Clear Sky Science · es
Método de estimación de pose 3D de gestos de mano basado en swin transformer y CNN
Manos que hablan con las máquinas
Imagínese controlar un ordenador, el tablero de un coche o un mundo de realidad virtual simplemente moviendo las manos en el aire. Para que eso se sienta natural, las máquinas deben saber con precisión dónde está cada articulación de los dedos en el espacio tridimensional, incluso cuando partes de la mano están ocultas o hay poca iluminación. Este artículo presenta una nueva forma de que los ordenadores interpreten las poses de la mano a partir de cámaras de profundidad con mayor exactitud, acercando la interacción sin contacto y fluida a la realidad cotidiana.
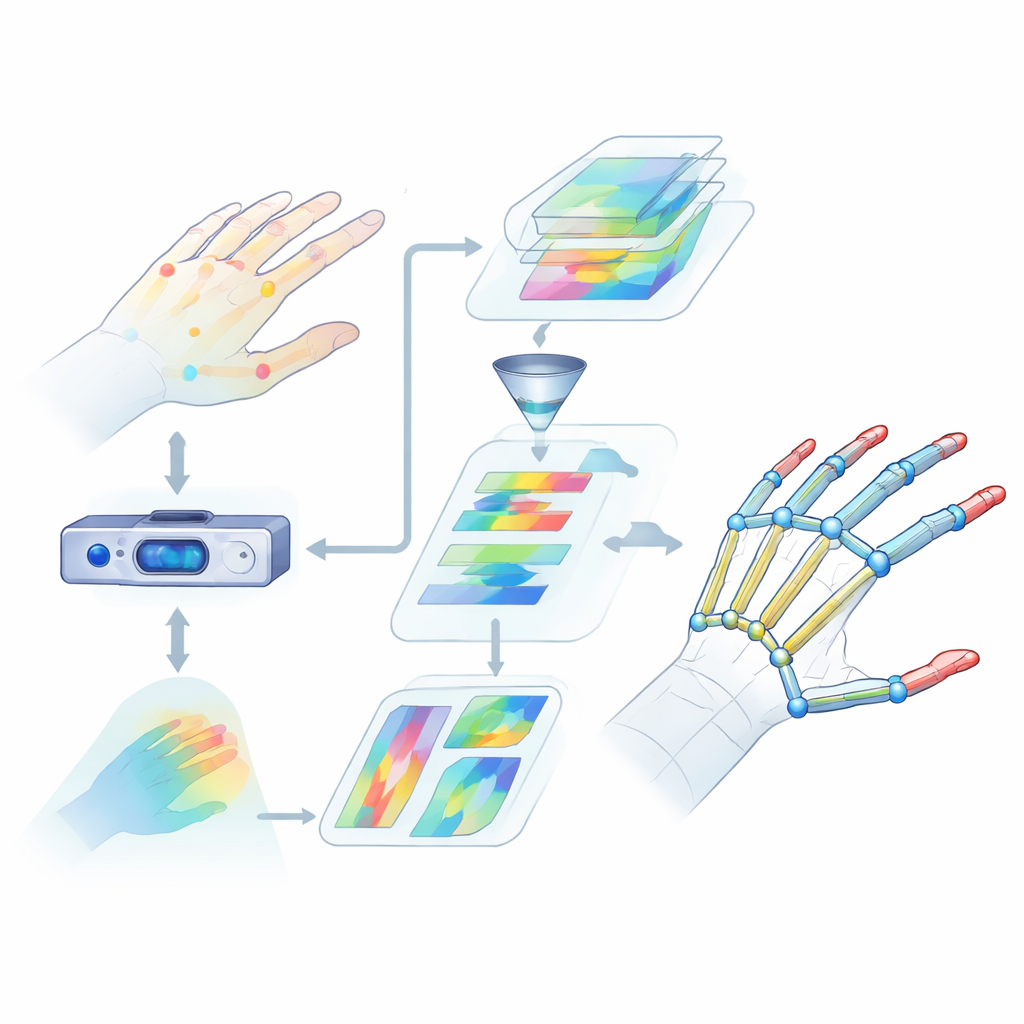
Por qué leer las manos es tan difícil
La estimación de la pose de la mano consiste en encontrar las posiciones 3D de las articulaciones clave de la mano a partir de datos de la cámara. Eso es mucho más complicado de lo que parece. Los dedos se doblan, giran y se solapan, y distintas personas tienen formas y tamaños de mano diferentes. Muchos métodos existentes sólo consideran indicios visuales limitados o se centran en regiones pequeñas, por lo que pierden cómo se mueve la mano en su conjunto. También les cuesta captar relaciones a larga distancia entre articulaciones, como la cooperación entre el pulgar y el índice al agarrar un objeto. Estas lagunas en la comprensión se traducen en errores mayores y en un rendimiento poco fiable en situaciones del mundo real, como realidad virtual o reconocimiento de lenguaje de signos.
