Clear Sky Science · de
3D-Handgesten-Posenschätzmethode basierend auf Swin Transformer und CNN
Hände, die mit Maschinen sprechen
Stellen Sie sich vor, Sie könnten einen Computer, ein Armaturenbrett oder eine virtuelle Realität allein durch Handbewegungen in der Luft steuern. Damit das natürlich wirkt, müssen Maschinen genau wissen, wo sich jedes Fingergelenk im dreidimensionalen Raum befindet, selbst wenn Teile der Hand verdeckt oder schlecht beleuchtet sind. Dieses Papier stellt eine neue Methode vor, mit der Computer Handposen aus Tiefenkameras genauer ablesen können und die damit berührungslose Interaktion einen Schritt näher an den Alltag bringt.
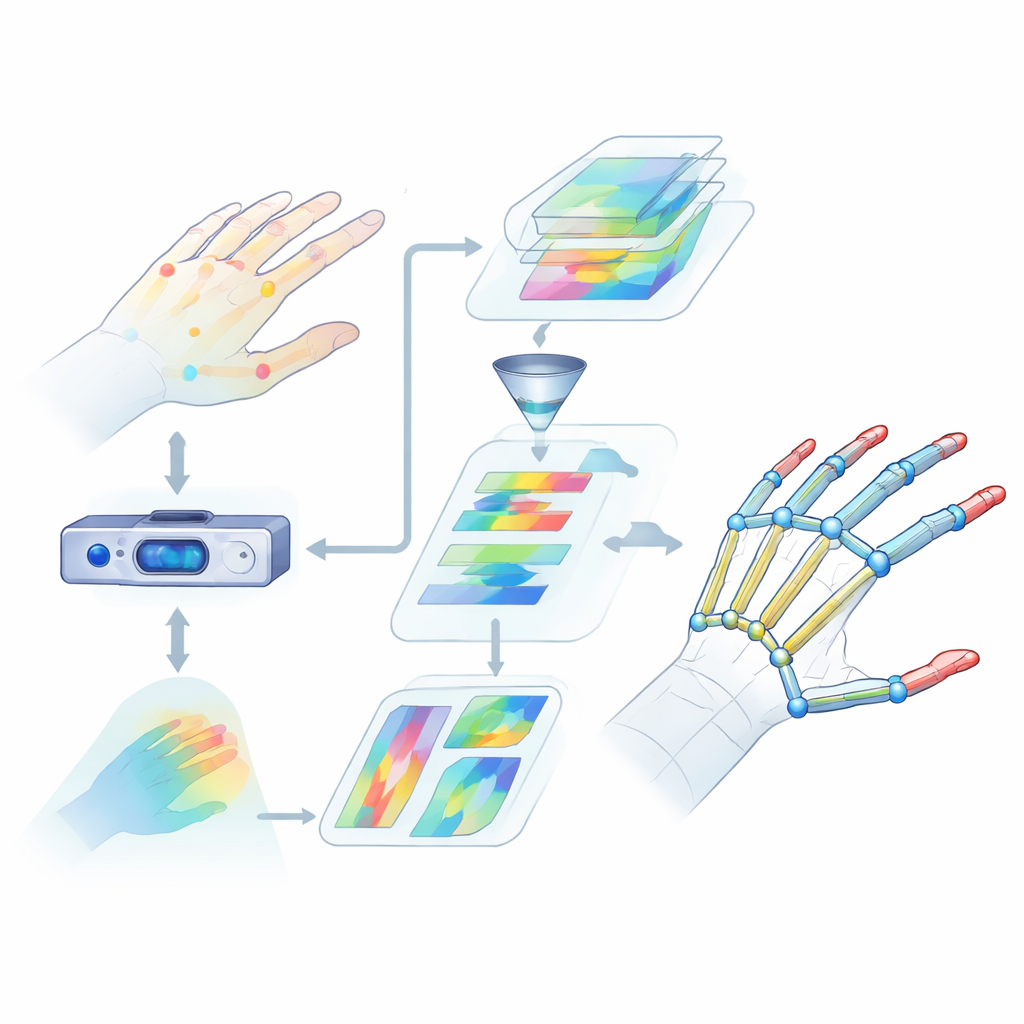
Warum Handerkennung so schwierig ist
Handposenschätzung bedeutet, die 3D-Positionen wichtiger Gelenke der Hand aus Kameradaten zu bestimmen. Das ist weitaus komplizierter, als es klingt. Finger beugen, verdrehen sich und überlappen sich, und verschiedene Personen haben unterschiedliche Handformen und -größen. Viele existierende Methoden betrachten nur begrenzte visuelle Hinweise oder fokussieren auf kleine Bereiche, sodass sie das Zusammenspiel der gesamten Hand übersehen. Sie tun sich außerdem schwer, langreichweitige Beziehungen zwischen Gelenken zu erfassen, etwa wie Daumen und Zeigefinger beim Greifen zusammenwirken. Diese Verständnislücken führen zu größeren Fehlern und unzuverlässiger Leistung in realen Anwendungen wie virtueller Realität oder Gebärdenspracherkennung.
