Clear Sky Science · ja
スウィン・トランスフォーマーとCNNに基づく手のジェスチャー3Dポーズ推定法
機械と対話する手
手を空中で動かすだけでコンピュータや車のダッシュボード、仮想現実の世界を操作できると想像してください。それを自然に感じさせるには、たとえ手の一部が隠れていたり照明が悪くても、機械が各指関節の三次元位置を正確に把握する必要があります。本論文は深度カメラからの手のポーズをより正確に読み取る新しい手法を提示し、スムーズな非接触インタラクションを日常に近づけます。
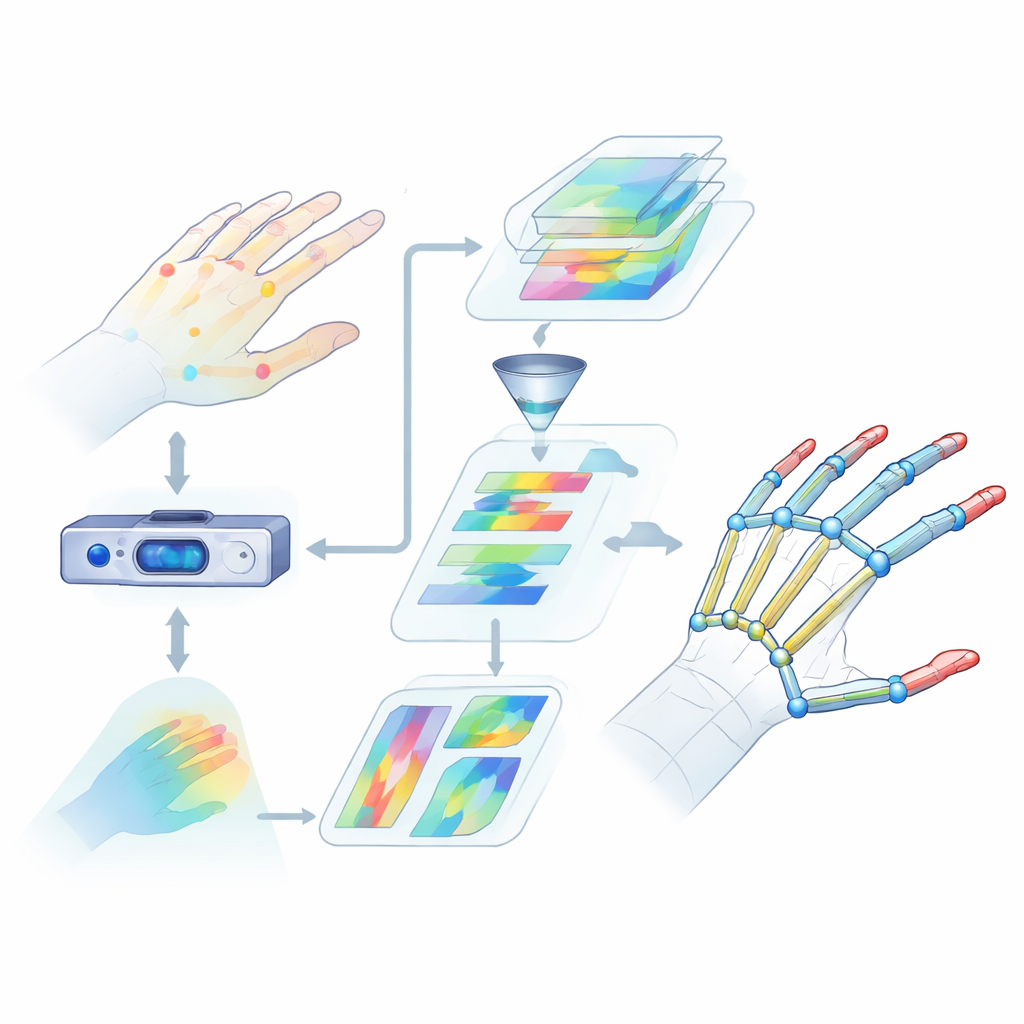
手を読むことが難しい理由
手のポーズ推定とは、カメラデータから手の主要な関節の3D位置を見つけることを指しますが、これは見た目よりずっと難しい問題です。指は曲がり、ねじれ、重なり合い、さらに人によって手の形や大きさが異なります。既存の多くの手法は限られた視覚手がかりだけを見たり、小さな領域に注目したりするため、手全体がどのように動くかを見落としがちです。また、親指と人差し指が物をつかむときのような遠く離れた関節間の関係を捉えるのも苦手です。こうした理解の欠落が、エラーの増大や仮想現実や手話認識など実世界での信頼性低下につながります。
手を二つの経路で見る新しい視点
著者らは、深度画像—各ピクセルがカメラからの距離を表す画像—を精密な3D手骨格に変換するシステムを提案します。まず、従来型の畳み込みニューラルネットワークが入力深度画像から粗い視覚特徴を抽出します。次にその情報は二つの並列ブランチに流れます。一方のブランチはU字型ネットワークを用いて複数の画像スケールで詳細を保持し、各指関節のような小さな構造を保持します。他方のブランチはスウィン・トランスフォーマーという新しいアーキテクチャを用い、画像内の離れた領域間の関係を捉えるのに優れています。両ブランチを同時に動作させて出力を融合することで、モデルは各関節の局所的な細部と手全体の構造の両方を学習します。
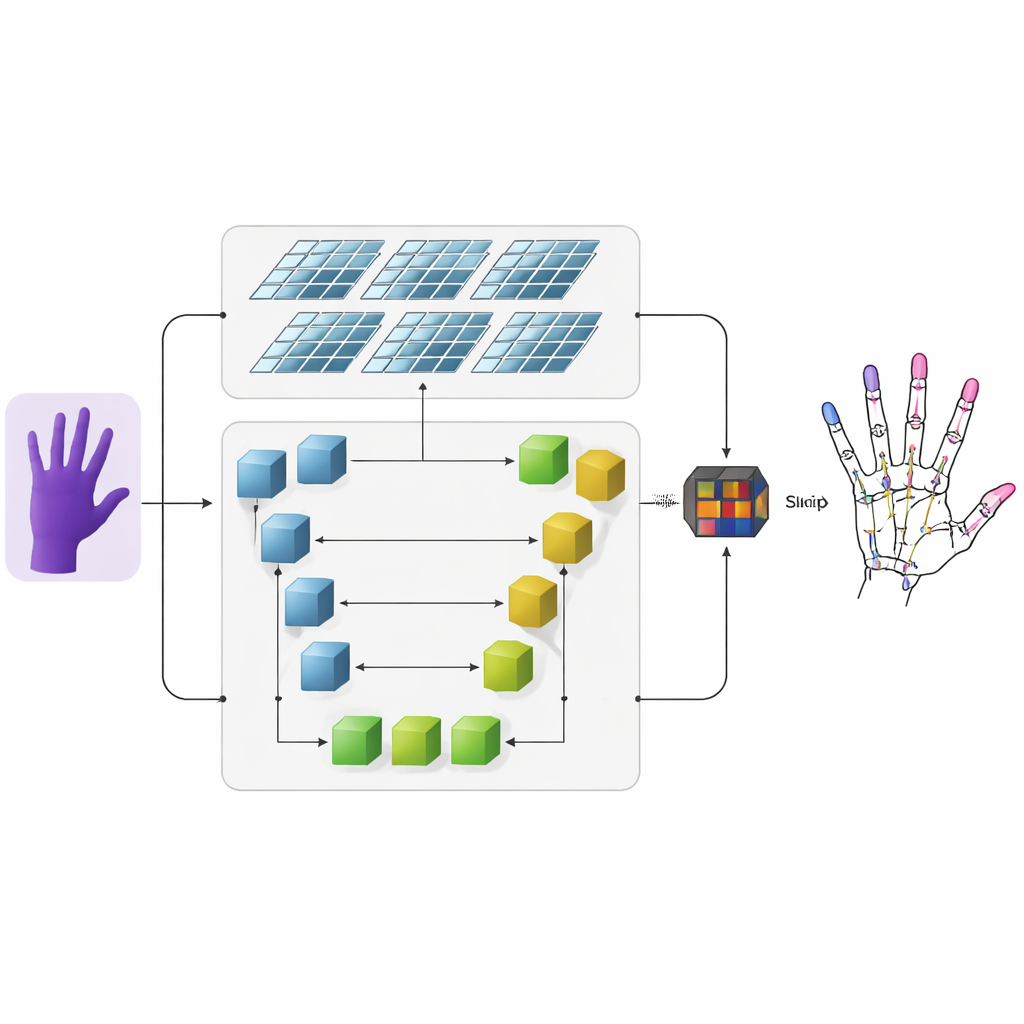
指関節を強調するヒートマップ
