Clear Sky Science · de
Nachhaltige Vorhersage der regionalen Maiserträge in den USA durch einen interpretierbaren Machine-Learning-Ansatz
Warum die Vorhersage von Maisernten wichtig ist
Mais steht im Zentrum des amerikanischen Lebensmittelsystems: Er ernährt Menschen und Nutztiere und dient sogar als Treibstoff. Jedes Jahr müssen Landwirte und politische Entscheidungsträger jedoch weitreichende Entscheidungen treffen – wie viel angebaut, was eingelagert und wie Getreide bepreist werden soll – ohne genau zu wissen, wie viel Mais geerntet wird. Da das Wetter unberechenbarer und die Märkte volatiler werden, wird die Fähigkeit, regionale Maiserträge genau und nachhaltig vorherzusagen, entscheidend für die Ernährungssicherheit, die Rentabilität von Betrieben und eine stabile Lieferkette.
Von einfachen Schätzungen zu besseren Vorhersagen
Jahrzehntelang stützten sich Expertinnen und Experten auf vergleichsweise einfache statistische Werkzeuge zur Ertragsvorhersage, basierend auf vergangenen Ernten, grundlegenden Wetterdaten und einigen Bodeninformationen. Diese Methoden erfassten grobe Trends, hatten aber mit der heutigen Realität zu kämpfen: enormen Datenmengen und komplexen, nichtlinearen Zusammenhängen zwischen Klima, Bodenqualität, Bewirtschaftungspraktiken und Pflanzenwachstum. Die neue Studie schließt diese Lücke, indem sie leistungsfähigere, aber interpretierbare Machine-Learning-Modelle entwickelt, die vielfältige, mehrquellige Daten verarbeiten können und zugleich Einsichten liefern, denen Landwirtinnen, Händler und Entscheidungsträger vertrauen und die sie verstehen können.
Viele Datenströme zusammenführen
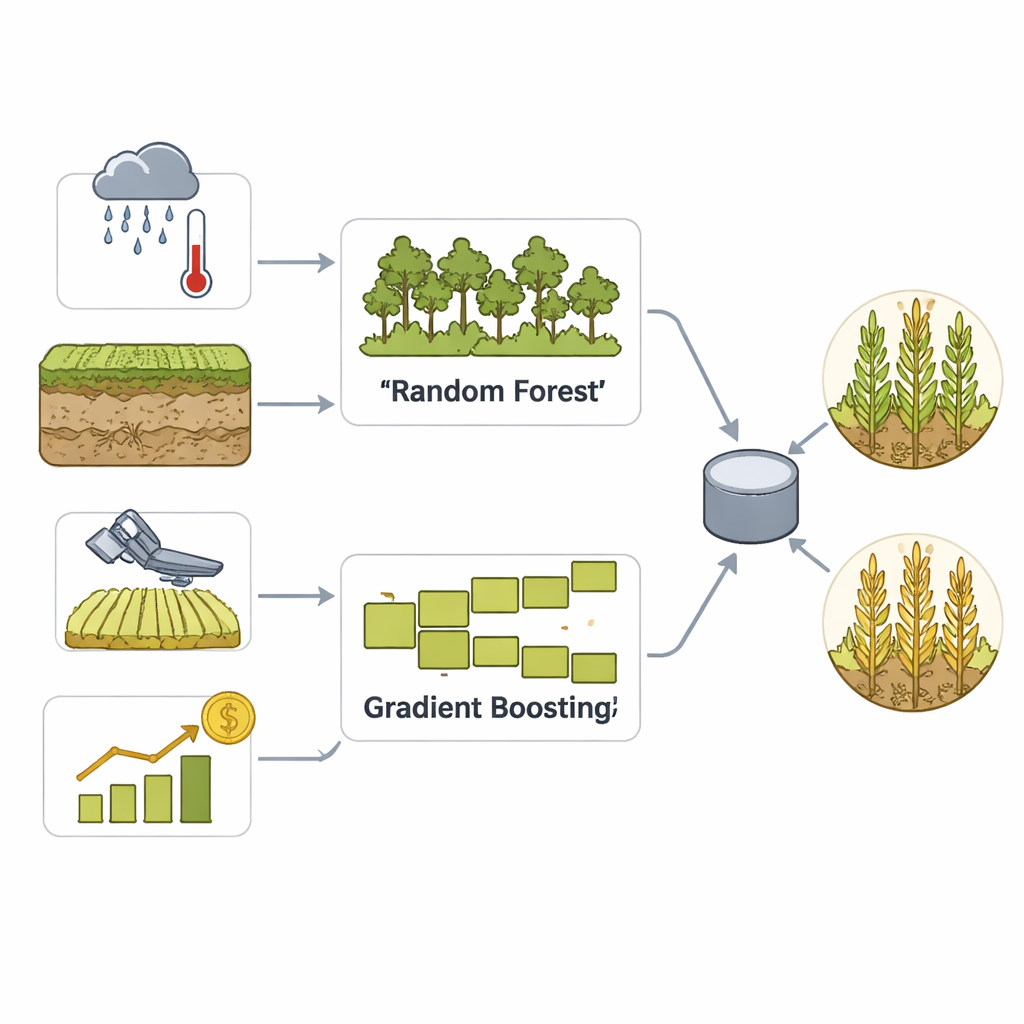
Die Forschenden konzentrieren sich auf Maiserträge auf Landkreisebene im US-Corn-Belt, wo verlässliche Daten und große Anbauflächen regionale Vorhersagen besonders wertvoll machen. Sie stellen einen umfassenden Datensatz für 2010–2020 zusammen, der verschiedene Informationsarten vereint: detaillierte Wetteraufzeichnungen wie Niederschlag, Temperatur, Feuchtigkeit und Dürreindikatoren; Bodeneigenschaften wie Typ, Feuchte und Nährstoffgehalte; satellitengestützte Vegetationsindizes, die die Gesundheit und Grünheit der Maisfelder im Zeitverlauf verfolgen; sowie historische Landkreis-Ertragsdaten aus Bundesstatistiken. Zusätzlich fügen sie Corn-Futures-Preisdaten als ergänzendes Signal zu Marktbedingungen hinzu, wobei das Vorhersageziel strikt landwirtschaftlich bleibt: ob der Ertrag eines Landkreises in einem Jahr über oder unter seinem eigenen historischen Median liegt.
