Clear Sky Science · pl
Metoda estymacji 3D pozycji gestów dłoni oparta na Swin Transformer i CNN
Dłonie, które rozmawiają z maszynami
Wyobraź sobie kontrolowanie komputera, kokpitu samochodu lub świata wirtualnej rzeczywistości tylko poprzez ruchy rąk w powietrzu. Aby to działało naturalnie, maszyny muszą dokładnie wiedzieć, gdzie znajduje się każdy staw palca w przestrzeni trójwymiarowej, nawet gdy części dłoni są zasłonięte lub słabo oświetlone. W artykule przedstawiono nowy sposób, w jaki komputery mogą dokładniej odczytywać pozycje dłoni z kamer głębi, przybliżając płynną, bezdotykową interakcję do codziennej rzeczywistości.
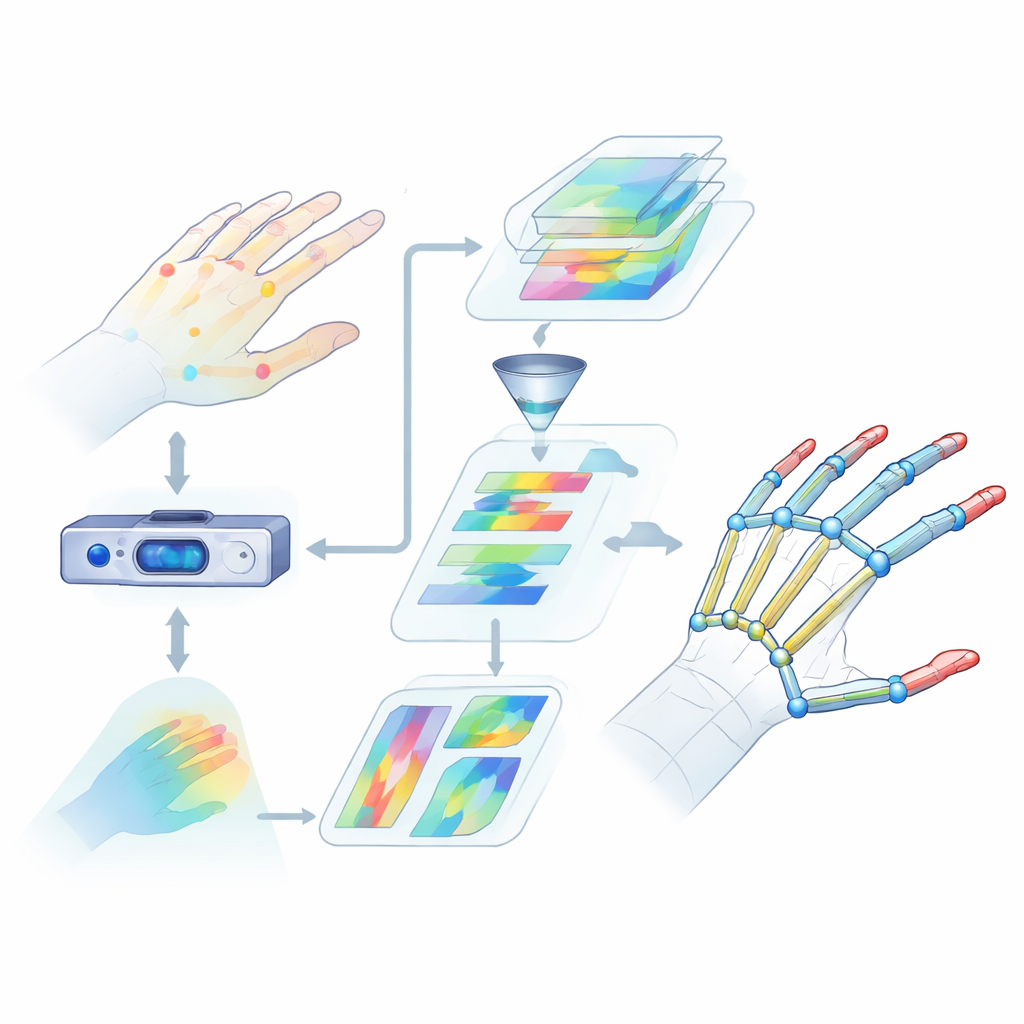
Dlaczego czytanie dłoni jest takie trudne
Estymacja pozycji dłoni oznacza wyznaczanie 3D położeń kluczowych stawów dłoni na podstawie danych z kamery. To znacznie trudniejsze, niż się wydaje. Palce zginają się, skręcają i zachodzą na siebie, a różni ludzie mają różne kształty i rozmiary dłoni. Wiele istniejących metod korzysta jedynie z ograniczonych wskazówek wizualnych lub skupia się na małych regionach, przez co traci informację o tym, jak cała dłoń porusza się jako całość. Mają też problemy z uchwyceniem dalekosiężnych relacji między stawami, na przykład jak kciuk i palec wskazujący współpracują przy chwytaniu przedmiotu. Te luki w rozumieniu prowadzą do większych błędów i zawodności w rzeczywistych zastosowaniach, takich jak wirtualna rzeczywistość czy rozpoznawanie języka migowego.
