Clear Sky Science · fr
Méthode d’estimation de la pose 3D des gestes de la main basée sur Swin Transformer et CNN
Des mains qui parlent aux machines
Imaginez contrôler un ordinateur, le tableau de bord d’une voiture ou un univers de réalité virtuelle simplement en déplaçant vos mains dans l’air. Pour que cela paraisse naturel, les machines doivent connaître avec précision la position de chaque articulation des doigts dans l’espace tridimensionnel, même quand des parties de la main sont cachées ou mal éclairées. Cet article présente une nouvelle méthode permettant aux ordinateurs de lire les poses des mains à partir de caméras de profondeur de manière plus précise, rapprochant ainsi l’interaction sans contact d’une utilisation quotidienne fluide.
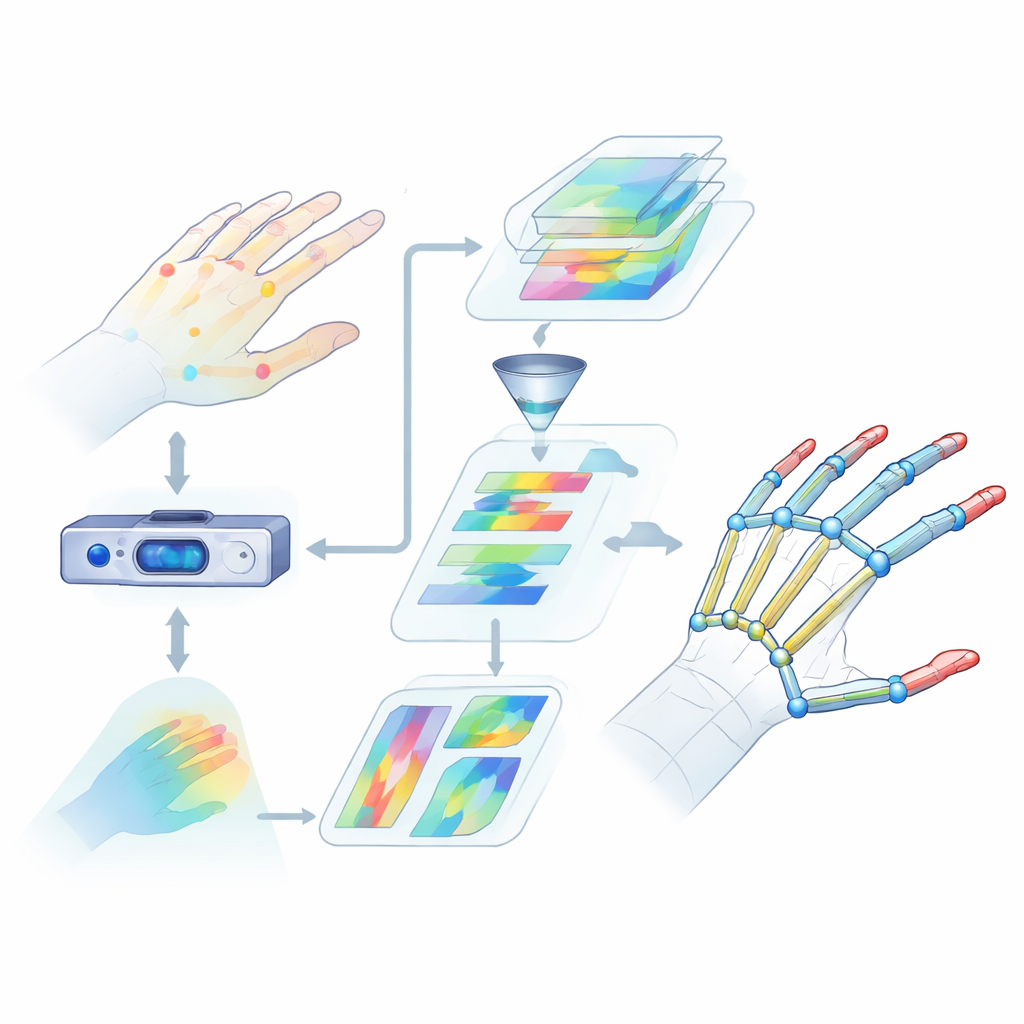
Pourquoi lire les mains est si difficile
L’estimation de la pose de la main consiste à déterminer les positions 3D des articulations clés de la main à partir des données d’une caméra. C’est plus compliqué qu’il n’y paraît. Les doigts se plient, se tordent et se chevauchent, et chaque personne a une morphologie de main différente. De nombreuses méthodes existantes ne s’appuient que sur des indices visuels limités ou se concentrent sur de petites régions, manquant ainsi la manière dont la main entière se déplace de concert. Elles peinent également à saisir les relations à longue distance entre les articulations, par exemple la coopération entre le pouce et l’index lors de la préhension d’un objet. Ces lacunes entraînent des erreurs plus importantes et des performances peu fiables dans des situations réelles comme la réalité virtuelle ou la reconnaissance de la langue des signes.