Eine neue Zwei-Pfade-Sicht auf die Hand
Die Autoren schlagen ein System vor, das Tiefenbilder — Bilder, in denen jeder Pixel die Entfernung zur Kamera kodiert — in präzise 3D-Handskelette überführt. Zuerst extrahiert ein konventionelles Convolutional Neural Network grobe visuelle Merkmale aus dem Eingabetiefenbild. Dann fließt die Information in zwei parallele Zweige. Ein Zweig nutzt ein U-förmiges Netzwerk, um feine Details in mehreren Bildskalen zu verfolgen und kleine Strukturen wie einzelne Fingergelenke zu erhalten. Der andere Zweig verwendet eine neuere Architektur namens Swin Transformer, die besonders gut darin ist, Beziehungen zwischen weit auseinanderliegenden Bildregionen zu erfassen. Indem beide Zweige gleichzeitig betrieben und ihre Ausgaben fusioniert werden, lernt das Modell sowohl lokale Details jedes Gelenks als auch die Gesamtorganisation der Hand.
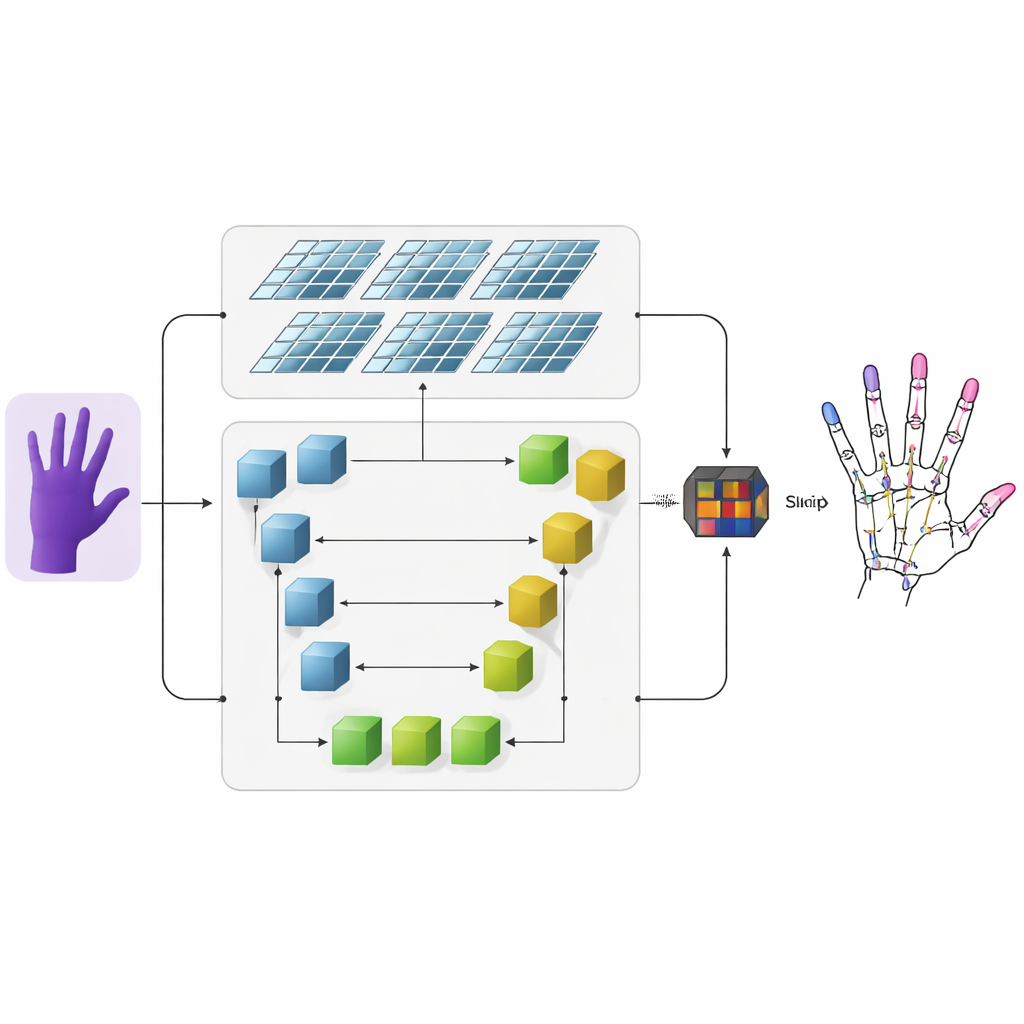
Heatmaps, die Fingergelenke hervorheben
Um dem Netzwerk beizubringen, wo Gelenke wahrscheinlich liegen, fügen die Forscher eine Zwischenrepräsentation namens Heatmap hinzu. Für jedes Gelenk erzeugen sie einen weichen, leuchtenden Fleck in einer 2D-Karte, dessen Spitze den wahrscheinlichsten Ort dieses Gelenks markiert, während benachbarte Pixel allmählich ausblenden. Während des Trainings soll das Modell nicht nur die finalen 3D-Koordinaten jedes Gelenks vorhersagen, sondern auch diese Heatmaps nachbilden. Diese doppelte Überwachung lenkt das Netzwerk auf sowohl die räumliche Struktur im Bild als auch die natürlichen Verbindungen zwischen benachbarten Gelenken. Zudem verbessert sie die Fähigkeit des Systems, über verschiedene Personen und Handhaltungen hinweg zu generalisieren.
Neue Daten und bessere Genauigkeit
