Clear Sky Science · sv
Metod för 3D-poseringsuppskattning av handgester baserad på Swin Transformer och CNN
Händer som talar med maskiner
Föreställ dig att styra en dator, en bils instrumentpanel eller en virtuell värld bara genom att röra händerna i luften. För att det ska kännas naturligt måste maskiner veta exakt var varje fingerled befinner sig i tredimensionellt utrymme, även när delar av handen är dolda eller dåligt belysta. Denna artikel presenterar ett nytt sätt för datorer att läsa av handposer från djupkameror mer exakt, vilket för oss närmare sömlös, beröringsfri interaktion i vardagen.
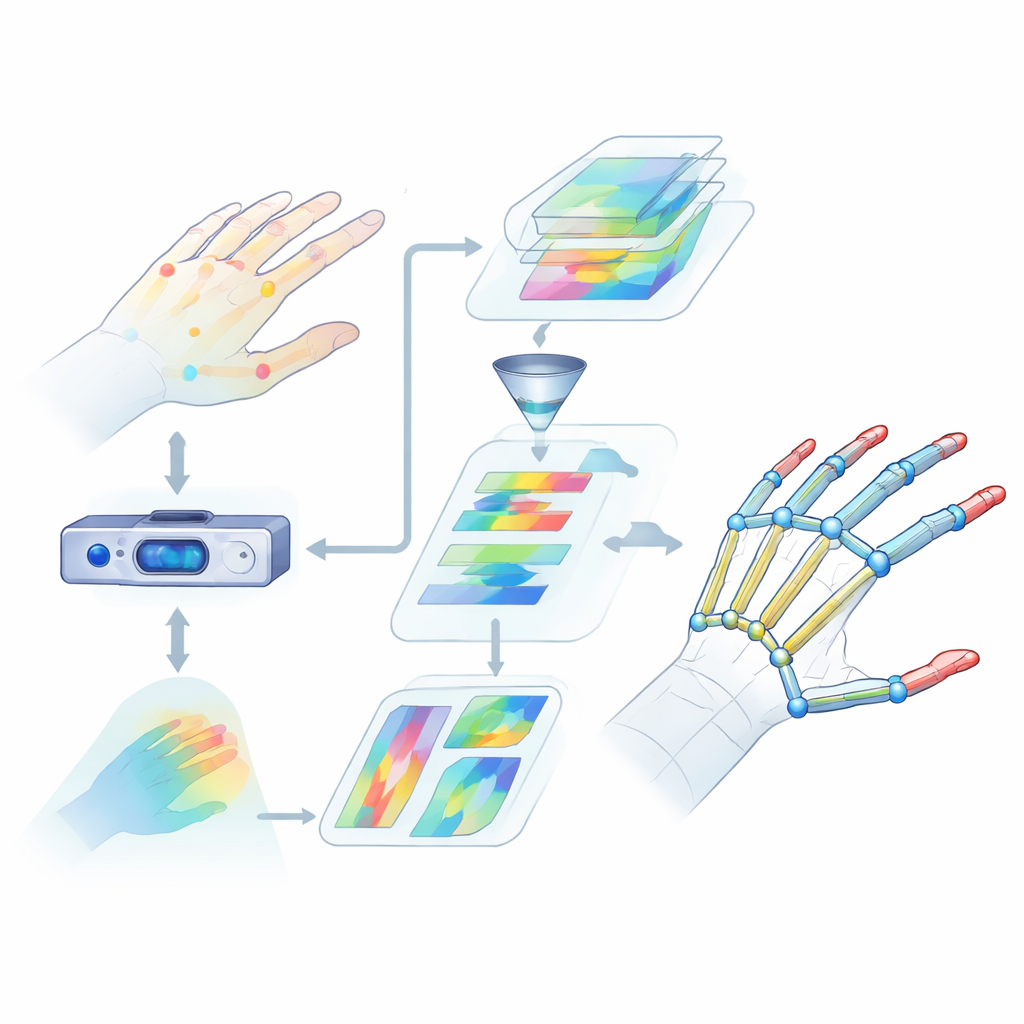
Varför det är så svårt att läsa händer
Handposeuppskattning innebär att hitta 3D-positioner för nyckelled i handen utifrån kameradata. Det är mycket svårare än det låter. Fingrar böjs, vrids och överlappar varandra, och olika människor har olika handformer och storlekar. Många befintliga metoder tittar bara på begränsade visuella ledtrådar eller fokuserar på små regioner, så de missar hur hela handen rör sig som en enhet. De har också svårt att fånga långdistansrelationer mellan leder, till exempel hur tummen och pekfingret samarbetar vid ett grepp. Dessa brister i förståelsen leder till större fel och opålitlig prestanda i verkliga situationer som virtuell verklighet eller teckenspråksigenkänning.