Une nouvelle vue à deux voies de la main
Les auteurs proposent un système qui transforme des images de profondeur — des images où chaque pixel encode la distance à la caméra — en squelettes 3D précis de la main. D’abord, un réseau neuronal convolutif classique extrait des caractéristiques visuelles grossières de l’image de profondeur d’entrée. Ensuite, l’information circule vers deux branches parallèles. Une branche utilise un réseau en U pour conserver les détails fins à plusieurs échelles d’image, préservant de petites structures comme les articulations individuelles des doigts. L’autre branche utilise une architecture plus récente appelée Swin Transformer, qui excelle à capturer les relations entre des régions éloignées d’une image. En exécutant les deux branches en parallèle puis en fusionnant leurs sorties, le modèle apprend à la fois les détails locaux de chaque articulation et l’organisation globale de la main.
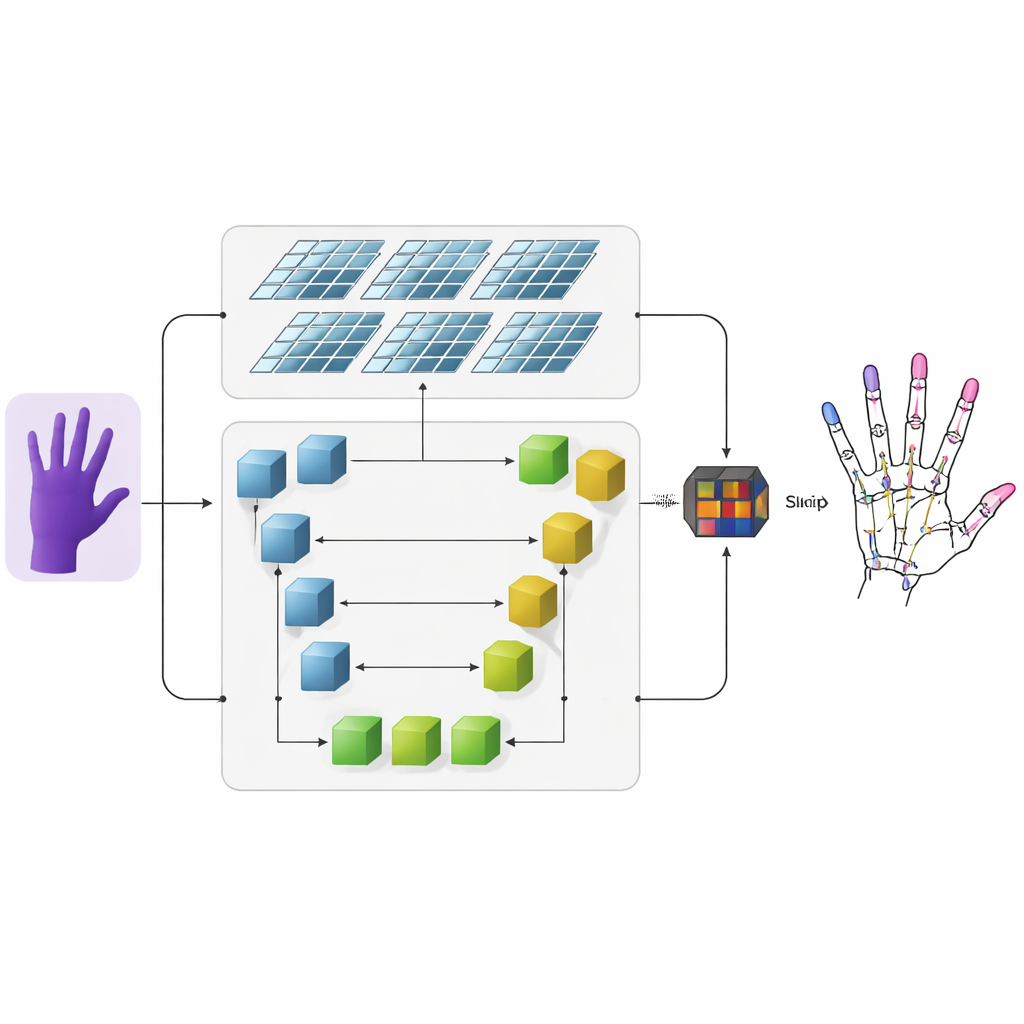
Des cartes de chaleur qui mettent en valeur les articulations
Pour aider le réseau à apprendre où les articulations sont susceptibles d’apparaître, les chercheurs ajoutent une représentation intermédiaire appelée carte de chaleur. Pour chaque articulation, ils génèrent une tache douce et lumineuse sur une carte 2D dont le pic indique l’emplacement le plus probable de cette articulation, les pixels voisins s’estompant progressivement. Lors de l’entraînement, le modèle doit non seulement prédire les coordonnées 3D finales de chaque articulation, mais aussi reproduire ces cartes de chaleur. Cette double supervision guide le réseau pour qu’il prête attention à la fois à la structure spatiale de l’image et aux connexions naturelles entre articulations voisines. Elle améliore aussi la capacité du système à généraliser entre différentes personnes et poses de main.
Nouvelles données et meilleure précision