Una nueva visión de dos vías de la mano
Los autores proponen un sistema que toma imágenes de profundidad —imágenes en las que cada píxel codifica la distancia a la cámara— y las convierte en esqueletos 3D precisos de la mano. Primero, una red neuronal convolucional convencional extrae características visuales gruesas de la imagen de profundidad de entrada. Luego la información fluye hacia dos ramas paralelas. Una rama utiliza una red en forma de U para mantener los detalles finos a varias escalas de imagen, preservando estructuras pequeñas como las articulaciones individuales de los dedos. La otra rama emplea una arquitectura más reciente llamada Swin Transformer, que destaca en capturar cómo se relacionan regiones distantes de una imagen. Al ejecutar ambas ramas simultáneamente y luego fusionar sus salidas, el modelo aprende tanto los detalles locales de cada articulación como la organización global de la mano.
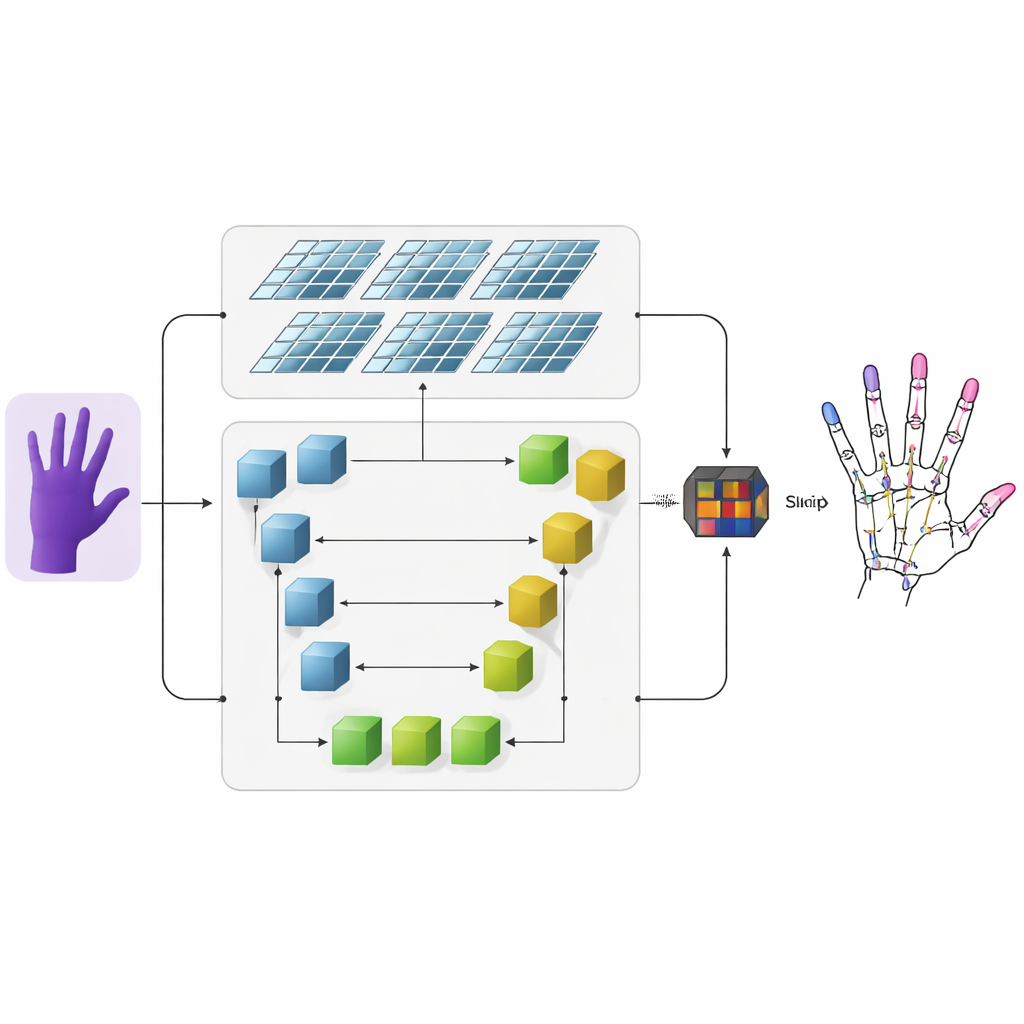
Mapas de calor que resaltan las articulaciones
Para ayudar a la red a aprender dónde es probable que aparezcan las articulaciones, los investigadores añaden una representación intermedia llamada mapa de calor. Para cada articulación generan una mancha suave y luminosa en un mapa 2D cuyo pico señala la ubicación más probable de esa articulación, mientras que los píxeles cercanos se atenúan gradualmente. Durante el entrenamiento, al modelo se le pide no sólo predecir las coordenadas 3D finales de cada articulación, sino también ajustarse a estos mapas de calor. Esta supervisión dual guía a la red para que preste atención tanto a la estructura espacial en la imagen como a las conexiones naturales entre articulaciones vecinas. Además, mejora la capacidad del sistema para generalizar entre distintas personas y poses de la mano.
Nuevos datos y mayor precisión
