Clear Sky Science · he
חיזוי בר-קיימא של יבול התירס האזורי בארצות הברית באמצעות גישת למידת מכונה מפוענחת
מדוע חיזוי יבולי תירס חשוב
התירס עומד במרכז מערכת המזון של אמריקה — מזין אנשים, בעלי חיים ואפילו משמש כדלק. בכל שנה נדרשים החקלאים ומקבלי ההחלטות להחליט החלטות גדולות — כמה לזרוע, מה לאחסן וכיצד לתמחר דגנים — ללא ידיעה מדויקת כמה תירס ייגבה. ככל שהמזג אוויר הופך לבלתי צפוי יותר והשווקים לסוערים יותר, היכולת לחזות במדויק ובאופן בר-קיימא יבולי תירס אזוריים נעשית חיונית לביטחון מזון, לרווחיות החקלאית וליציבות שרשרת האספקה.
מתחזיות פשוטות לתחזיות חכמות יותר
עשרות שנים נעזרו מומחים בכלים סטטיסטיים יחסית פשוטים כדי לחזות יבולים, בהתבסס על קצירים קודמים, נתוני מזג אוויר בסיסיים ומידע מסוים על הקרקע. שיטות אלה תפסו מגמות רחבות אך התקשו להתמודד עם המציאות של ימינו: נפחי נתונים עצומים ויחסי גומלין מורכבים ולא ליניאריים בין אקלים, בריאות הקרקע, פרקטיקות ניהוליות וצמיחת הצמח. המחקר החדש נכנס לפער הזה על ידי בניית מודלים של למידת מכונה חזקים ובו בזמן מפוענחים, שיכולים לטפל בנתונים עשירים ממקורות מרובים ועדיין להציע תובנות שחקלאים, סוחרים ומקבלי החלטות יכולים להבין ולהסתמך עליהן.
מיזוג זרמי נתונים מרובים
החוקרים מתמקדים ביבולי תירס ברמת המחוז באזור חוג התירס של ארה"ב, שם קיימים נתונים אמינים ואזורים מושקים נרחבים שהופכים תחזיות אזוריות ליקרות ערך במיוחד. הם מרכיבים מאגר נתונים מקיף המכסה את השנים 2010–2020 ומשלב מספר סוגי מידע: רישומי מזג אוויר מפורטים כגון גשם, טמפרטורה, לחות ומדדי בצורת; מאפייני קרקע כמו סוג, לחות ורמות מזון; אינדקסי צמחייה מבוססי לווין שמנטרים את בריאות וטיב השטחים לאורך זמן; ויבולי מחוז היסטוריים מתוך סטטיסטיקה פדרלית. בנוסף הם מוסיפים נתוני מחירי חוזי עתיד לתירס כאות משלים למצב השוק, תוך שהיעד החיזוי נשאר חקלאי במובהק: האם יבול מחוזי יהיה מעל או מתחת למדד החציון ההיסטורי שלו בשנה נתונה.
כיצד המודל החכם מקבל החלטה
כדי להפוך את מאגר הנתונים העשיר הזה לתחזיות מעשיות, הצוות בונה מודל אנסמבל שמשלב שתי גישות למידת מכונה מבוססות היטב: Random Forest ו-Gradient Boosting. שתיהן טובות בזיהוי דפוסים עדינים בין משתנים רבים, אך פועלות בדרכים שונות — האחת על ידי ממוצע של עצי החלטה רבים, והשנייה על ידי תיקון השגיאות שלה בהדרגה. שלב הצבעה מאחד אז את חוזקותיהן להחלטה בודדת לגבי האם סביר כי יבול מחוז יהיה גבוה או נמוך. ניקוי נתונים קפדני, קנה מידה ומהנדסי תכונות מסייעים למודל לזהות דפוסים עונתיים ואירועי קיצון במזג האוויר, בעוד שצליבת אימות נרחבת מונעת ממנו פשוט לשנן את העבר.
