Clear Sky Science · zh
基于Swin Transformer与CNN的手势三维姿态估计方法
与机器对话的双手
想象通过在空中移动双手就能控制电脑、汽车仪表盘或虚拟现实世界。要让这种交互感觉自然,机器必须准确知道每个手指关节在三维空间中的位置,即使手部被遮挡或光线不足。本文提出了一种从深度相机读取手部姿态的新方法,能够更准确地估计姿态,使得无接触、流畅的交互更接近日常现实。
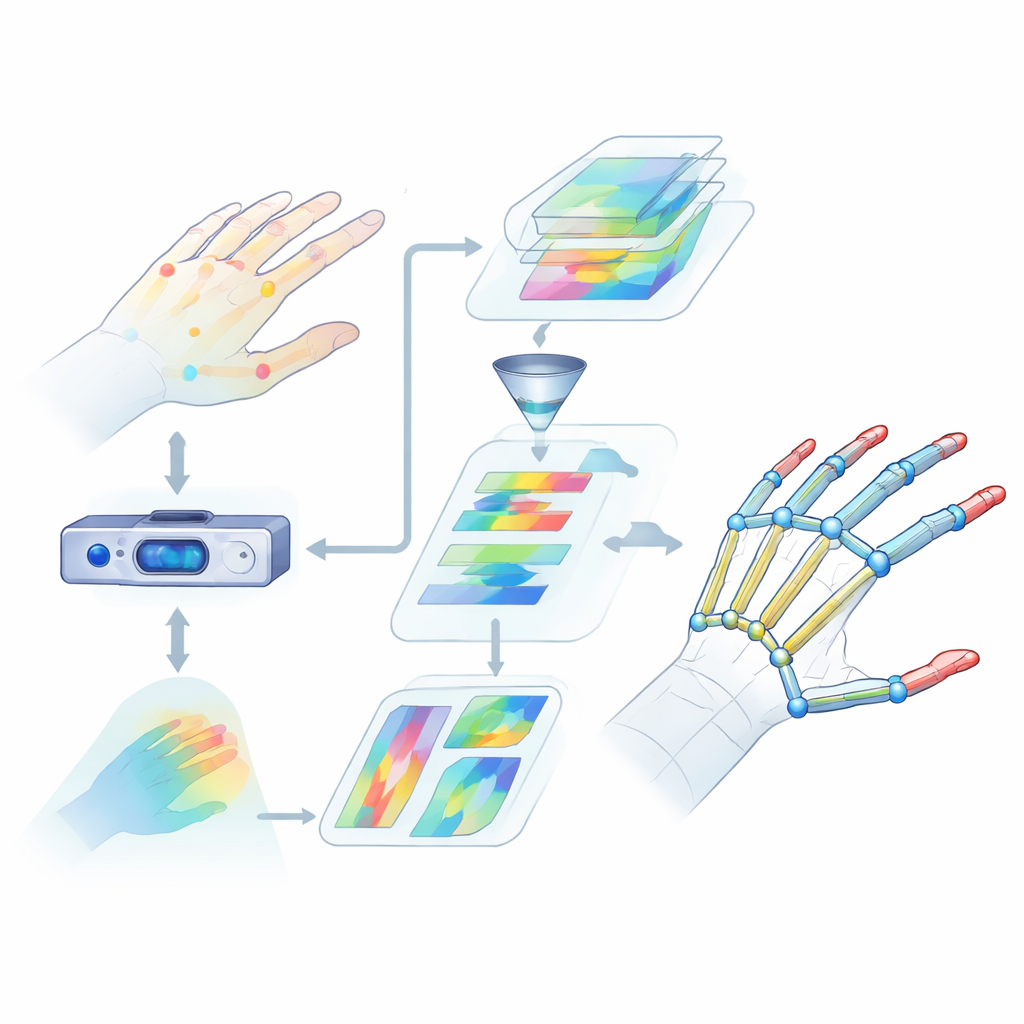
为何识别手很难
手部姿态估计是指从相机数据中找到手部关键关节的三维位置。这比听起来要复杂得多。手指会弯曲、旋转并相互重叠,不同人的手形与手掌大小也各异。许多现有方法仅依赖有限的视觉线索或聚焦于狭小区域,从而忽略了整只手的协同运动。它们也难以捕捉关节之间的远距离关系,例如拇指与食指在抓取物体时的配合。这些理解上的空缺导致在虚拟现实或手语识别等现实场景中出现更大误差和不可靠的性能。
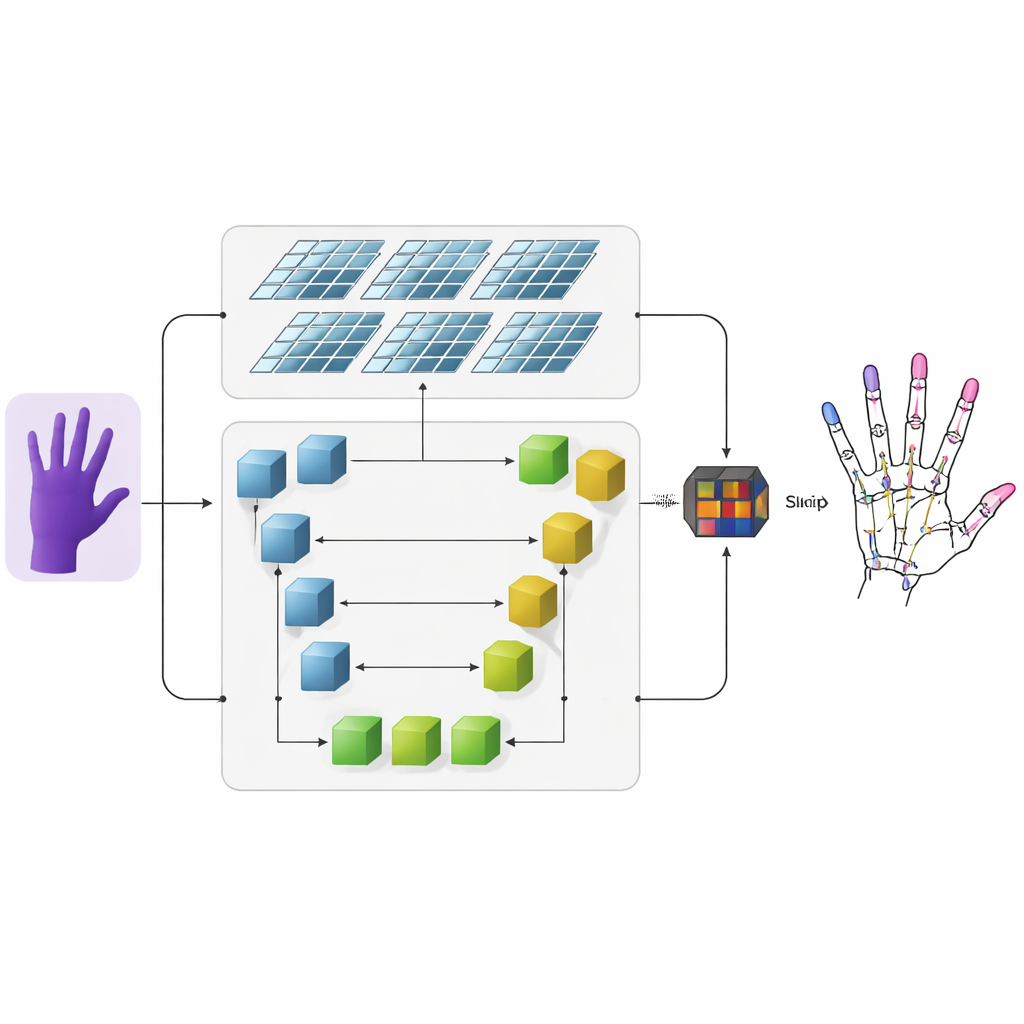
一种新的双通路手部视角
作者提出了一个系统,将深度图——每个像素编码到相机的距离——转换为精确的三维手部骨架。首先,传统的卷积神经网络从输入深度图中提取粗略的视觉特征。随后信息进入两条并行分支。一条分支使用U形网络在多个尺度上保留细节,保存诸如单个指关节等小结构。另一条分支采用较新的体系结构Swin Transformer,擅长捕捉图像中远距离区域之间的关联。通过同时运行这两条分支然后融合它们的输出,模型既学到每个关节的局部细节,又掌握整只手的总体结构。
突出指关节的热图
