Clear Sky Science · it
Metodo di stima della posa 3D delle mani basato su Swin Transformer e CNN
Mani che comunicano con le macchine
Immagina di controllare un computer, il cruscotto di un’auto o un mondo di realtà virtuale semplicemente muovendo le mani nell’aria. Perché questa esperienza sia naturale, le macchine devono conoscere con precisione la posizione di ogni articolazione delle dita nello spazio tridimensionale, anche quando parti della mano sono nascoste o scarsamente illuminate. Questo articolo presenta un nuovo metodo per far sì che i computer leggano le pose della mano da telecamere di profondità con maggiore accuratezza, avvicinando l’interazione senza contatto a un uso quotidiano fluido.
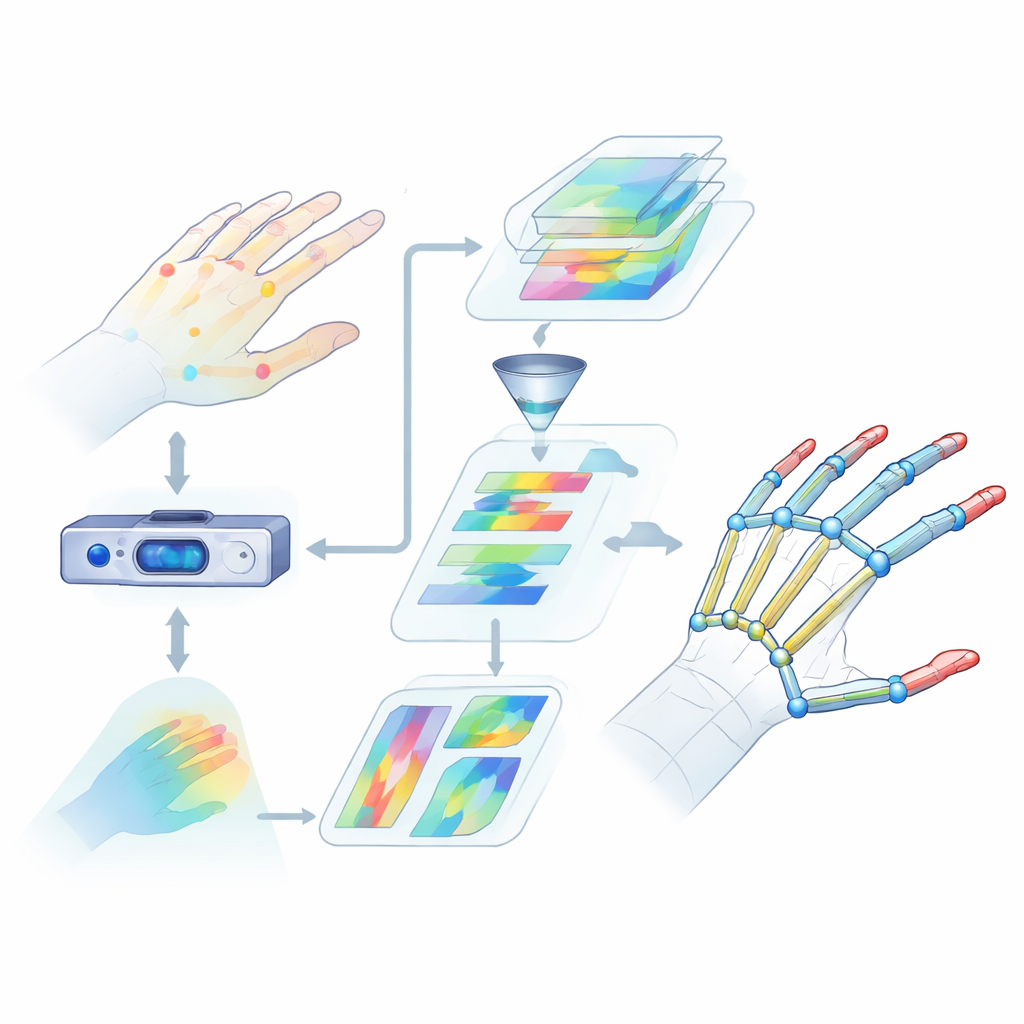
Perché leggere le mani è così difficile
La stima della posa della mano consiste nel trovare le posizioni 3D delle articolazioni chiave della mano a partire dai dati della telecamera. È più complesso di quanto sembri. Le dita si piegano, si torsiono e si sovrappongono, e persone diverse hanno forme e dimensioni delle mani differenti. Molti metodi esistenti si basano su indizi visivi limitati o si concentrano su regioni ristrette, perdendo così la comprensione di come la mano si muova nel suo complesso. Faticano inoltre a catturare relazioni a lunga distanza tra le articolazioni, per esempio come pollice e indice cooperano durante l’afferrare un oggetto. Queste lacune nella comprensione portano a errori maggiori e prestazioni inaffidabili in scenari reali come la realtà virtuale o il riconoscimento della lingua dei segni.
