Clear Sky Science · nl
Duurzame regionale voorspelling van maïsopbrengst voor de Verenigde Staten met een interpreteerbare machine learning-benadering
Waarom het voorspellen van maïsopbrengsten ertoe doet
Maïs staat centraal in het Amerikaanse voedselsysteem: het voedt mensen, vee en zelfs auto's. Toch moeten boeren en beleidsmakers elk jaar grote beslissingen nemen — hoeveel te zaaien, wat op te slaan, hoe graan te prijzen — zonder precies te weten hoeveel maïs er geoogst zal worden. Nu het weer onvoorspelbaarder wordt en markten volatieler, wordt het vermogen om regionale maïsopbrengsten nauwkeurig en duurzaam te voorspellen cruciaal voor voedselzekerheid, boerderijinkomsten en een stabiele bevoorradingsketen.
Van eenvoudige inschattingen naar slimmere voorspellingen
Decennialang vertrouwden deskundigen op relatief eenvoudige statistische hulpmiddelen om opbrengsten te voorspellen, gebruikmakend van eerdere oogsten, basisweerdata en enige informatie over bodems. Deze methoden vingen brede trends, maar hadden moeite met de realiteit van vandaag: enorme hoeveelheden data en complexe, niet-lineaire relaties tussen klimaat, bodemgezondheid, beheerspraktijken en plantengroei. De nieuwe studie vult dit gat