En ny tvåvägs syn på handen
Författarna föreslår ett system som tar djupbilder — bilder där varje pixel kodar avstånd från kameran — och omvandlar dem till precisa 3D-hand-skelett. Först extraherar ett konvolutionellt neuralt nät grova visuella egenskaper från indata. Sedan flödar informationen in i två parallella grenar. Den ena grenen använder ett U-format nätverk för att behålla fina detaljer i flera bildskalor och bevara små strukturer såsom individuella fingerleder. Den andra grenen använder en nyare arkitektur kallad Swin Transformer, som är skicklig på att fånga hur avlägsna regioner i en bild hänger ihop. Genom att köra båda grenarna parallellt och sedan slå samman deras utdata lär sig modellen både lokala detaljer för varje led och handens övergripande organisation.
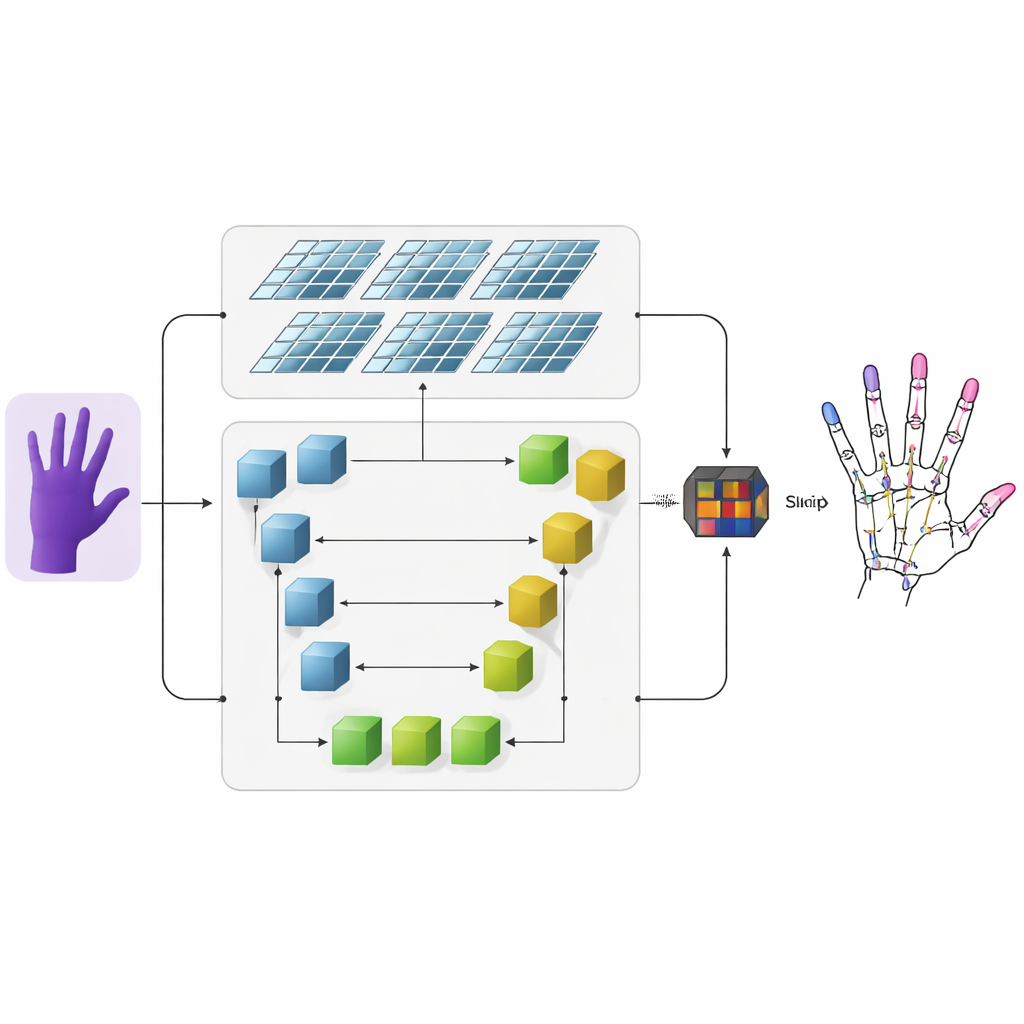
Värmekartor som framhäver fingerleder
För att hjälpa nätverket att lära sig var leder sannolikt förekommer lägger forskarna till en mellanrepresentation kallad värmekarta. För varje led genererar de en mjuk, lysande fläck i en 2D-karta där toppen markerar den mest sannolika platsen för den leden, medan närliggande pixlar tonar gradvis av. Under träningen uppmanas modellen inte bara att förutsäga slutliga 3D-koordinater för varje led, utan också att matcha dessa värmekartor. Denna dubbla styrning vägleder nätverket att uppmärksamma både den spatiala strukturen i bilden och de naturliga sambanden mellan närliggande leder. Det förbättrar också systemets förmåga att generalisera över olika personer och handposer.
Nya data och bättre noggrannhet
