Clear Sky Science · sv
Hållbar regional majsavkastningsprognos för USA genom tolkbar maskininlärningsmetod
Varför det är viktigt att förutsäga majs skördar
Majs står i centrum för USA:s livsmedelssystem och föder både människor, boskap och driver till och med fordon. Men varje år måste bönder och beslutsfattare fatta stora beslut – hur mycket som ska odlas, vad som ska lagras och hur spannmålet ska prissättas – utan att veta exakt hur mycket majs som kommer att skördas. När vädret blir mer oförutsägbart och marknaderna mer volatila blir förmågan att noggrant och hållbart prognostisera regionala majsavkastningar avgörande för livsmedelssäkerhet, jordbruksekonomi och en stabil leveranskedja.
Från enkla gissningar till smartare prognoser
I årtionden har experter förlitat sig på relativt enkla statistiska verktyg för att förutsäga grödavkastningar, med hjälp av tidigare skördar, grundläggande väderdata och viss information om jordar. Dessa metoder fångade breda trender men hade svårt att hantera dagens verklighet: enorma datamängder och komplexa, icke-linjära samband mellan klimat, jordhälsa, skötsel och växttillväxt. Den nya studien fyller detta gap genom att bygga kraftfullare men tolkbara maskininlärningsmodeller som kan hantera rik, mångkällig data samtidigt som de erbjuder insikter som bönder, handlare och beslutsfattare kan förstå och lita på.
Att föra samman många datakällor
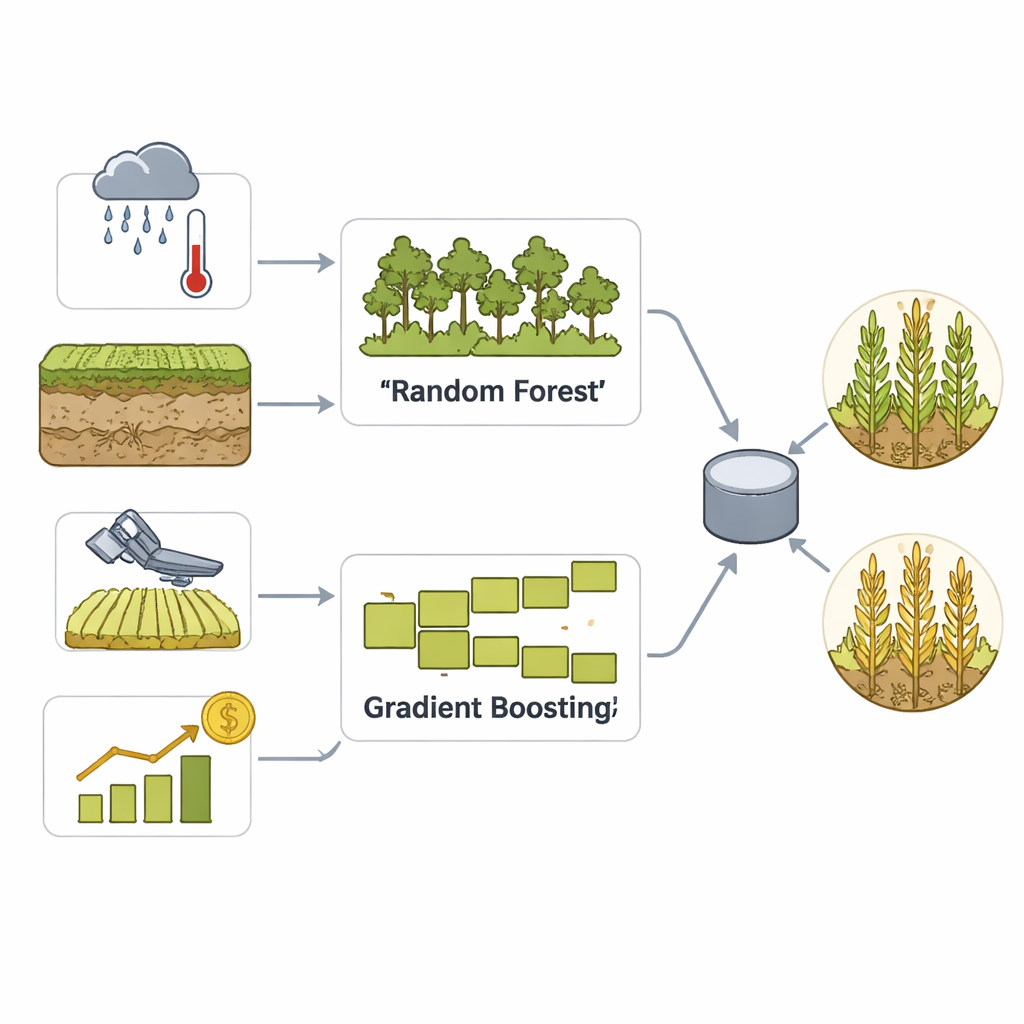
Forskarlaget fokuserar på majsavkastning på länsnivå över USA:s Corn Belt, där pålitliga data och stora odlingsarealer gör regionala prognoser särskilt värdefulla. De sammanställer en omfattande datamängd för åren 2010–2020 som blandar flera typer av information: detaljerade väderregister såsom nederbörd, temperatur, luftfuktighet och torkindikatorer; jordegenskaper som typ, fuktighet och näringsnivåer; satellitbaserade vegetationsindex som följer hur friska och gröna majsfälten är över tiden; samt historiska länsavkastningar från federala statistiska källor. De lägger också till terminsprisdata för majs som en kompletterande signal om marknadsförhållanden, samtidigt som prognosmålet hålls strikt agrikulturellt: om ett läns avkastning ett givet år kommer att vara över eller under dess egen historiska median.
Hur den intelligenta modellen fattar sitt beslut
