Clear Sky Science · pt
Método de estimativa de pose 3D de gestos manuais baseado em Swin Transformer e CNN
Mãos que Conversam com Máquinas
Imagine controlar um computador, o painel de um carro ou um mundo de realidade virtual apenas movendo as mãos no ar. Para que isso pareça natural, as máquinas precisam saber exatamente onde está cada articulação dos dedos no espaço tridimensional, mesmo quando partes da mão estão ocultas ou mal iluminadas. Este artigo apresenta uma nova maneira de os computadores lerem poses das mãos a partir de câmeras de profundidade com maior precisão, aproximando a interação sem toque e fluida de uma realidade cotidiana.
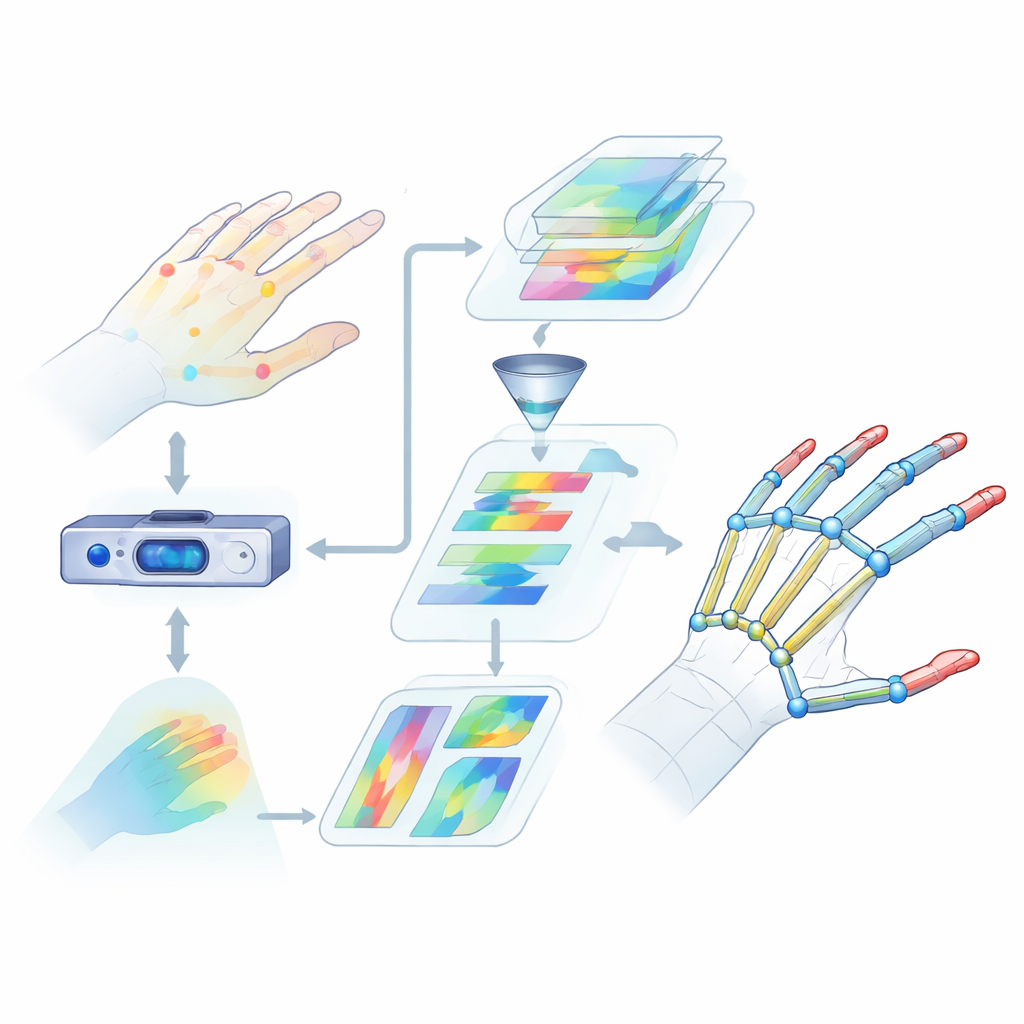
Por que Ler as Mãos é Tão Difícil
Estimativa de pose da mão significa encontrar as posições 3D de articulações-chave da mão a partir de dados de câmera. Isso é bem mais complicado do que parece. Os dedos se dobram, giram e se sobrepõem, e pessoas diferentes têm formatos e tamanhos de mão distintos. Muitos métodos existentes consideram apenas pistas visuais limitadas ou focam em pequenas regiões, deixando de capturar como a mão inteira se move em conjunto. Eles também têm dificuldade em captar relações à longa distância entre articulações, como a cooperação entre o polegar e o indicador ao segurar um objeto. Essas lacunas de entendimento resultam em erros maiores e desempenho pouco confiável em situações reais, como realidade virtual ou reconhecimento de linguagem de sinais.
