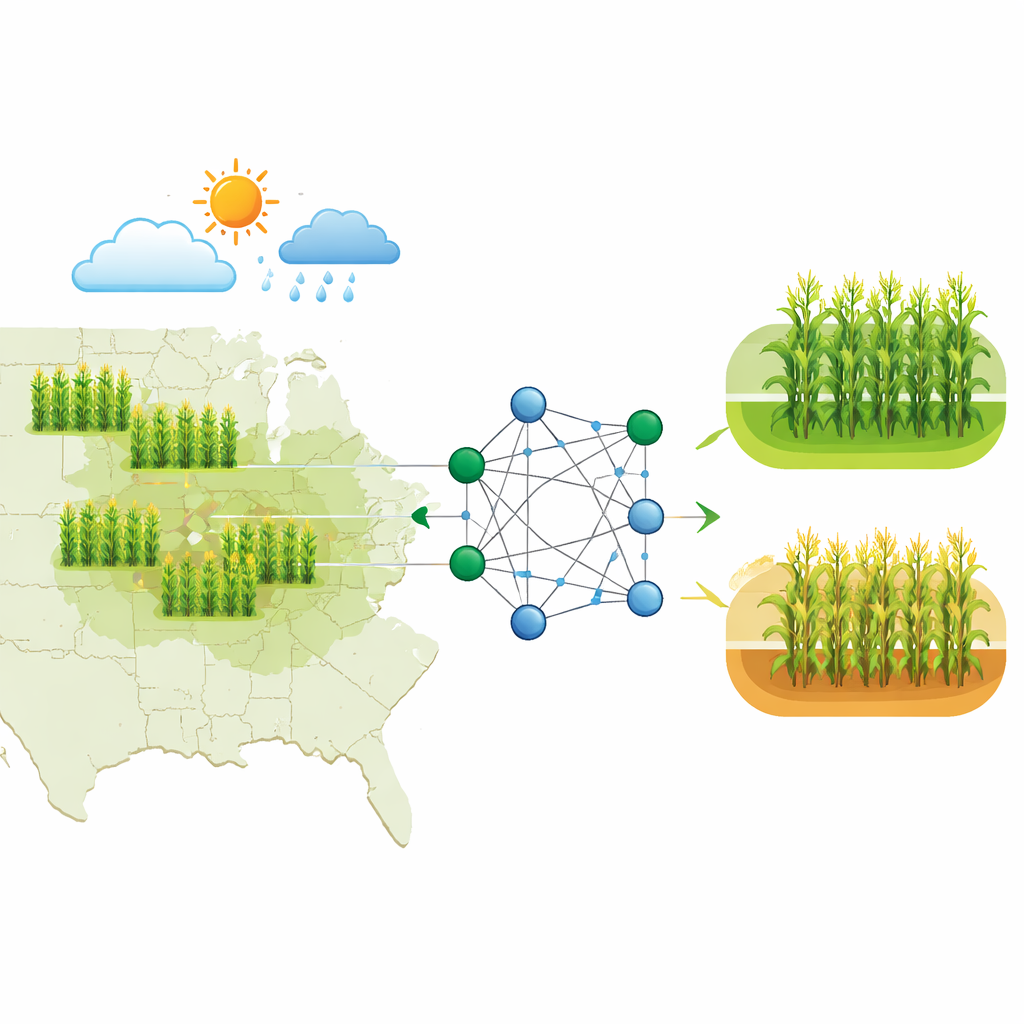
От простых предположений к более умным прогнозам
Десятилетиями эксперты опирались на относительно простые статистические инструменты для прогнозирования урожайности, используя данные прошлых урожаев, базовую метеоинформацию и сведения о почвах. Эти методы улавливали общие тенденции, но плохо справлялись с современной реальностью: огромными объёмами данных и сложными нелинейными связями между климатом, состоянием почв, методами управления и ростом растений. Новое исследование заполняет этот пробел, создавая более мощные, но при этом интерпретируемые модели машинного обучения, способные работать с насыщенными многопоточными данными и одновременно давать понятные и надёжные выводы для фермеров, трейдеров и политиков.