为了帮助网络学习关节可能出现的位置,研究者加入了一种称为热图的中间表示。对每个关节,他们在二维图中生成一个柔和的高亮点,该点的峰值标示该关节最可能的位置,而相邻像素则逐渐衰减。在训练过程中,模型不仅被要求预测每个关节的最终三维坐标,还要匹配这些热图。这种双重监督引导网络关注图像中的空间结构以及相邻关节之间的自然联系,还提升了系统在不同人和不同手势间的泛化能力。
新数据与更好精度
为验证他们的方法,作者将微软亚洲研究院的一个著名基准数据集与自己使用LiDAR设备采集的一组深度图像结合起来。他们的数据集补充了具有挑战性的案例,例如小而远的手和多样的手势,以更好地反映真实使用场景。该方法与多种广泛使用的手部姿态估计系统进行比较。总体来看,新模型将关节位置误差相比竞争方法降低了几毫米,同时仍能以适合实时或近实时应用的速度运行。详细实验表明,每个主要组件——Swin Transformer的全局建模、U形网络的局部多尺度特征以及热图监督——均对最终精度有可观贡献。
对日常交互的意义
简单来说,研究表明,让算法同时“看到”整只手的宏观结构与每根手指的微小细节,并用热图标出可能的关节位置,可以实现更可靠的三维手部跟踪。这种改进的精度与稳健性使得构建跨用户、不同光照和复杂姿态下可用的手势控制系统变得更容易,无论是用于虚拟现实、智能车载仪表盘,还是远程协作工具。尽管该方法仍需扩展以应对手与物体紧密交互等更复杂情形,但它朝着让计算机像我们使用双手一样顺畅地“读懂”手部动作迈出了坚实一步。
引用: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
关键词: 手部姿态估计, 手势识别, 深度成像, Transformer网络, 人机交互