Uma Nova Visão em Duas Vias da Mão
Os autores propõem um sistema que toma imagens de profundidade — fotos onde cada pixel codifica a distância à câmera — e as transforma em esqueletos 3D precisos da mão. Primeiro, uma rede neural convolucional convencional extrai características visuais grosseiras da imagem de profundidade de entrada. Em seguida, a informação flui por duas ramificações paralelas. Uma ramificação usa uma rede em formato de U para acompanhar detalhes finos em várias escalas da imagem, preservando estruturas pequenas como articulações individuais dos dedos. A outra ramificação usa uma arquitetura mais recente chamada Swin Transformer, que se destaca em capturar como regiões distantes de uma imagem se relacionam. Ao executar ambas as ramificações em conjunto e depois fundir suas saídas, o modelo aprende tanto os detalhes locais de cada articulação quanto a organização global da mão.
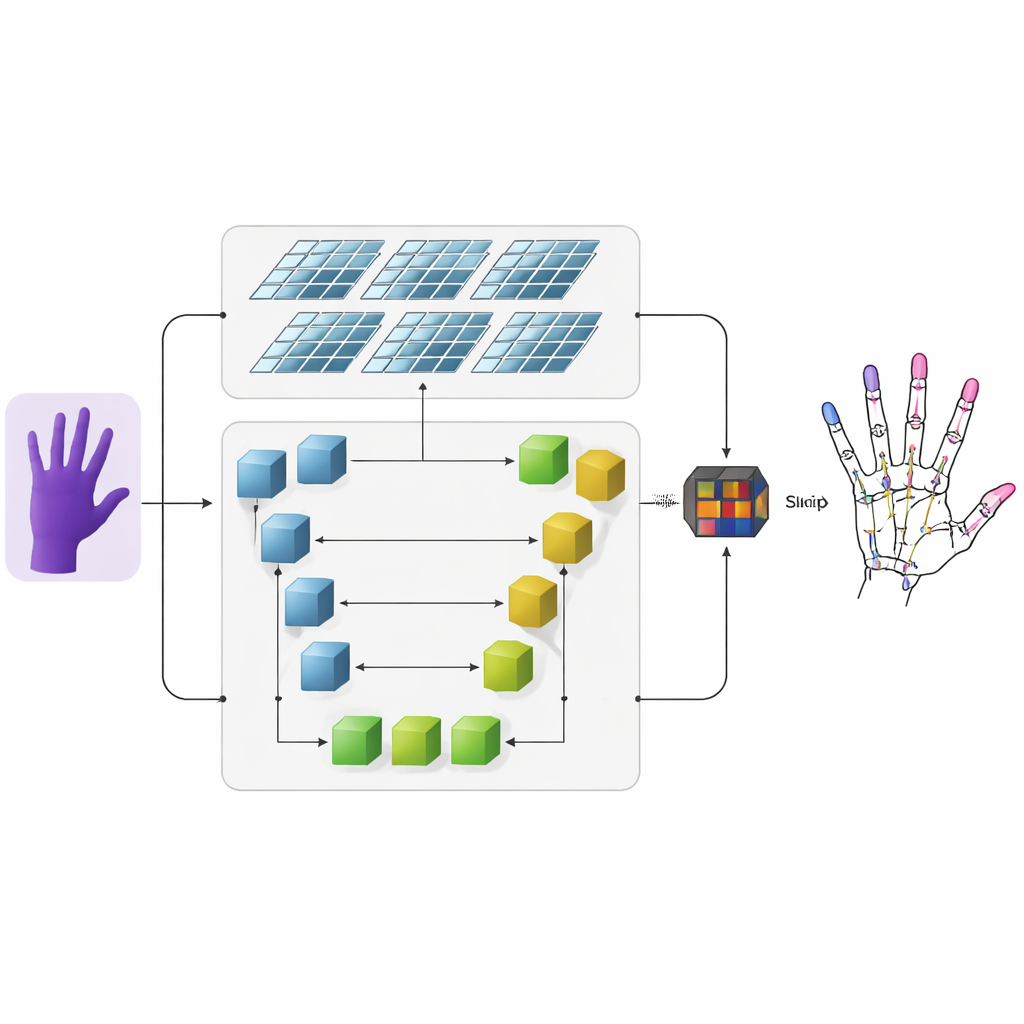
Mapas de Calor que Destacam as Articulações dos Dedos
Para ajudar a rede a aprender onde as articulações provavelmente aparecem, os pesquisadores adicionam uma representação intermediária chamada mapa de calor. Para cada articulação, eles geram uma mancha suave e luminosa em um mapa 2D cujo pico marca a localização mais provável daquela articulação, enquanto pixels próximos desaparecem gradualmente. Durante o treinamento, o modelo é solicitado não apenas a prever as coordenadas 3D finais de cada articulação, mas também a corresponder a esses mapas de calor. Essa supervisão dupla guia a rede a prestar atenção tanto à estrutura espacial na imagem quanto às conexões naturais entre articulações vizinhas. Também melhora a capacidade do sistema de generalizar entre diferentes pessoas e poses de mão.
Novos Dados e Maior Precisão