För att testa sitt tillvägagångssätt kombinerar författarna en välkänd benchmark-datamängd från Microsoft Research Asia med en ny uppsättning djupbilder som de fångade med en LiDAR-enhet. Deras egen datamängd tillför utmanande fall, såsom små, avlägsna händer och varierade gester, för att bättre spegla verkliga användningsscenarier. Metoden jämförs med flera vida använda system för handposeuppskattning. I genomsnitt minskar den nya modellen felet i ledpositionerna med upp till några millimeter jämfört med dessa konkurrenter, samtidigt som den fortfarande körs i hastigheter lämpliga för realtids- eller nära realtidsapplikationer. Detaljerade experiment visar att varje huvudkomponent — global modellering via Swin Transformer, lokala flerskalsfunktioner från det U-formade nätverket och värmekartsstyrning — bidrar mätbart till slutlig noggrannhet.
Vad detta betyder för vardaglig interaktion
Enkelt uttryckt visar studien att om en algoritm både får se ”helhetsbilden” av hela handen och de små detaljerna i varje finger, och tränas med värmekartor som framhäver sannolika ledpositioner, leder det till mer pålitlig spårning av 3D-handrörelser. Denna förbättrade precision och robusthet gör det enklare att bygga geststyrda system som fungerar över olika användare, ljusförhållanden och komplexa poser, oavsett om det gäller virtuell verklighet, smarta bilpaneler eller verktyg för fjärrsamarbete. Även om metoden fortfarande behöver utvidgas till mer komplicerade situationer där händer interagerar tätt med objekt, utgör den ett stabilt steg mot datorer som kan läsa våra handrörelser lika smidigt som vi använder dem.
Citering: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Nyckelord: uppskattning av handpose, gestigenkänning, djupavbildning, transformernätverk, människa–dator-interaktion