Объединение множества потоков данных
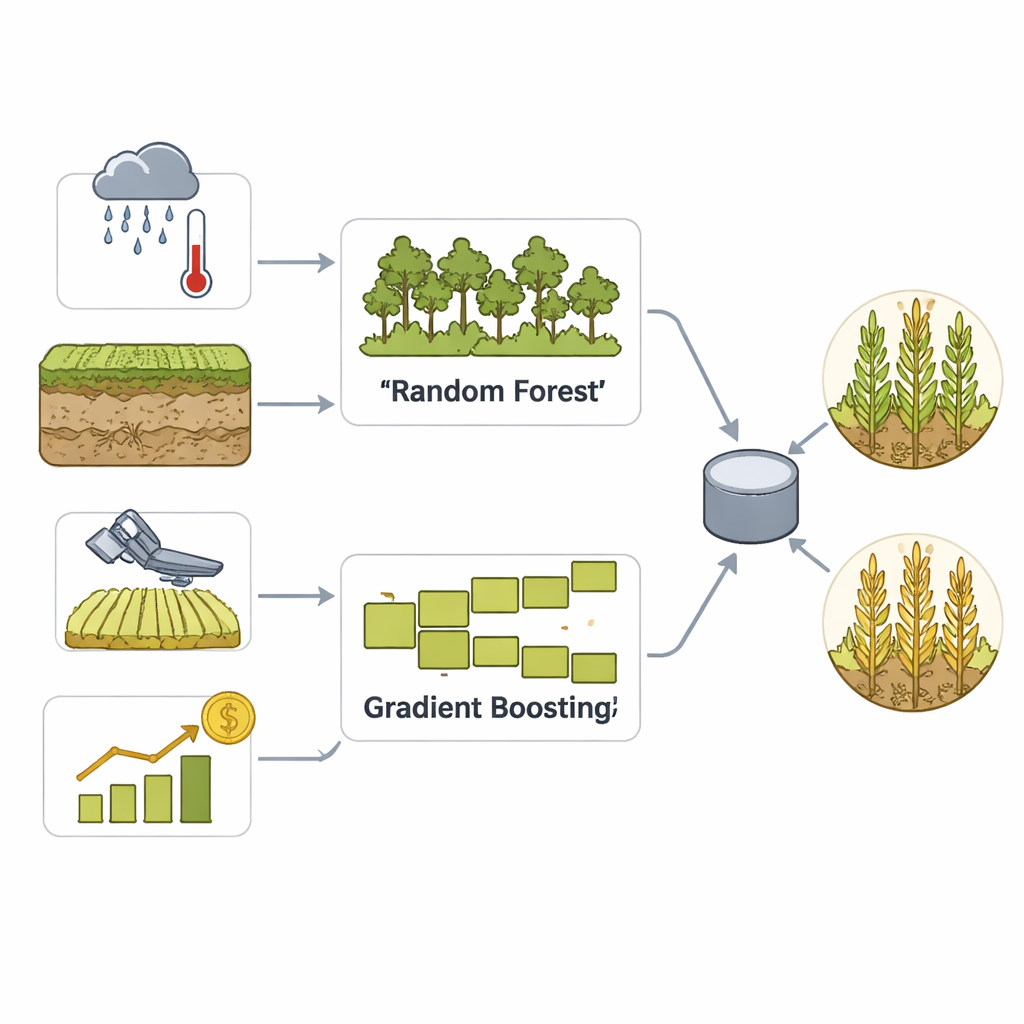
Исследователи сосредотачиваются на уровне округов по урожайности кукурузы в американском кукурузном поясе, где надёжные данные и большие площади посевов делают региональные прогнозы особенно ценными. Они формируют комплексный набор данных за 2010–2020 годы, объединяющий несколько типов информации: подробные погодные записи (осадки, температура, влажность и индикаторы засухи); свойства почв (тип, влажность, уровень питательных веществ); спутниковые вегетационные индексы, отслеживающие состояние и «зелёность» полей во времени; и исторические урожаи по округам из федеральной статистики. В качестве дополнительного сигнала рыночных условий добавлены данные фьючерсов на кукурузу, тогда как сама цель прогноза остаётся строго аграрной: превысит ли урожайность округа в конкретном году собственную историческую медиану.
Как умная модель выносит решение
Чтобы превратить эти богатые данные в практические прогнозы, команда строит ансамблевую модель, сочетающую два хорошо зарекомендовавших себя подхода машинного обучения: случайный лес и градиентный бустинг. Оба хорошо умеют находить тонкие зависимости в множестве переменных, но работают по-разному — один усредняет множество деревьев решений, другой постепенно исправляет собственные ошибки. Шаг голосования затем объединяет их сильные стороны в одно решение о том, будет ли в округе высокий или низкий урожай. Тщательная очистка данных, масштабирование и создание признаков помогают модели распознавать сезонные шаблоны и экстремальные погодные явления, а обширная перекрёстная валидация предотвращает простое «зазубривание» прошлых данных.
Заглянуть внутрь «чёрного ящика»
Продвинутые модели часто вызывают опасения: они могут быть точными, но непрозрачными. Чтобы решить эту проблему, авторы используют SHAP — современную технику объяснения вклада входных переменных в каждое предсказание. SHAP присваивает каждому признаку оценку вклада, показывая, например, как необычные модели осадков или спутниковые сигналы растительности сдвигают прогноз в сторону высокого или низкого урожая. В исследовании ключевыми факторами оказались временные характеристики, меры изменчивости и спутниковые индикаторы здоровья растений. Такая прозрачность делает модель не просто предсказателем, а инструментом поддержки принятия решений, который может выделять регионы с высоким риском и указывать, где вмешательства — например, орошение, страхование или планирование хранения — могут иметь наибольшее значение.
Что результаты означают для практики
Итоговая модель демонстрирует высокую эффективность, корректно классифицируя годы с высоким и низким урожаем по округам примерно с 92% точностью, полнотой и тестовой точностью, а также с 97% точностью на обучающем наборе, что свидетельствует о высокой мощности и хорошей способности к обобщению. Рыночные данные лишь незначительно улучшают показатели, что говорит о том, что основная прогностическая сила исходит из агрономических и экологических факторов, а не финансовых сигналов. Несмотря на то, что подход адаптирован для кукурузного пояса США и упрощает урожай до двухуровневого исхода, он предлагает масштабируемый и энергетически эффективный способ превращения сложных данных в применимые региональные прогнозы. Для планировщиков и менеджеров цепочек поставок это означает более ранние и надёжные предупреждения о дефицитах или избытках, что поддерживает более взвешенные решения по посевам, страхованию, хранению и торговле в условиях меняющегося климата.
Цитирование: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Ключевые слова: прогноз урожая кукурузы, машинное обучение в сельском хозяйстве, данные дистанционного зондирования, продовольственная безопасность, климат и сельское хозяйство