Clear Sky Science · it
Previsione sostenibile della resa regionale del mais negli Stati Uniti attraverso un approccio interpretabile di machine learning
Perché prevedere i raccolti di mais è importante
Il mais è al centro del sistema alimentare americano: nutre persone e bestiame ed è persino impiegato per alimentare i veicoli. Ma ogni anno agricoltori e decisori politici devono prendere scelte importanti — quanto seminare, cosa stoccare, come fissare i prezzi — senza sapere con esattezza quanto mais sarà raccolto. Con un clima sempre meno prevedibile e mercati più volatili, la capacità di prevedere con precisione e in modo sostenibile le rese regionali del mais diventa cruciale per la sicurezza alimentare, i profitti agricoli e la stabilità della filiera.
Dalle semplici ipotesi a previsioni più intelligenti
Per decenni gli esperti si sono affidati a strumenti statistici relativamente semplici per prevedere le rese, usando raccolti passati, dati meteorologici basilari e qualche informazione sui suoli. Questi metodi coglievano le tendenze generali ma faticavano ad affrontare la realtà odierna: enormi volumi di dati e relazioni complesse non lineari tra clima, salute del suolo, pratiche di gestione e crescita delle piante. Il nuovo studio colma questa lacuna costruendo modelli di machine learning più potenti ma interpretabili, in grado di gestire dati ricchi e multisorgente offrendo comunque intuizioni che agricoltori, operatori di mercato e responsabili politici possono comprendere e a cui possono affidarsi.
Integrare molteplici flussi di dati
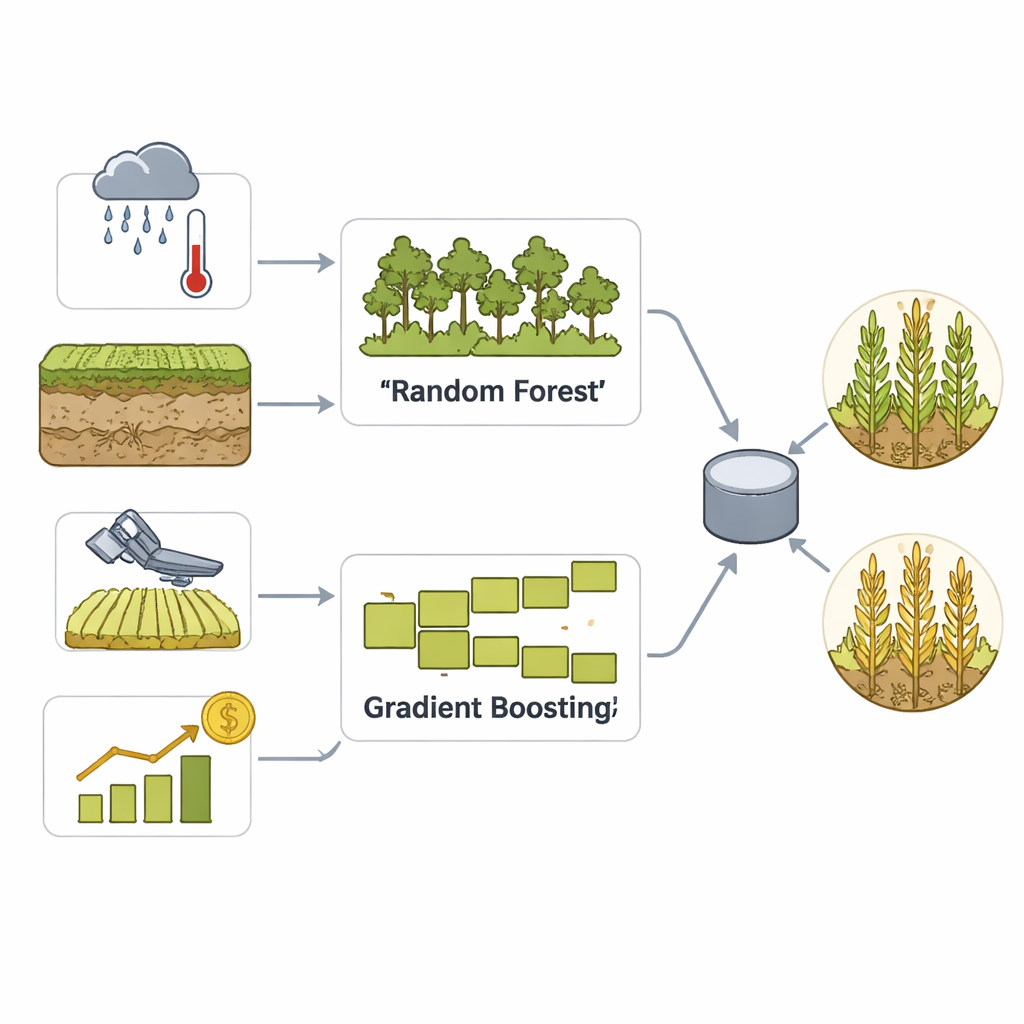
I ricercatori si concentrano sulla resa del mais a livello di contea nella Corn Belt degli Stati Uniti, dove dati affidabili e vaste aree coltivate rendono le previsioni regionali particolarmente utili. Compilano un dataset completo che copre il periodo 2010–2020 e combina diversi tipi di informazioni: registrazioni meteorologiche dettagliate come precipitazioni, temperatura, umidità e indicatori di siccità; proprietà del suolo come tipo, contenuto d’acqua e livelli di nutrienti; indici di vegetazione derivati da satellite che monitorano nel tempo lo stato di salute e il vigore delle colture; e rese storiche a livello di contea tratte dalle statistiche federali. Aggiungono anche i dati dei futures sul mais come segnale complementare delle condizioni di mercato, mantenendo però l’obiettivo della previsione strettamente agricolo: stabilire se la resa di una contea in un dato anno sarà superiore o inferiore alla sua mediana storica.
Come il modello intelligente prende una decisione
