Clear Sky Science · nl
3D-handgebarenhoudingsschattingsmethode gebaseerd op Swin Transformer en CNN
Handen die met machines praten
Stel je voor dat je een computer, een dashboard in de auto of een virtuele wereld bestuurt alleen door je handen in de lucht te bewegen. Om dat natuurlijk te laten aanvoelen, moeten machines precies weten waar elk vingergewricht zich in de driedimensionale ruimte bevindt, zelfs wanneer delen van de hand verborgen zijn of slecht verlicht. Dit artikel presenteert een nieuwe manier voor computers om handhoudingen uit dieptecamera’s nauwkeuriger af te lezen, waardoor vloeiende, aanrakingloze interactie een stap dichter bij het dagelijks gebruik komt.
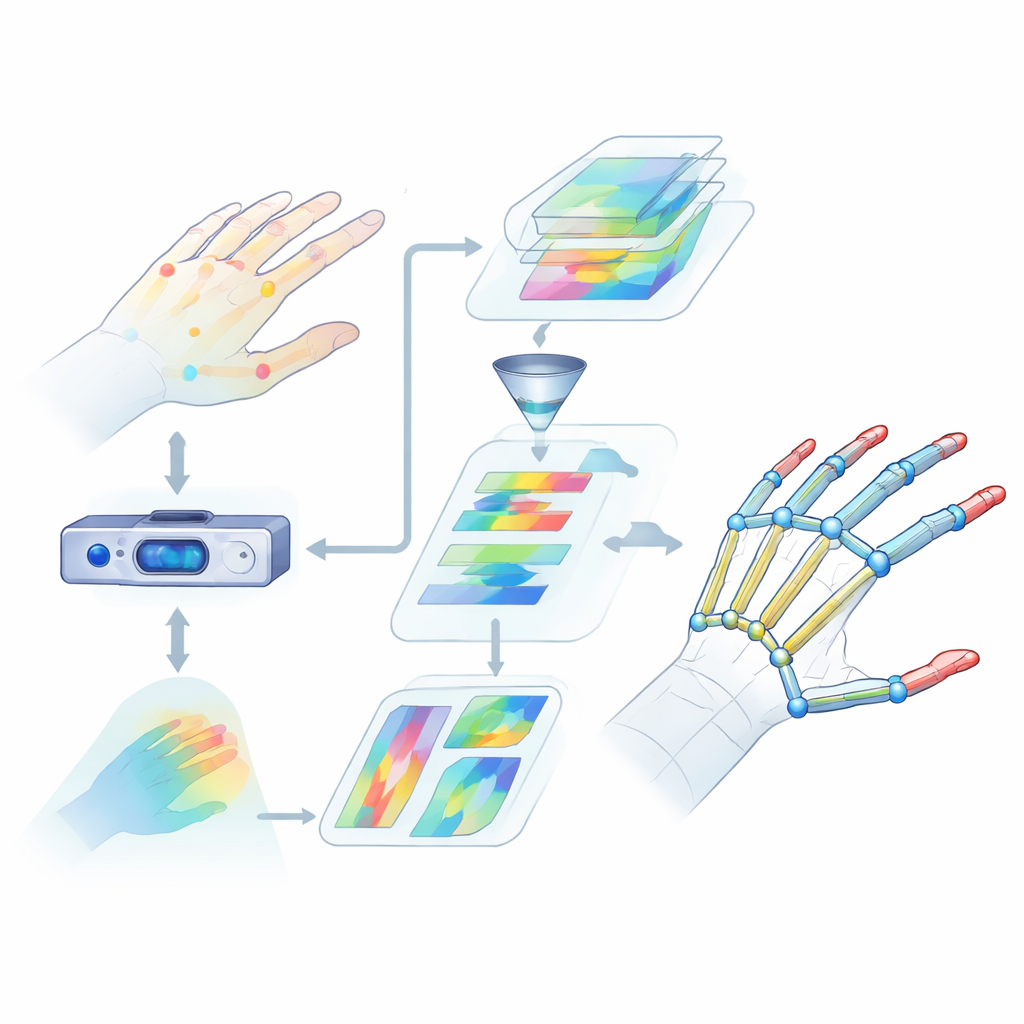
Waarom handen lezen zo moeilijk is
Handpose-schatting betekent het bepalen van de 3D-posities van belangrijke gewrichten in de hand op basis van cameradata. Dat is lastiger dan het klinkt. Vingers buigen, draaien en overlappen elkaar, en mensen hebben verschillende handvormen en -maten. Veel bestaande methoden kijken slechts naar beperkte visuele aanwijzingen of concentreren zich op kleine regio’s, waardoor ze missen hoe de hele hand samen beweegt. Ze hebben ook moeite met het vastleggen van langafstandsrelaties tussen gewrichten, zoals hoe duim en wijsvinger samenwerken bij het grijpen van een voorwerp. Deze hiaten in begrip leiden tot grotere fouten en onbetrouwbare prestaties in echte situaties zoals virtual reality of gebarentaalherkenning.