Una nuova visione a due percorsi della mano
Gli autori propongono un sistema che prende immagini di profondità—fotogrammi in cui ogni pixel codifica la distanza dalla telecamera—e le trasforma in scheletri 3D precisi della mano. Prima, una rete neurale convoluzionale convenzionale estrae caratteristiche visive grossolane dall’immagine di profondità in input. Successivamente l’informazione fluisce in due rami paralleli. Un ramo usa una rete a forma di U per mantenere i dettagli fini a diverse scale d’immagine, preservando piccole strutture come singole articolazioni delle dita. L’altro ramo impiega una architettura più recente chiamata Swin Transformer, che eccelle nel catturare come regioni distanti dell’immagine siano correlate. Eseguendo entrambi i rami in parallelo e poi fondendo i loro output, il modello apprende sia i dettagli locali di ogni articolazione sia l’organizzazione globale della mano.
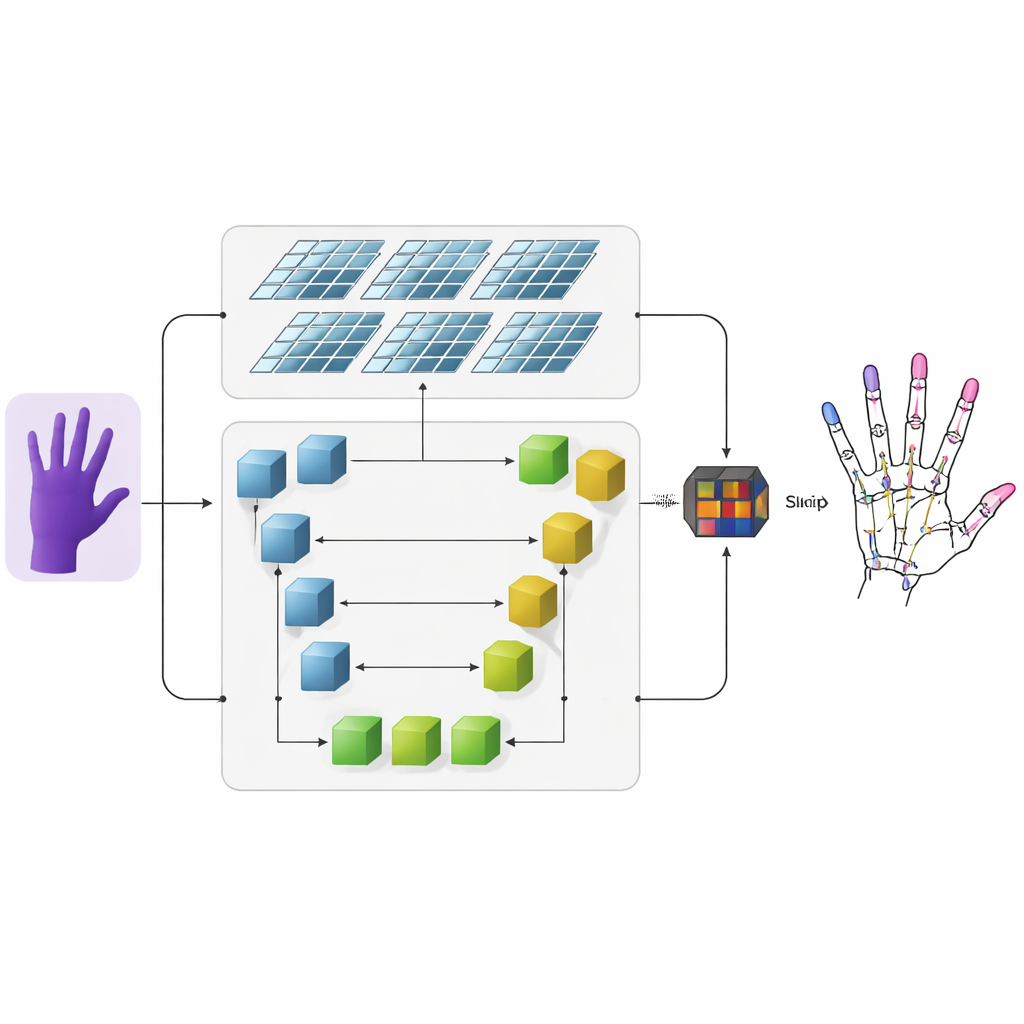
Mappe di calore che evidenziano le articolazioni
Per aiutare la rete a imparare dove è probabile che si trovino le articolazioni, i ricercatori aggiungono una rappresentazione intermedia chiamata mappa di calore. Per ogni articolazione generano un punto morbido e luminoso in una mappa bidimensionale il cui picco indica la posizione più probabile di quell’articolazione, mentre i pixel vicini decadono gradualmente. Durante l’addestramento, al modello viene chiesto non solo di prevedere le coordinate 3D finali di ogni articolazione, ma anche di far corrispondere queste mappe di calore. Questa supervisione doppia guida la rete a prestare attenzione sia alla struttura spaziale nell’immagine sia alle connessioni naturali tra articolazioni vicine. Migliora inoltre la capacità del sistema di generalizzare tra persone e pose della mano diverse.
Nuovi dati e maggiore accuratezza