Nowe, dwutorowe spojrzenie na dłoń
Autorzy proponują system, który przekształca obrazy głębi — obrazy, w których każdy piksel koduje odległość od kamery — w precyzyjne trójwymiarowe szkielety dłoni. Najpierw konwencjonalna sieć konwolucyjna wydobywa z surowego obrazu głębi ogólne cechy wizualne. Następnie informacja przepływa do dwóch równoległych gałęzi. Jedna gałąź wykorzystuje sieć w kształcie litery U, aby zachować drobne detale na kilku skalach obrazu, zabezpieczając małe struktury, takie jak poszczególne stawy palców. Druga gałąź stosuje nowszą architekturę zwaną Swin Transformer, która świetnie radzi sobie z uchwyceniem powiązań między odległymi regionami obrazu. Uruchamiając obie gałęzie równocześnie i następnie łącząc ich wyjścia, model uczy się zarówno lokalnych detali każdego stawu, jak i ogólnej organizacji dłoni.
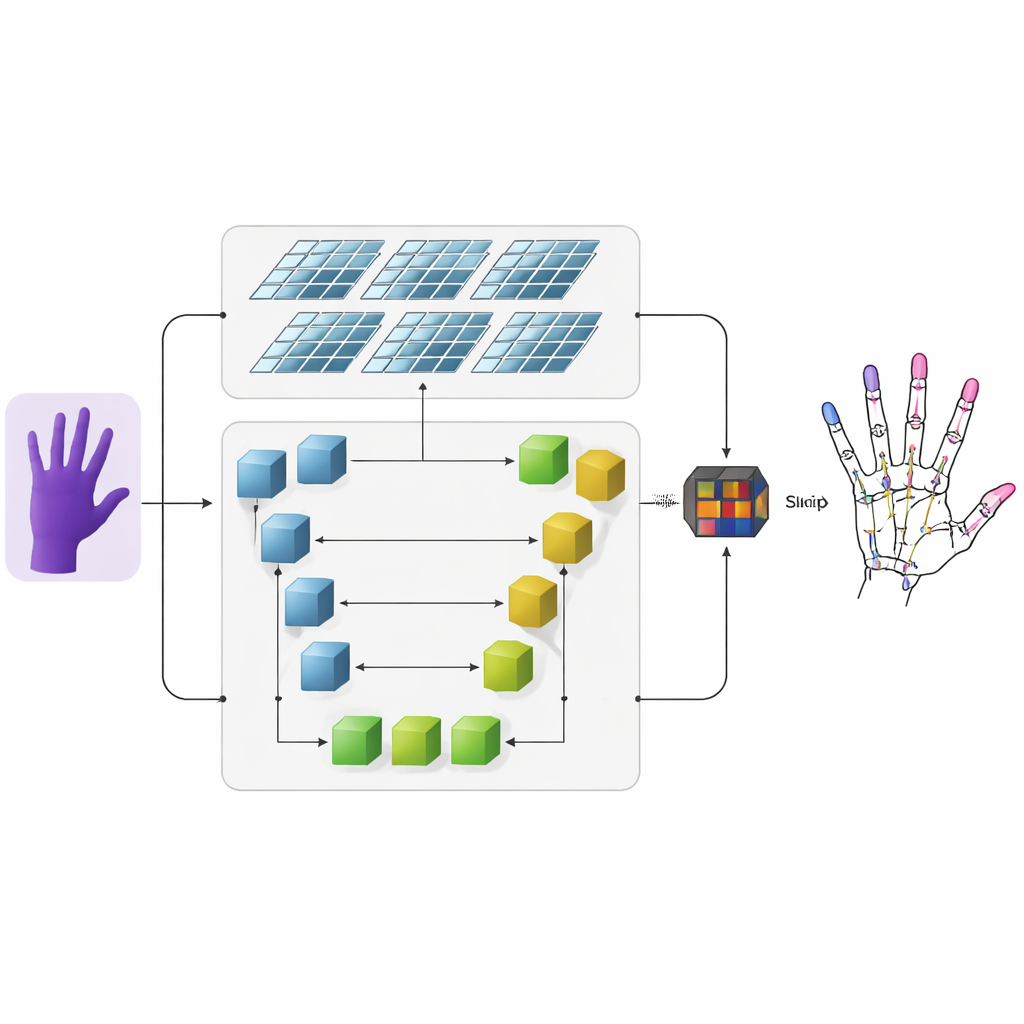
Mapy cieplne, które uwypuklają stawy palców
Aby pomóc sieci w nauce prawdopodobnych lokalizacji stawów, badacze dodają pośrednią reprezentację zwaną mapą cieplną. Dla każdego stawu generują miękką, rozświetloną plamę na dwuwymiarowej mapie, której szczyt wskazuje najbardziej prawdopodobne położenie tego stawu, a pobliskie piksele stopniowo wygasają. Podczas treningu model ma za zadanie nie tylko przewidzieć końcowe współrzędne 3D każdego stawu, lecz także dopasować się do tych map cieplnych. Podwójne nadzorowanie kieruje sieć, aby zwracała uwagę zarówno na strukturę przestrzenną obrazu, jak i naturalne powiązania między sąsiednimi stawami. Poprawia to też zdolność systemu do uogólniania na różne osoby i pozy dłoni.
Nowe dane i lepsza dokładność
