Clear Sky Science · en
Hand gesture 3D pose estimation method based on swin transformer and CNN
Hands That Talk to Machines
Imagine controlling a computer, a car dashboard, or a virtual reality world just by moving your hands in the air. For that to feel natural, machines must know exactly where every finger joint is in three-dimensional space, even when parts of the hand are hidden or poorly lit. This paper presents a new way for computers to read hand poses from depth cameras more accurately, bringing smooth, touch-free interaction a step closer to everyday reality.
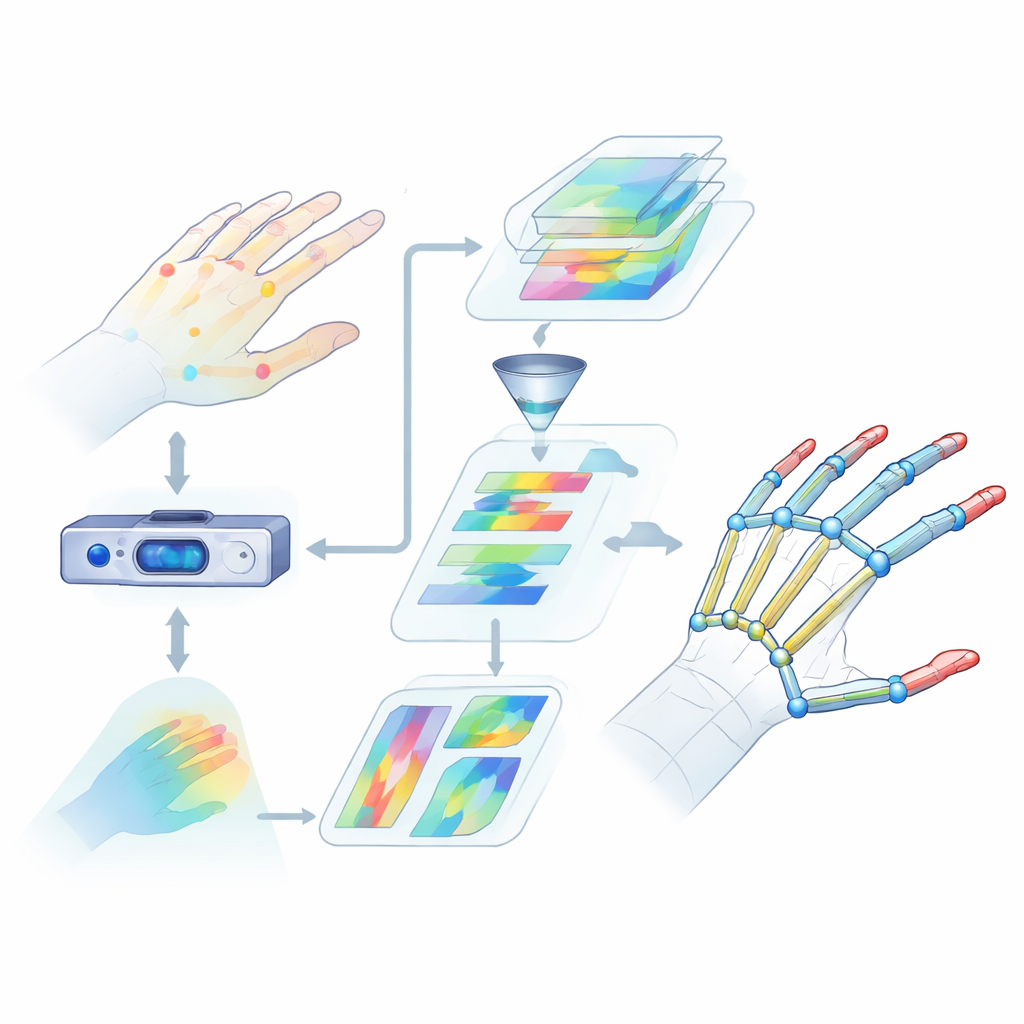
Why Reading Hands Is So Hard
Hand pose estimation means finding the 3D positions of key joints in the hand from camera data. That is much trickier than it sounds. Fingers bend, twist, and overlap, and different people have different hand shapes and sizes. Many existing methods look only at limited visual cues or focus on small regions, so they miss how the whole hand moves together. They also struggle to capture long-distance relationships between joints, such as how the thumb and index finger cooperate when grasping an object. These gaps in understanding lead to larger errors and unreliable performance in real-world situations like virtual reality or sign language recognition.
A New Two-Pathway View of the Hand
The authors propose a system that takes depth images—pictures where each pixel encodes distance from the camera—and turns them into precise 3D hand skeletons. First, a conventional convolutional neural network extracts coarse visual features from the input depth image. Then the information flows into two parallel branches. One branch uses a U-shaped network to keep track of fine details at several image scales, preserving small structures such as individual finger joints. The other branch uses a newer architecture called a Swin Transformer, which excels at capturing how distant regions in an image are related. By running both branches together and then fusing their outputs, the model learns both the local details of each joint and the overall organization of the hand.