Wie das intelligente Modell seine Entscheidung trifft
Um diese umfangreichen Daten in praktische Vorhersagen zu überführen, baut das Team ein Ensemble-Modell, das zwei etablierte Machine-Learning-Methoden kombiniert: Random Forest und Gradient Boosting. Beide sind gut darin, subtile Muster in vielen Variablen zu erkennen, arbeiten jedoch unterschiedlich – das eine durch das Mittel vieler Entscheidungsbäume, das andere durch schrittweises Korrigieren eigener Fehler. Ein Abstimmungsschritt verbindet dann ihre Stärken zu einer einzigen Entscheidung darüber, ob ein Landkreis voraussichtlich einen hohen oder niedrigen Ertrag haben wird. Sorgfältige Datenbereinigung, Skalierung und Feature-Engineering helfen dem Modell, saisonale Muster und extreme Wetterereignisse zu erkennen, während umfassende Kreuzvalidierung verhindert, dass es bloß die Vergangenheit auswendig lernt.
Ins Schwarze-Box-Modell hineinschauen
Fortgeschrittene Modelle werfen oft die Frage auf: Sie können zwar genau, aber undurchsichtig sein. Um dem zu begegnen, nutzen die Autorinnen und Autoren SHAP, eine moderne Technik, die erklärt, welche Eingaben eine Vorhersage am stärksten beeinflussen. SHAP weist jedem Merkmal einen Beitragsscore zu und zeigt beispielsweise, wie ungewöhnliche Niederschlagsmuster oder Vegetationssignale eine Prognose in Richtung hoher oder niedriger Erträge verschieben. In dieser Studie erweisen sich zeitliche Faktoren, Maße der Variabilität und satellitengestützte Indikatoren der Pflanzenverfassung als Schlüsseltreiber. Diese Transparenz macht das Modell mehr als einen bloßen Prädiktor; es wird zu einem Entscheidungsunterstützungswerkzeug, das aufzeigt, warum bestimmte Regionen gefährdet sind und wo Interventionen – etwa Bewässerung, Versicherungen oder Lagerplanung – besonders wirksam sein könnten.
Was die Ergebnisse für die Praxis bedeuten
Das finale Modell zeigt starke Leistungen: Es klassifiziert Landkreisjahre mit hohen versus niedrigen Erträgen mit etwa 92 % bei Präzision, Rückruf (Recall) und Testgenauigkeit korrekt, und erreicht 97 % Genauigkeit auf den Trainingsdaten, was sowohl Leistungsfähigkeit als auch gute Verallgemeinerung anzeigt. Marktdaten verbessern die Leistung nur geringfügig, was darauf hindeutet, dass die meiste Vorhersagekraft aus agronomischen und umweltbezogenen Faktoren statt aus finanziellen Signalen stammt. Obwohl der Ansatz auf den US-Corn-Belt zugeschnitten ist und den Ertrag auf ein zweistufiges Ergebnis vereinfacht, bietet er einen skalierbaren, energieeffizienten Weg, komplexe Daten in umsetzbare regionale Prognosen zu verwandeln. Für Planerinnen, Planer und Lieferkettenmanager bedeutet das frühere und verlässlichere Warnungen vor Knappheiten oder Überschüssen und unterstützt klügere Entscheidungen zu Aussaat, Versicherung, Lagerung und Handel in einem sich wandelnden Klima.
Zitation: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Schlüsselwörter: Prognose von Maiserträgen, Machine Learning in der Landwirtschaft, Fernerkundungsdaten, Lebensmittelsicherheit, Klima und Kulturpflanzen