Pour tester leur approche, les auteurs combinent un jeu de données de référence bien connu de Microsoft Research Asia avec un nouvel ensemble d’images de profondeur qu’ils ont capturées à l’aide d’un dispositif LiDAR. Leur propre jeu de données ajoute des cas difficiles, comme des mains petites et éloignées et des gestes variés, afin de mieux refléter des scénarios d’utilisation réels. La méthode est comparée à plusieurs systèmes d’estimation de la pose de main largement utilisés. En moyenne, le nouveau modèle réduit l’erreur sur les positions d’articulation de quelques millimètres par rapport à ces concurrents, tout en fonctionnant à des vitesses adaptées à des applications en temps réel ou quasi temps réel. Des expériences détaillées montrent que chaque composant majeur — la modélisation globale par le Swin Transformer, les caractéristiques locales multi‑échelles du réseau en U et la supervision par carte de chaleur — contribue de manière mesurable à la précision finale.
Ce que cela change pour l’interaction quotidienne
En termes simples, l’étude montre que permettre à un algorithme de voir à la fois la « vue d’ensemble » de la main et les détails minuscules de chaque doigt, puis de l’entraîner avec des cartes de chaleur qui mettent en évidence les emplacements probables des articulations, conduit à un suivi 3D des mains plus fiable. Cette précision et robustesse accrues facilitent la création de systèmes contrôlés par gestes qui fonctionnent pour différents utilisateurs, conditions d’éclairage et poses complexes, que ce soit pour la réalité virtuelle, les tableaux de bord intelligents ou les outils de collaboration à distance. Bien que la méthode doive encore être étendue à des situations plus compliquées où les mains interagissent étroitement avec des objets, elle représente une étape solide vers des ordinateurs capables de lire nos mouvements de main aussi naturellement que nous les utilisons.
Citation: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Mots-clés: estimation de la pose de la main, reconnaissance de gestes, imagerie de profondeur, réseaux Transformer, interaction homme‑machine