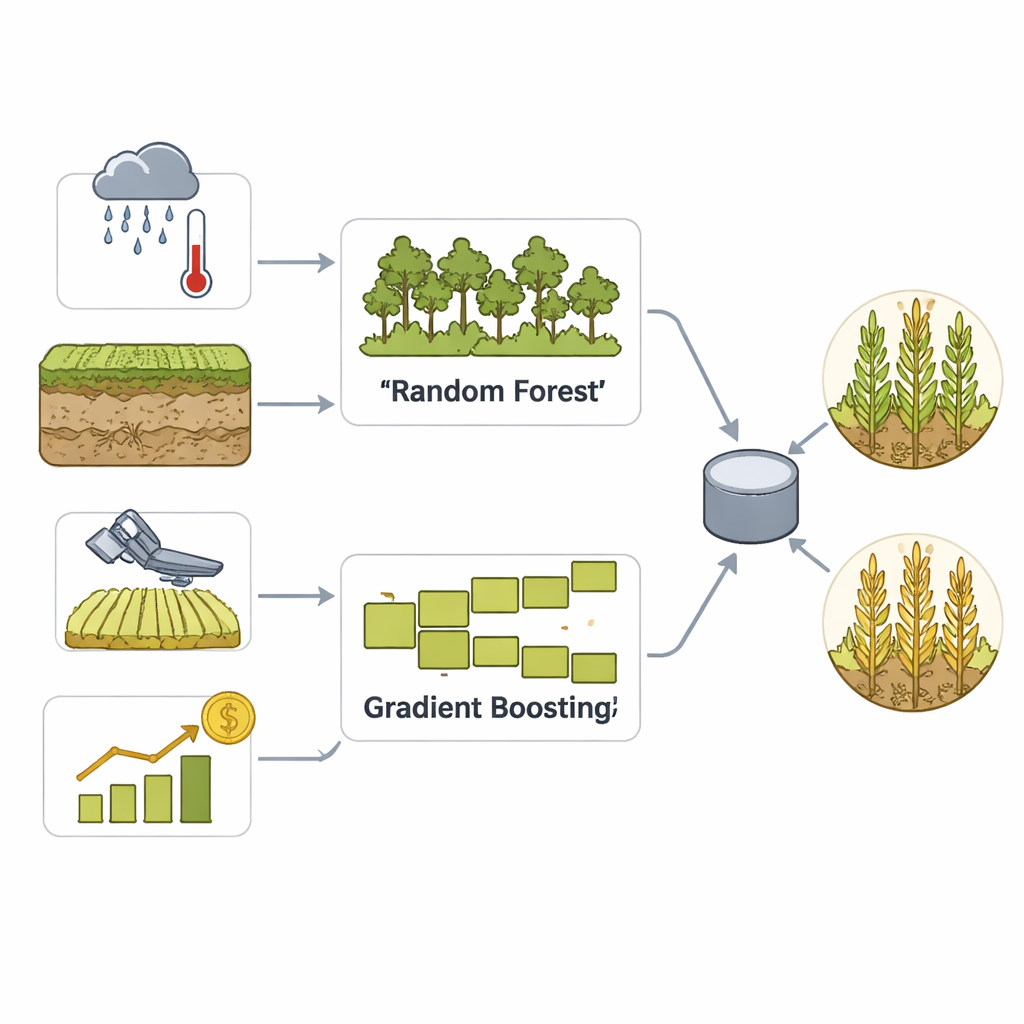
להביט בתוך הקופסה השחורה
מודלים מתקדמים מייצרים לעתים דאגה: הם יכולים להיות מדויקים אך אטומים להבנה. כדי לטפל בכך, המחברים משתמשים ב-SHAP, טכניקה מודרנית שמסבירה אילו קלטים משפיעים ביותר על כל תחזית. SHAP מקצה לכל תכונה ציון תרומה, ומראה, למשל, כיצד דפוסי גשם לא שגרתיים או אותות צמחייה דוחפים תחזית לעבר יבול גבוה או נמוך. במחקר זה, גורמים זמניים, מדדי שונות ואינדקסי בריאות צמחייה מלוויין בולטים כגורמים מרכזיים. שקיפות זו הופכת את המודל ליותר מסתם מנבא; הוא הופך לכלי תמיכה בהחלטות שיכול להדגיש מדוע אזורים מסוימים בסיכון והיכן התערבויות — כגון השקיה, ביטוח או תכנון אחסון — עשויות להיות החשובות ביותר.
מה המשמעות של התוצאות בעולם האמיתי
המודל הסופי מבצע היטב, ומסווג נכונה שנים של מחוזות כבעלי יבול גבוה לעומת נמוך בקירוב של כ-92% דיוק, שליפה (recall) ודיוק במבחן, ו-97% דיוק על נתוני האימון, מעיד על כוח ועל הכללה טובה. נתוני השוק משפרים את הביצועים במעט בלבד, מה שמרמז שרוב כוח הניבוי נובע מפקטורים חקלאיים וסביבתיים ולא מאותות פיננסיים. בעוד שהשיטה מותאמת לחוג התירס של ארה"ב ומפשטת את היבול לתוצאה דו-רמתית, היא מציעה דרך מדרגת ויעילה אנרגטית להפוך נתונים מורכבים לתחזיות אזוריות שניתן לנקוט לפיהן. עבור מתכננים ומנהלי שרשרות אספקה, משמעות הדבר היא אזהרות מוקדמות ומהימנות יותר על מחסורים או עודפים, התומכות בהחלטות חכמות יותר לגבי זריעה, ביטוח, אחסון וסחר בעידן של אקלים משתנה.
ציטוט: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
מילות מפתח: חיזוי יבול תירס, למידת מכונה בחקלאות, נתוני חישה מרחוק, ביטחון מזון, אקלים וגידולים