Een nieuw tweesporig beeld van de hand
De auteurs stellen een systeem voor dat dieptebeelden—foto’s waarbij elke pixel afstand tot de camera codeert—omzet in precieze 3D-handskeletten. Eerst extraheert een conventioneel convolutioneel neuraal netwerk grove visuele kenmerken uit het ingangsdieptebeeld. Daarna stroomt de informatie naar twee parallelle takken. De ene tak gebruikt een U-vormig netwerk om fijne details op meerdere afbeeldingsschalen bij te houden, waardoor kleine structuren zoals individuele vingergewrichten behouden blijven. De andere tak gebruikt een nieuwere architectuur genaamd Swin Transformer, die uitblinkt in het vastleggen van hoe verder van elkaar gelegen regio’s in een afbeelding gerelateerd zijn. Door beide takken gelijktijdig te laten werken en hun outputs te fuseren, leert het model zowel de lokale details van elk gewricht als de algemene organisatie van de hand.
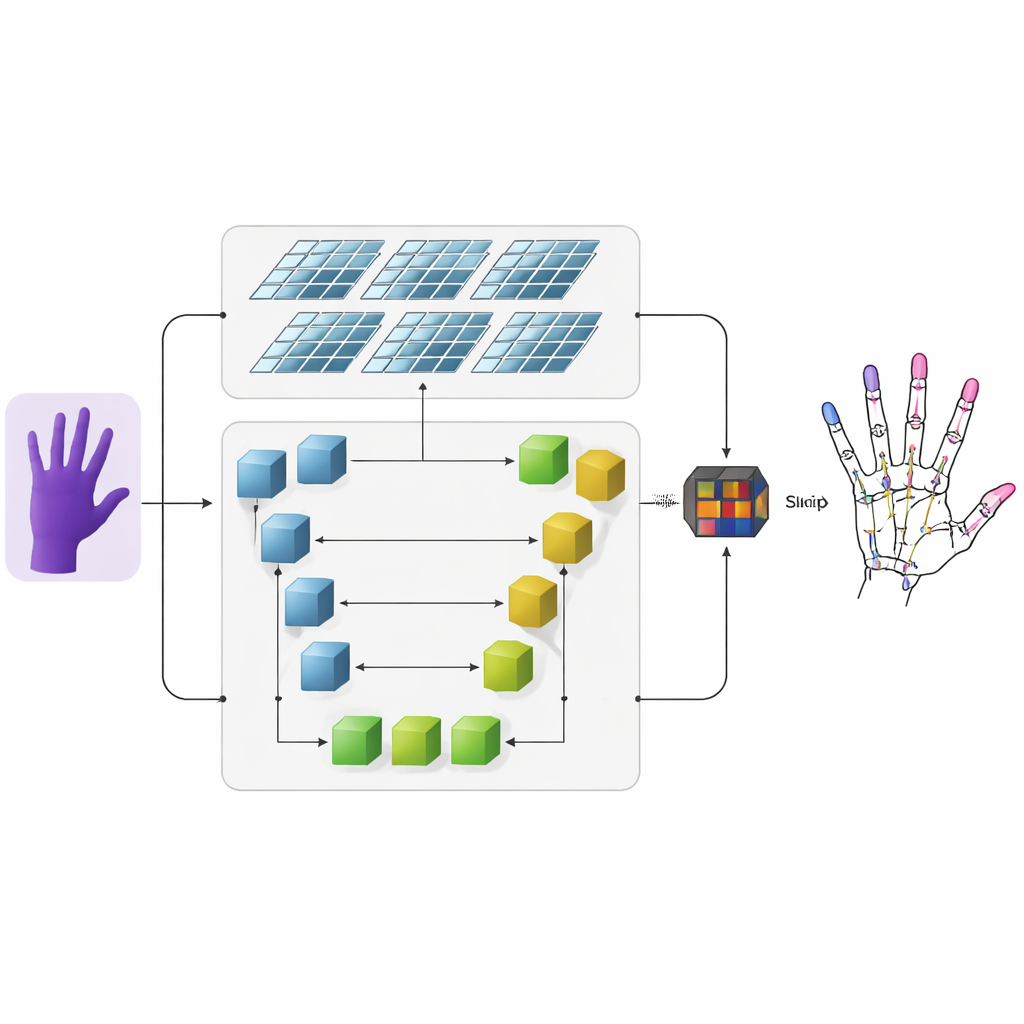
Heatmaps die vingergewrichten benadrukken
Om het netwerk te helpen leren waar gewrichten waarschijnlijk verschijnen, voegen de onderzoekers een tussentijdse representatie toe die een heatmap wordt genoemd. Voor elk gewricht genereren ze een zachte, gloeiende plek in een 2D-kaart waarvan de piek de meest waarschijnlijke locatie van dat gewricht aanduidt, terwijl nabijgelegen pixels geleidelijk vervagen. Tijdens training wordt het model niet alleen gevraagd de uiteindelijke 3D-coördinaten van elk gewricht te voorspellen, maar ook om deze heatmaps te matchen. Deze dubbele supervisie stuurt het netwerk om zowel aandacht te besteden aan ruimtelijke structuur in de afbeelding als aan de natuurlijke verbanden tussen naburige gewrichten. Het verbetert ook het vermogen van het systeem om te generaliseren over verschillende mensen en handhoudingen.
Nieuwe data en betere nauwkeurigheid