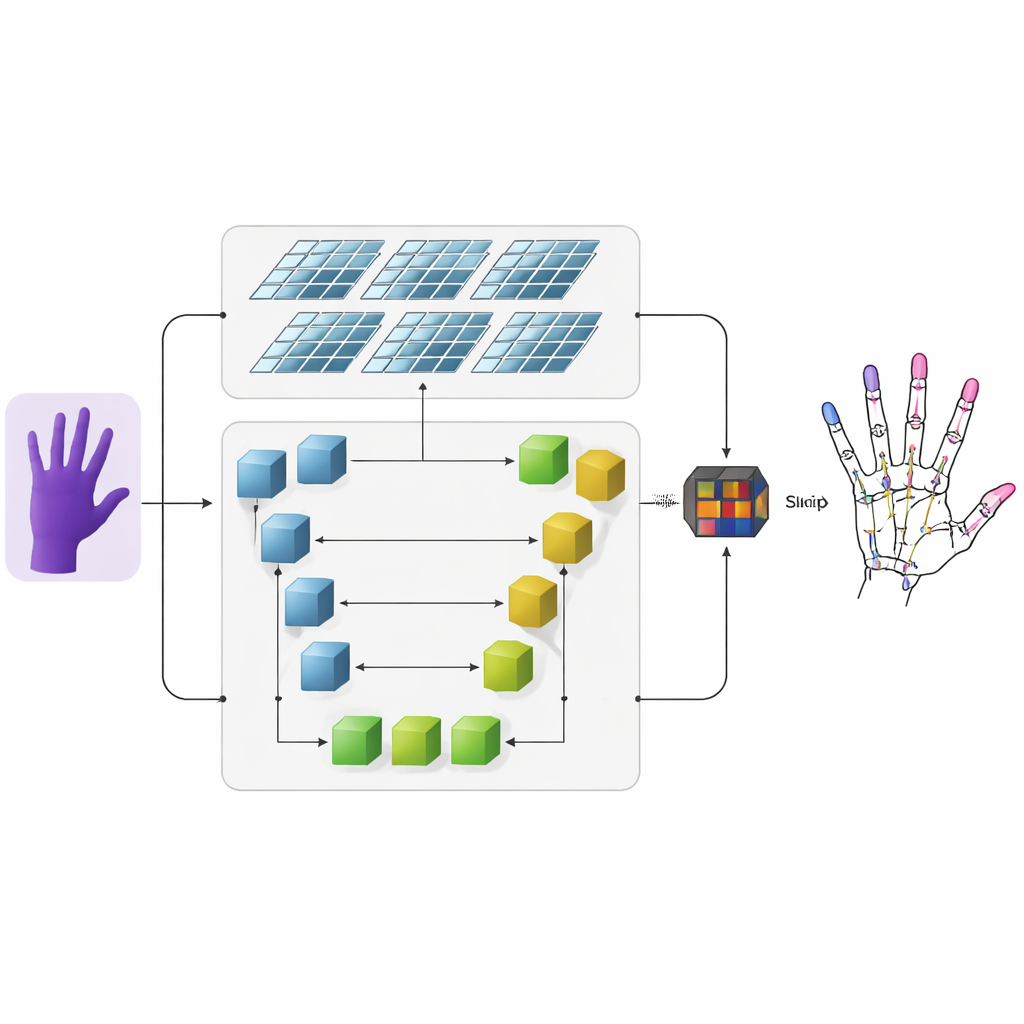
Heat Maps That Highlight Finger Joints
To help the network learn where joints are likely to appear, the researchers add an intermediate representation called a heatmap. For each joint, they generate a soft, glowing spot in a 2D map whose peak marks the most likely location of that joint, while nearby pixels fade gradually. During training, the model is asked not only to predict the final 3D coordinates of each joint, but also to match these heatmaps. This dual supervision guides the network to pay attention to both spatial structure in the image and the natural connections between neighboring joints. It also improves the system’s ability to generalize across different people and hand poses.
New Data and Better Accuracy
To test their approach, the authors combine a well-known benchmark dataset from Microsoft Research Asia with a new set of depth images they captured using a LiDAR device. Their own dataset adds challenging cases, such as small, distant hands and varied gestures, to better reflect real usage scenarios. The method is compared against several widely used hand pose estimation systems. On average, the new model reduces the error in joint positions by up to a few millimeters compared with these competitors, while still operating at speeds suitable for real-time or near-real-time applications. Detailed experiments show that each major component—global modeling by the Swin Transformer, local multi-scale features from the U-shaped network, and heatmap supervision—contributes measurably to the final accuracy.
What This Means for Everyday Interaction
In plain terms, the study shows that letting an algorithm see both the “big picture” of the whole hand and the tiny details of each finger, and training it with heatmaps that highlight likely joint locations, leads to more reliable tracking of 3D hand motion. This improved precision and robustness makes it easier to build gesture-controlled systems that work across users, lighting conditions, and complex poses, whether for virtual reality, smart car dashboards, or remote collaboration tools. While the method still needs to be extended to more complicated situations where hands interact closely with objects, it marks a solid step toward computers that can read our hand movements as smoothly as we use them.
Citation: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Keywords: hand pose estimation, gesture recognition, depth imaging, transformer networks, human–computer interaction