Per testare il loro approccio, gli autori combinano un noto dataset di benchmark di Microsoft Research Asia con un nuovo insieme di immagini di profondità acquisito usando un dispositivo LiDAR. Il loro dataset aggiunge casi difficili, come mani piccole e distanti e gesti variati, per riflettere meglio scenari d’uso reali. Il metodo viene confrontato con diversi sistemi di stima della posa della mano largamente usati. In media, il nuovo modello riduce l’errore nelle posizioni delle articolazioni di qualche millimetro rispetto a questi concorrenti, mantenendo velocità compatibili con applicazioni in tempo reale o prossime al tempo reale. Esperimenti dettagliati mostrano che ogni componente principale—la modellazione globale tramite Swin Transformer, le caratteristiche locali multi-scala della rete a U e la supervisione tramite mappe di calore—contribuisce in modo misurabile all’accuratezza finale.
Cosa significa per l’interazione quotidiana
In termini semplici, lo studio dimostra che consentire a un algoritmo di vedere sia il “quadro d’insieme” della mano sia i dettagli minuti di ciascun dito, e addestrarlo con mappe di calore che evidenziano le probabili posizioni delle articolazioni, porta a un tracciamento 3D della mano più affidabile. Questa maggiore precisione e robustezza rende più semplice costruire sistemi controllati dai gesti che funzionino tra utenti diversi, condizioni di illuminazione variabili e pose complesse, sia per la realtà virtuale, i cruscotti intelligenti delle auto o gli strumenti di collaborazione remota. Sebbene il metodo debba ancora essere esteso a situazioni più complicate in cui le mani interagiscono strettamente con oggetti, rappresenta un solido passo verso computer in grado di leggere i nostri movimenti delle mani con la stessa scorrevolezza con cui li usiamo noi.
Citazione: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Parole chiave: stima della posa della mano, riconoscimento dei gesti, imaging di profondità, reti Transformer, interazione uomo–computer