För att omvandla denna rika data till praktiska prognoser bygger teamet en ensemblemodell som kombinerar två väletablerade maskininlärningsmetoder: Random Forest och Gradient Boosting. Båda är bra på att hitta subtila mönster i många variabler, men de fungerar på olika sätt – den ena genom att medelvärdesbilda många beslutsträd, den andra genom att gradvis rätta sina egna fel. Ett omröstningssteg blandar sedan deras styrkor till ett enda beslut om ett län sannolikt får hög eller låg avkastning. Noggrann datarensning, skalning och feature-engineering hjälper modellen att känna igen säsongsmönster och extrema väderhändelser, medan omfattande korsvalidering hindrar den från att enbart memorera historiken.
Se in i den svarta lådan
Avancerade modeller väcker ofta en oro: de kan vara precisa men ogenomskinliga. För att hantera detta använder författarna SHAP, en modern teknik för att förklara vilka indata som mest påverkar varje prognos. SHAP tilldelar varje variabel en bidragspoäng och visar till exempel hur ovanliga nederbördsmönster eller vegetationssignaler skjuter en prognos mot högre eller lägre avkastning. I denna studie framträder tidsmässiga faktorer, mått på variabilitet och satellitbaserade indikatorer på växthälsa som viktiga drivkrafter. Denna transparens gör modellen till mer än enbart en prediktor; den blir ett beslutsstödsverktyg som kan belysa varför vissa regioner är i riskzonen och var insatser – såsom bevattning, försäkring eller lagerplanering – kan vara mest betydelsefulla.
Vad resultaten betyder i verkligheten
Den slutliga modellen presterar starkt och klassificerar korrekt hög- respektive lågavkastningsår för län med cirka 92 % precision, recall och testnoggrannhet, och 97 % noggrannhet på träningsdata, vilket indikerar både kraft och god generaliseringsförmåga. Marknadsdata förbättrar prestandan endast marginellt, vilket tyder på att den mesta prediktiva styrkan kommer från agronomiska och miljömässiga faktorer snarare än finansiella signaler. Även om tillvägagångssättet är anpassat till den amerikanska Corn Belt och förenklar avkastning till ett tvånivåutfall, erbjuder det ett skalbart, energieffektivt sätt att omvandla komplex data till användbara regionala prognoser. För planerare och leverantörskedjeansvariga betyder det tidigare och mer tillförlitliga varningar om underskott eller överskott, vilket stödjer smartare beslut om sådd, försäkring, lagring och handel i ett föränderligt klimat.
Citering: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Nyckelord: prognos för majsavkastning, maskininlärning inom jordbruket, fjärranalysdata, livsmedelssäkerhet, klimat och grödor