Clear Sky Science · pt
Previsão sustentável da produtividade regional de milho nos Estados Unidos por meio de abordagem interpretável de aprendizado de máquina
Por que prever colheitas de milho importa
O milho está no centro do sistema alimentar dos Estados Unidos, alimentando pessoas, animais e até abastecendo veículos. Mas, a cada ano, agricultores e formuladores de políticas precisam tomar decisões importantes — quanto plantar, o que estocar, como precificar o grão — sem saber exatamente quanto será colhido. À medida que o clima se torna mais imprevisível e os mercados mais voláteis, a capacidade de prever com precisão e de forma sustentável a produtividade regional de milho torna-se crucial para a segurança alimentar, a rentabilidade das fazendas e a estabilidade da cadeia de suprimentos.
De palpites simples a previsões mais inteligentes
Por décadas, especialistas confiaram em ferramentas estatísticas relativamente simples para prever produtividades, usando colheitas passadas, dados meteorológicos básicos e algumas informações sobre solos. Esses métodos captavam tendências gerais, mas tinham dificuldade com a realidade atual: volumes enormes de dados e relações complexas e não lineares entre clima, saúde do solo, práticas de manejo e crescimento das plantas. O novo estudo entra nessa lacuna ao construir modelos de aprendizado de máquina mais poderosos, porém interpretáveis, que conseguem lidar com dados ricos e multisource mantendo a capacidade de gerar insights que agricultores, traders e formuladores de políticas possam entender e confiar.
Integrando múltiplas fontes de dados
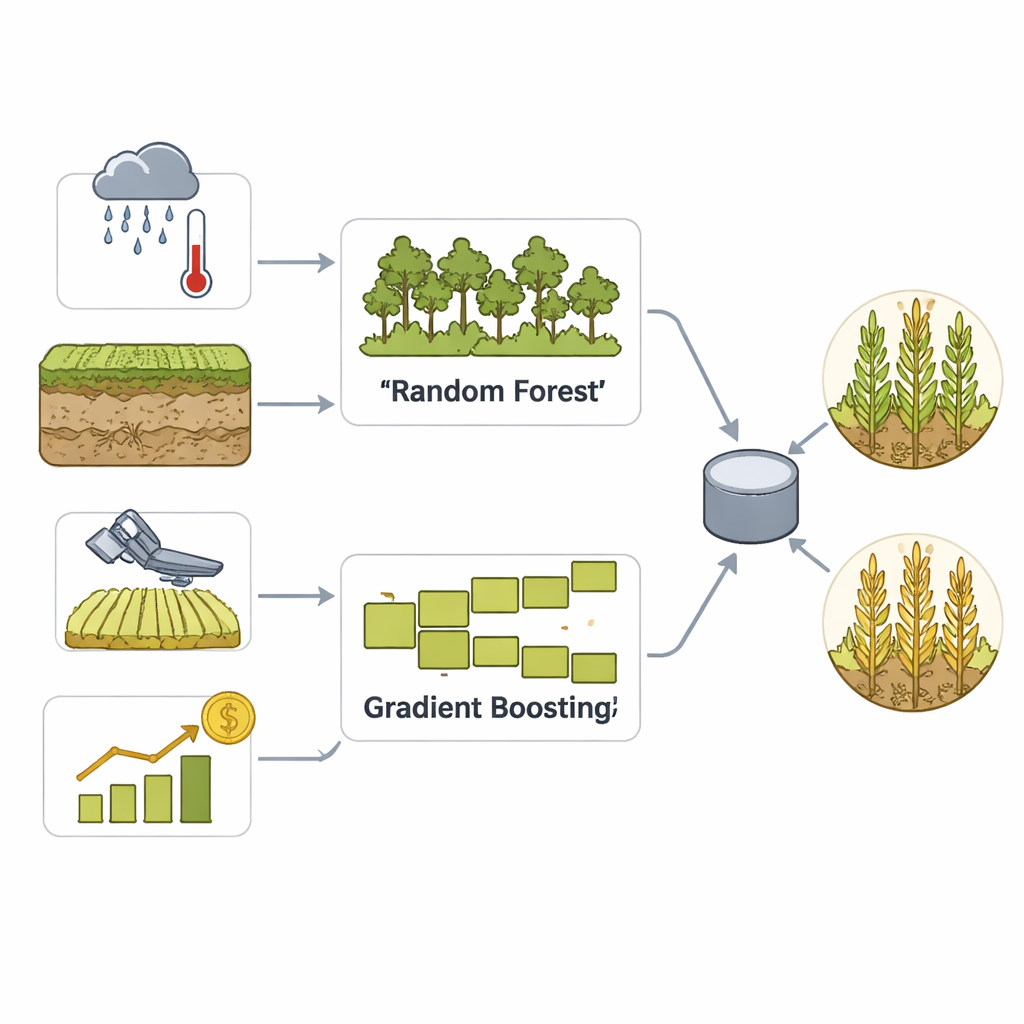
Os pesquisadores focam na produtividade de milho ao nível do condado na Corn Belt dos EUA, onde dados confiáveis e grandes áreas plantadas tornam previsões regionais especialmente valiosas. Eles montam um conjunto de dados abrangente cobrindo 2010–2020 que combina vários tipos de informação: registros meteorológicos detalhados como precipitação, temperatura, umidade e indicadores de seca; propriedades do solo como tipo, umidade e níveis de nutrientes; índices de vegetação baseados em satélite que acompanham a saúde e o vigor das lavouras ao longo do tempo; e produtividades históricas por condado a partir de estatísticas federais. Também adicionam dados de preços futuros do milho como um sinal suplementar das condições de mercado, mantendo o alvo da previsão estritamente agrícola: se a produtividade de um condado será acima ou abaixo de sua mediana histórica em um dado ano.
Como o modelo inteligente toma sua decisão