door krachtigere maar interpreteerbare machine learning-modellen te bouwen die met rijke, meervoudige gegevensbronnen kunnen omgaan en tegelijk inzichten bieden die boeren, handelaren en beleidsmakers kunnen begrijpen en vertrouwen.
Veel datastromen samenbrengen
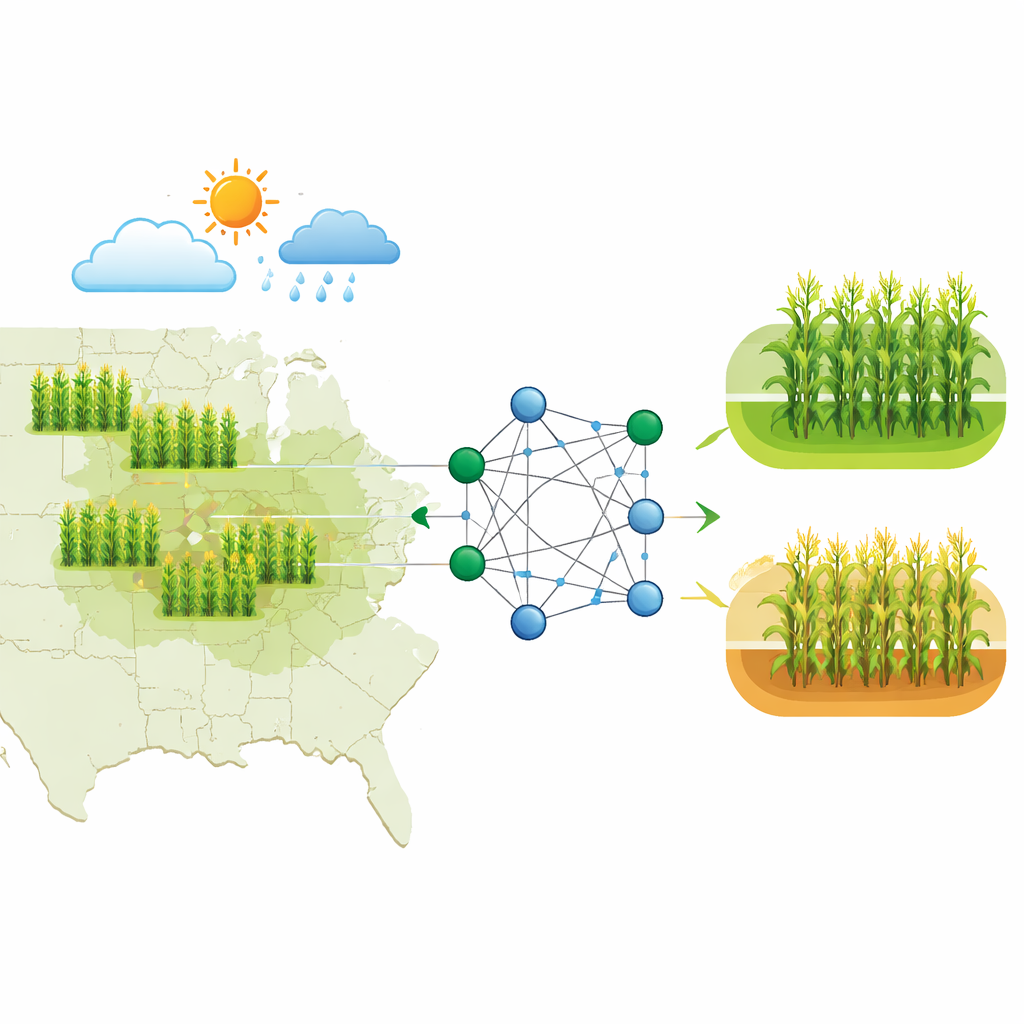
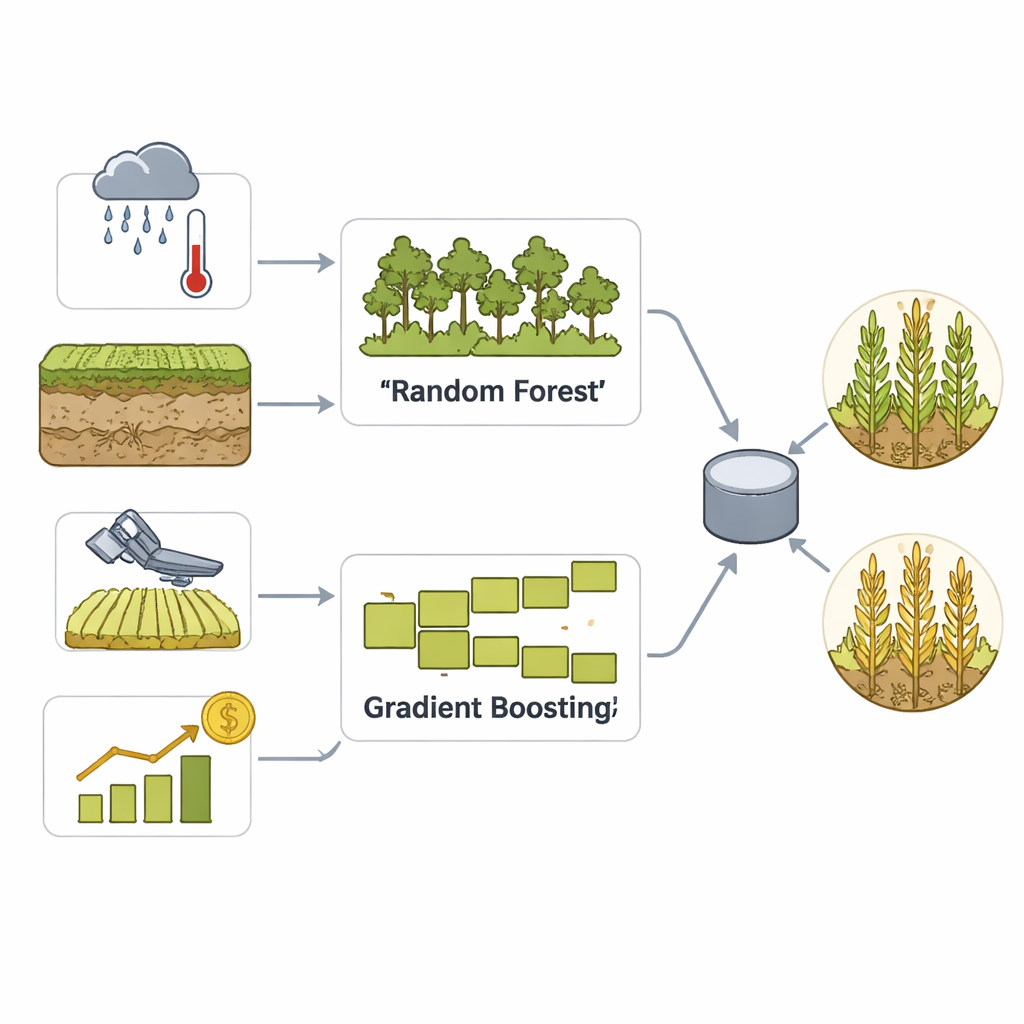
De onderzoekers richten zich op maïsopbrengst op county-niveau in de Amerikaanse Corn Belt, waar betrouwbare gegevens en grote aangeplante oppervlaktes regionale voorspellingen bijzonder waardevol maken. Ze stellen een uitgebreide dataset samen voor 2010–2020 die meerdere typen informatie combineert: gedetailleerde weerdossiers zoals neerslag, temperatuur, luchtvochtigheid en droogte-indicatoren; bodemkenmerken zoals type, vocht en nutriëntenniveaus; satelliet-gebaseerde vegetatie-indexen die bijhouden hoe gezond en groen maïspercelen in de loop van de tijd zijn; en historische county-opbrengsten uit federale statistieken. Daarnaast voegen ze maïsfutures-prijsgegevens toe als een aanvullende marktsignaal, terwijl het voorspellingsdoel strikt agrarisch blijft: of de opbrengst van een county in een bepaald jaar boven of onder zijn eigen historische mediaan zal liggen.