Per trasformare questi dati in previsioni pratiche, il team costruisce un modello ensemble che combina due approcci di machine learning ben consolidati: Random Forest e Gradient Boosting. Entrambi sono efficaci nell’individuare pattern sottili tra molte variabili, ma funzionano in modi differenti — uno mediando molteplici alberi decisionali, l’altro correggendo progressivamente i propri errori. Un passaggio di voto fonde poi i loro punti di forza in una singola decisione sul fatto che una contea sia probabile abbia resa alta o bassa. Un’attenta pulizia dei dati, la scalatura e l’ingegneria delle caratteristiche aiutano il modello a riconoscere pattern stagionali ed eventi meteorologici estremi, mentre una valida strategia di cross-validation evita che il modello si limiti a memorizzare il passato.
Far luce sulla scatola nera
I modelli avanzati suscitano spesso preoccupazione: possono essere accurati ma opachi. Per affrontare questo problema, gli autori utilizzano SHAP, una tecnica moderna per spiegare quali input influenzano maggiormente ogni previsione. SHAP assegna a ciascuna variabile un punteggio di contributo, mostrando ad esempio come pattern di precipitazioni insoliti o segnali di vegetazione spingano una previsione verso una resa alta o bassa. In questo studio, fattori temporali, misure di variabilità e indicatori di salute delle colture da satellite emergono come driver principali. Questa trasparenza trasforma il modello in più di un semplice predittore: diventa uno strumento di supporto decisionale in grado di evidenziare perché certe regioni sono a rischio e dove interventi — come irrigazione, assicurazioni o pianificazione dello stoccaggio — potrebbero avere il maggior impatto.
Cosa significano i risultati per il mondo reale
Il modello finale mostra prestazioni solide, classificando correttamente gli anni di contea ad alta vs bassa resa con circa il 92% di precisione, richiamo e accuratezza sul test set, e il 97% di accuratezza sui dati di training, segnalando sia potenza predittiva sia una buona generalizzazione. I dati di mercato migliorano le prestazioni solo marginalmente, suggerendo che la maggiore parte della forza predittiva deriva da fattori agronomici e ambientali più che da segnali finanziari. Pur essendo l’approccio calibrato sulla Corn Belt statunitense e semplificando la resa in un esito binario, offre un modo scalabile ed efficiente dal punto di vista energetico per trasformare dati complessi in previsioni regionali utilizzabili. Per pianificatori e gestori della catena di approvvigionamento, questo si traduce in avvisi più tempestivi e affidabili su carenze o surplus, a supporto di decisioni più informate su semina, assicurazioni, stoccaggio e commercio in un clima che cambia.
Citazione: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Parole chiave: previsione della resa del mais, machine learning in agricoltura, dati da telerilevamento, sovranità alimentare, clima e colture