Para transformar esses dados ricos em previsões práticas, a equipe constrói um modelo em ensemble que combina duas abordagens consolidadas de aprendizado de máquina: Random Forest e Gradient Boosting. Ambos são bons em encontrar padrões sutis entre muitas variáveis, mas funcionam de maneiras diferentes — um pela média de muitas árvores de decisão, o outro corrigindo progressivamente seus próprios erros. Uma etapa de votação então combina suas forças em uma única decisão sobre se um condado provavelmente terá alta ou baixa produtividade. Limpeza cuidadosa dos dados, escalonamento e engenharia de atributos ajudam o modelo a reconhecer padrões sazonais e eventos climáticos extremos, enquanto validação cruzada extensa evita que ele simplesmente memorize o passado.
Vendo dentro da caixa-preta
Modelos avançados frequentemente levantam uma preocupação: podem ser precisos, mas opacos. Para contornar isso, os autores usam SHAP, uma técnica moderna para explicar quais entradas influenciam mais cada previsão. O SHAP atribui a cada característica uma pontuação de contribuição, mostrando, por exemplo, como padrões de chuva incomuns ou sinais de vegetação empurram uma previsão em direção a alta ou baixa produtividade. Neste estudo, fatores temporais, medidas de variabilidade e indicadores de saúde das plantas derivados de satélite emergem como principais motores. Essa transparência torna o modelo mais do que um mero preditor; ele se transforma em uma ferramenta de apoio à decisão que pode destacar por que certas regiões estão em risco e onde intervenções — como irrigação, seguro ou planejamento de armazenamento — podem ser mais importantes.
O que os resultados significam para o mundo real
O modelo final apresenta desempenho sólido, classificando corretamente anos de condados com produtividade alta versus baixa com cerca de 92% de precisão, recall e acurácia no teste, e 97% de acurácia nos dados de treinamento, indicando tanto potência quanto boa generalização. Dados de mercado melhoram o desempenho apenas ligeiramente, sugerindo que a maior parte da capacidade preditiva vem de fatores agronômicos e ambientais, e não de sinais financeiros. Embora a abordagem seja adaptada à Corn Belt dos EUA e simplifique a produtividade em um desfecho binário, ela oferece uma maneira escalável e energeticamente eficiente de transformar dados complexos em previsões regionais acionáveis. Para planejadores e gestores da cadeia de suprimentos, isso significa alertas mais precoces e confiáveis sobre déficits ou excedentes, apoiando decisões mais inteligentes sobre plantio, seguro, armazenamento e comércio em um clima em mudança.
Citação: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable regional corn yield prediction for the United States through interpretable machine learning approach. Sci Rep 16, 13942 (2026). https://doi.org/10.1038/s41598-026-43213-4
Palavras-chave: previsão de produtividade de milho, aprendizado de máquina na agricultura, dados de sensoriamento remoto, segurança alimentar, clima e culturas