Hoe het slimme model zijn beslissing neemt
Om deze rijke gegevens in praktische voorspellingen om te zetten, bouwen de onderzoekers een ensemblemodel dat twee goed gevestigde machine learning-benaderingen combineert: Random Forest en Gradient Boosting. Beide zijn goed in het vinden van subtiele patronen in veel variabelen, maar werken op verschillende manieren: de ene door het middelen van vele beslisregels, de andere door geleidelijk zijn eigen fouten te corrigeren. Een stemprocedure mengt vervolgens hun sterke punten tot één beslissing over of een county waarschijnlijk een hoge of lage opbrengst zal hebben. Zorgvuldige datavoorbereiding, schaling en feature-engineering helpen het model seizoenspatronen en extreme weersgebeurtenissen te herkennen, terwijl uitgebreide cross-validatie voorkomt dat het eenvoudigweg het verleden uit het hoofd leert.
Inzicht in het zwarte doos-model
Geavanceerde modellen roepen vaak een zorg op: ze kunnen nauwkeurig maar ondoorzichtig zijn. Om dit te tackelen gebruiken de auteurs SHAP, een moderne techniek om uit te leggen welke invoeren de grootste invloed hebben op elke voorspelling. SHAP kent elke feature een bijdragen-score toe en toont bijvoorbeeld hoe ongewone neerslagpatronen of vegetatiesignalen een voorspelling richting hoge of lage opbrengst duwen. In deze studie blijken temporele factoren, maatstaven voor variabiliteit en satellietgebaseerde indicatoren van plantgezondheid sleuteldrivers te zijn. Deze transparantie maakt het model meer dan een loutere voorspeller; het wordt een beslissingsondersteunend instrument dat kan benadrukken waarom bepaalde regio's risico lopen en waar interventies — zoals irrigatie, verzekeringen of opslagplanning — het meest van belang kunnen zijn.
Wat de resultaten in de praktijk betekenen
Het uiteindelijke model presteert sterk en klasseert hoge versus lage opbrengst-jaren op county-niveau met ongeveer 92% precisie, recall en testnauwkeurigheid, en 97% nauwkeurigheid op trainingsgegevens, wat zowel kracht als goede generalisatie aangeeft. Marktgegevens verbeteren de prestatie slechts marginaal, wat suggereert dat de meeste voorspellende kracht voortkomt uit agronomische en milieufactoren in plaats van financiële signalen. Hoewel de aanpak is afgestemd op de Amerikaanse Corn Belt en opbrengst vereenvoudigt tot een tweedelig resultaat, biedt het een schaalbare, energie-efficiënte manier om complexe data om te zetten in bruikbare regionale voorspellingen. Voor planners en supply chain-managers betekent dat eerdere en betrouwbaardere waarschuwingen over tekorten of overschotten, en daarmee slimmere beslissingen over zaaien, verzekeringen, opslag en handel in een veranderend klimaat.
Bronvermelding: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Trefwoorden: voorspelling maïsopbrengst, machine learning in de landbouw, gegevens van remote sensing, voedselzekerheid, klimaat en gewassen