Para evaluar su enfoque, los autores combinan un conjunto de referencia bien conocido de Microsoft Research Asia con un nuevo conjunto de imágenes de profundidad que capturaron usando un dispositivo LiDAR. Su propio conjunto añade casos desafiantes, como manos pequeñas y lejanas y gestos variados, para reflejar mejor escenarios de uso reales. El método se compara con varios sistemas de estimación de pose de mano ampliamente utilizados. En promedio, el nuevo modelo reduce el error en las posiciones de las articulaciones hasta en unos pocos milímetros en comparación con estos competidores, manteniéndose al mismo tiempo a velocidades adecuadas para aplicaciones en tiempo real o casi en tiempo real. Experimentos detallados muestran que cada componente principal —el modelado global mediante el Swin Transformer, las características locales multiescala de la red en forma de U y la supervisión por mapas de calor— contribuye de forma medible a la precisión final.
Qué implica esto para la interacción cotidiana
En términos sencillos, el estudio muestra que permitir que un algoritmo vea tanto la "gran imagen" de la mano completa como los pequeños detalles de cada dedo, y entrenarlo con mapas de calor que resaltan las ubicaciones probables de las articulaciones, conduce a un seguimiento 3D de la mano más fiable. Esta mayor precisión y robustez facilita la construcción de sistemas controlados por gestos que funcionen entre usuarios, condiciones de iluminación y poses complejas, ya sea para realidad virtual, tableros inteligentes de automóviles o herramientas de colaboración remota. Aunque el método aún debe extenderse a situaciones más complicadas en las que las manos interactúan estrechamente con objetos, supone un paso sólido hacia ordenadores que puedan leer nuestros movimientos de mano con la misma fluidez con la que nosotros los usamos.
Cita: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Palabras clave: estimación de pose de mano, reconocimiento de gestos, imágenes de profundidad, redes transformer, interacción humano–ordenador