Om hun aanpak te testen combineren de auteurs een bekend benchmark-dataset van Microsoft Research Asia met een nieuwe set dieptebeelden die ze zelf vastlegden met een LiDAR-apparaat. Hun eigen dataset voegt uitdagende gevallen toe, zoals kleine, verre handen en gevarieerde gebaren, om beter realistische gebruiksscenario’s te weerspiegelen. De methode wordt vergeleken met verschillende veelgebruikte systemen voor handpose-schatting. Gemiddeld vermindert het nieuwe model de fout in gewrichtsposities met enkele millimeters vergeleken met deze concurrenten, terwijl het nog steeds snel genoeg werkt voor realtime of bijna-realtime toepassingen. Gedetailleerde experimenten tonen aan dat elk belangrijk onderdeel—globaal modelleren door de Swin Transformer, lokale multiscale kenmerken uit het U-vormige netwerk en heatmap-supervisie—meetbaar bijdraagt aan de uiteindelijke nauwkeurigheid.
Wat dit betekent voor alledaagse interactie
Kort gezegd laat de studie zien dat het een algoritme zowel het totaalplaatje van de hele hand als de fijne details van elke vinger laten zien, en het trainen met heatmaps die waarschijnlijke gewrichtslocaties benadrukken, leidt tot betrouwbaardere tracking van 3D-handbewegingen. Deze verbeterde precisie en robuustheid maakt het eenvoudiger om gebaargebaseerde systemen te bouwen die werken voor verschillende gebruikers, lichtomstandigheden en complexe houdingen, of het nu gaat om virtual reality, slimme autointerfaces of gereedschap voor samenwerken op afstand. Hoewel de methode nog uitgebreid moet worden naar complexere situaties waarin handen nauw samenwerken met objecten, vormt het een stevige stap naar computers die onze handbewegingen even soepel kunnen lezen als wij ze gebruiken.
Bronvermelding: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Trefwoorden: handpose-schatting, gebaarherkenning, dieptebeeldvorming, transformernetwerken, mens–computerinteractie