Para testar sua abordagem, os autores combinam um conjunto de referência bem conhecido do Microsoft Research Asia com um novo conjunto de imagens de profundidade que capturaram usando um dispositivo LiDAR. Seu próprio conjunto adiciona casos desafiadores, como mãos pequenas e distantes e gestos variados, para refletir melhor cenários de uso reais. O método é comparado a vários sistemas de estimativa de pose da mão amplamente usados. Em média, o novo modelo reduz o erro nas posições das articulações em poucos milímetros em comparação com esses concorrentes, mantendo velocidades adequadas para aplicações em tempo real ou quase em tempo real. Experimentos detalhados mostram que cada componente principal — modelagem global pelo Swin Transformer, características locais multiescala da rede em U e supervisão por mapas de calor — contribui de forma mensurável para a precisão final.
O Que Isso Significa para a Interação Cotidiana
Em palavras simples, o estudo mostra que permitir que um algoritmo veja tanto a “visão ampla” da mão inteira quanto os detalhes minúsculos de cada dedo, e treiná-lo com mapas de calor que destacam locais prováveis de articulação, resulta em rastreamento 3D das mãos mais confiável. Essa precisão e robustez aprimoradas tornam mais fácil construir sistemas controlados por gestos que funcionem entre diferentes usuários, condições de iluminação e poses complexas, seja para realidade virtual, painéis inteligentes de carros ou ferramentas de colaboração remota. Embora o método ainda precise ser estendido para situações mais complexas em que as mãos interagem de perto com objetos, ele marca um passo sólido rumo a computadores que consigam ler nossos movimentos manuais tão suavemente quanto os usamos.
Citação: Dang, R., Feng, G. Hand gesture 3D pose estimation method based on swin transformer and CNN. Sci Rep 16, 11551 (2026). https://doi.org/10.1038/s41598-026-41974-6
Palavras-chave: estimativa de pose da mão, reconhecimento de gestos, imagens de profundidade, redes transformer, interação humano–computador