ネットワークに関節の出現しやすい場所を学習させるため、研究者らはヒートマップという中間表現を追加します。各関節に対して、2Dマップ上に柔らかく発光するスポットを生成し、そのピークが最もあり得る位置を示し、周辺のピクセルは徐々にフェードします。訓練中、モデルは各関節の最終的な3D座標を予測するだけでなく、これらのヒートマップにも一致させることが求められます。この二重の監督は、ネットワークに画像中の空間構造と隣接関節間の自然なつながりの両方に注意を向けさせます。また、異なる人や手のポーズに対する一般化能力を向上させます。
新たなデータと向上した精度
提案手法を評価するため、著者らはMicrosoft Research Asiaの既存のベンチマークデータセットと、LiDAR装置で取得した新しい深度画像セットを組み合わせました。独自データセットは小さく遠い手や多様なジェスチャーといった挑戦的なケースを加え、実使用シナリオをよりよく反映します。手法は複数の広く使われる手のポーズ推定システムと比較され、平均して本モデルは競合手法と比べて関節位置の誤差を数ミリメートル単位で削減し、リアルタイムあるいは準リアルタイムで動作可能な速度も維持しました。詳細な実験により、スウィン・トランスフォーマーによるグローバルなモデリング、U字ネットワークによる局所のマルチスケール特徴、ヒートマップ監督という各主要コンポーネントが最終的な精度にそれぞれ寄与していることが示されました。
日常的なインタラクションへの意味
平たく言えば、アルゴリズムに手全体の「大局」と各指の微細な「細部」の両方を見せ、関節のありそうな位置を強調するヒートマップで訓練することで、3D手運動の追跡がより信頼できるようになることを示しています。この精度と頑健性の向上により、仮想現実、スマートカーのダッシュボード、遠隔協業ツールなど、ユーザや照明条件、複雑なポーズにまたがって機能するジェスチャー制御システムを構築しやすくなります。手が物体と密接に相互作用するようなより複雑な状況へ拡張する必要は残りますが、本手法は我々の手の動きをスムーズに読み取れるコンピュータに向けた確かな一歩となります。
引用: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
キーワード: 手の姿勢推定, ジェスチャー認識, 深度イメージング, トランスフォーマーネットワーク, ヒューマン・コンピュータインタラクション