Aby przetestować swoje podejście, autorzy połączyli znane zestawy benchmarkowe z Microsoft Research Asia z nowym zbiorem obrazów głębi zarejestrowanych przy użyciu urządzenia LiDAR. Ich własny zestaw zawiera trudniejsze przypadki, takie jak małe, odległe dłonie i zróżnicowane gesty, co lepiej odzwierciedla scenariusze rzeczywistego użycia. Metodę porównano z kilkoma powszechnie stosowanymi systemami estymacji pozycji dłoni. Średnio nowy model zmniejsza błąd w pozycjach stawów o kilka milimetrów w porównaniu z konkurencją, przy jednoczesnym zachowaniu prędkości odpowiedniej do zastosowań w czasie rzeczywistym lub bliskim rzeczywistemu. Szczegółowe eksperymenty pokazują, że każdy główny element — modelowanie globalne przez Swin Transformer, lokalne cechy wieloskalowe z sieci typu U oraz nadzorowanie mapami cieplnymi — wnosi mierzalny wkład w końcową dokładność.
Co to oznacza dla codziennej interakcji
Mówiąc prosto, badanie pokazuje, że umożliwienie algorytmowi dostrzeżenia zarówno „szerokiego obrazu” całej dłoni, jak i drobnych detali każdego palca, oraz trenowanie go z użyciem map cieplnych wskazujących prawdopodobne lokalizacje stawów, prowadzi do bardziej niezawodnego śledzenia ruchu dłoni w 3D. Ta poprawiona precyzja i odporność ułatwia budowanie systemów sterowanych gestami, które działają u różnych użytkowników, w zmiennych warunkach oświetleniowych i przy skomplikowanych pozach — czy to dla wirtualnej rzeczywistości, inteligentnych kokpitów samochodowych, czy narzędzi do zdalnej współpracy. Chociaż metoda wymaga jeszcze rozszerzenia na bardziej złożone sytuacje, gdzie dłonie ściśle współdziałają z przedmiotami, stanowi solidny krok w kierunku komputerów potrafiących odczytywać nasze ruchy dłoni tak płynnie, jak je wykonujemy.
Cytowanie: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Słowa kluczowe: estymacja pozycji dłoni, rozpoznawanie gestów, obrazowanie głębi, sieci transformerowe, interakcja człowiek–komputer