Zur Bewertung ihrer Methode kombinieren die Autoren einen bekannten Benchmark-Datensatz von Microsoft Research Asia mit einem neuen Satz von Tiefenbildern, die sie mit einem LiDAR-Gerät aufgenommen haben. Ihr eigener Datensatz ergänzt schwierige Fälle, etwa kleine, entfernte Hände und variierte Gesten, um reale Nutzungsszenarien besser abzubilden. Die Methode wird mit mehreren weit verbreiteten Handposenschätzungssystemen verglichen. Im Durchschnitt reduziert das neue Modell die Fehler in den Gelenkpositionen um bis zu einige Millimeter im Vergleich zu diesen Wettbewerbern und arbeitet dabei weiterhin in Geschwindigkeiten, die für Echtzeit- oder Nahe-Echtzeitanwendungen geeignet sind. Detaillierte Experimente zeigen, dass jede Hauptkomponente — globale Modellierung durch den Swin Transformer, lokale Multiskalenmerkmale aus dem U-förmigen Netzwerk und Heatmap-Supervision — messbar zur Endgenauigkeit beiträgt.
Was das für die tägliche Interaktion bedeutet
Einfach gesagt zeigt die Studie, dass ein Algorithmus, der sowohl das „große Ganze“ der gesamten Hand als auch die feinen Details jedes Fingers sieht und der mit Heatmaps trainiert wird, die wahrscheinlichen Gelenkpositionen hervorheben, eine zuverlässigere Verfolgung der 3D-Handbewegung ermöglicht. Diese verbesserte Präzision und Robustheit erleichtert den Aufbau gestengesteuerter Systeme, die über Nutzer, Lichtverhältnisse und komplexe Posen hinweg funktionieren — sei es für virtuelle Realität, intelligente Armaturenbretter im Auto oder Werkzeuge zur Fernzusammenarbeit. Obwohl die Methode noch auf kompliziertere Situationen erweitert werden muss, in denen Hände eng mit Objekten interagieren, ist sie ein solider Schritt hin zu Computern, die unsere Handbewegungen so flüssig lesen können, wie wir sie einsetzen.
Zitation: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Schlüsselwörter: Handposenschätzung, Gestenerkennung, Tiefenbildgebung, Transformer-Netzwerke, Mensch–Computer-Interaktion