Clear Sky Science · zh
受大脑启发的感知-决策机器用于假语音检测
为什么假声音是全社会的问题
利用现代人工智能工具生成听起来与真人几乎无异的语音变得令人担忧地容易。这些令人信服的假声音威胁着从电话银行和智能音箱到在线视频会议与新闻报道等各种场景。此处描述的研究着眼于一个关键问题:即使在伪造工具不断变化和改进的情况下,我们如何可靠地区分人类语音和合成语音?
一种新的“倾听”风险的方法
大多数现有系统将假语音检测视为简单的二分类任务。它们从大量示例中学习,并试图在真实音频与伪造音频之间画出一条边界。这在训练时见过的伪造类型上通常效果不错,但当出现新的攻击方法时性能会下降。作者认为这种思路是错误的。与其强行让一个单一模型做出全有或全无的决定,不如模仿人类专家乃至大脑处理复杂感官信息的方式:寻找许多小而明显的线索,然后基于这些证据进行推理。
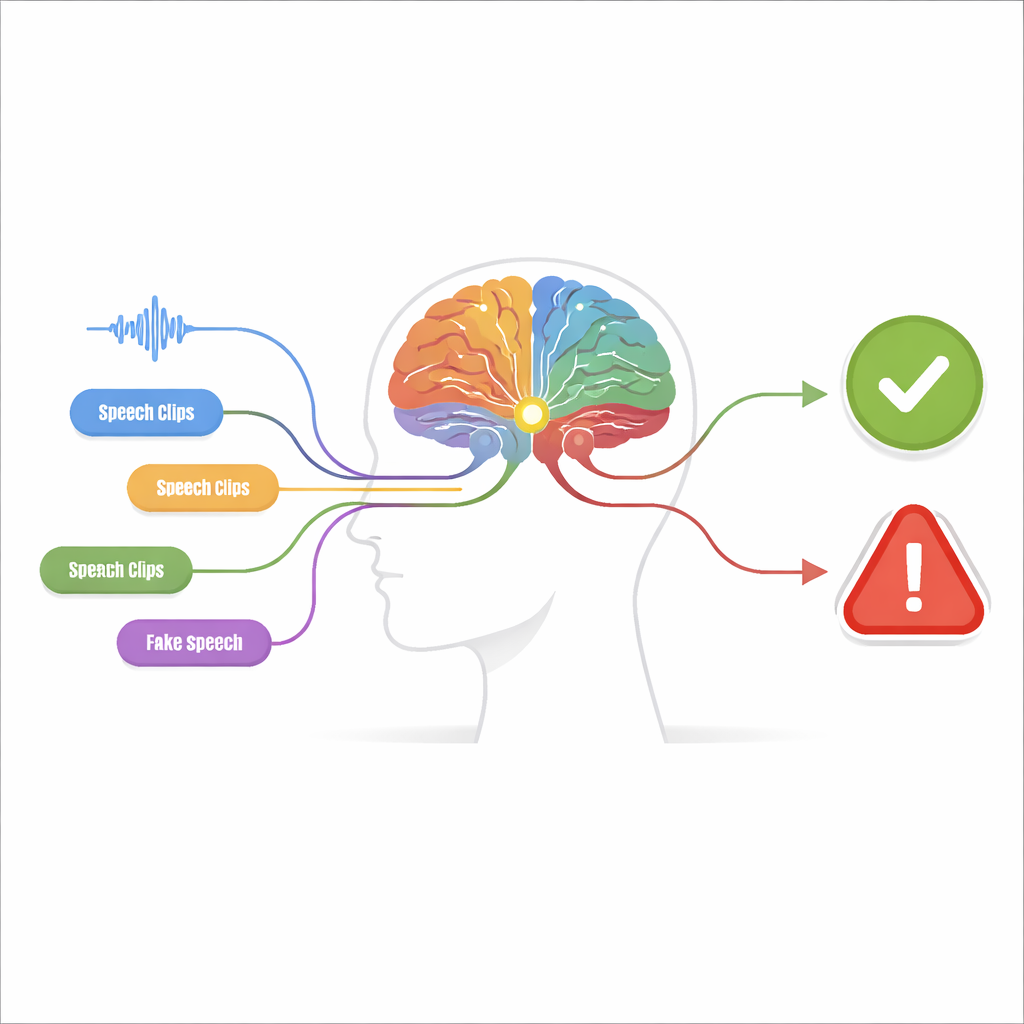
许多小线索,而不是一个大猜测
所提出的系统称为感知-决策机器,由两个阶段构成。在感知阶段,音频由多个独立的检测器检查,每个检测器针对一种特定的“伪造线索”进行调优。有的检测器关注原始波形,搜索突变和不自然的过度平滑模式;有的检查频率内容,伪造声音可能在谐波上表现为模糊或产生异常形状的共振;还有的检测时间和频率的联合演变,捕捉某些声音发生时机与存在音色之间的不匹配。最后一组则分析音素级别的细节——构成词语的微小声音单元,伪造语音往往缺乏真实说话者那种微妙、流动的发音特征。
从线索模式到明确决策
每个检测器的设计都极为谨慎:只有在几乎确定的情况下才发出“发现线索”的信号,优先保证精确性而不是尽可能多地捕捉每一个伪造。其输出被简化为二值信号,就像灯开或关一样。这些开关信号随后被送入决策模块。在这里,若干线索通过决策树进行组合——决策树是一种由若干若干条件链组成的 if–then 规则结构,类似人们处理证据时的推理方式。一个特殊的逻辑步骤,类似“其中任何一个即可”的规则,将多个决策树联系在一起。这种分层推理不仅提升了准确率,还增强了系统的可解释性:可以精确追溯导致“伪造”判定的具体线索。
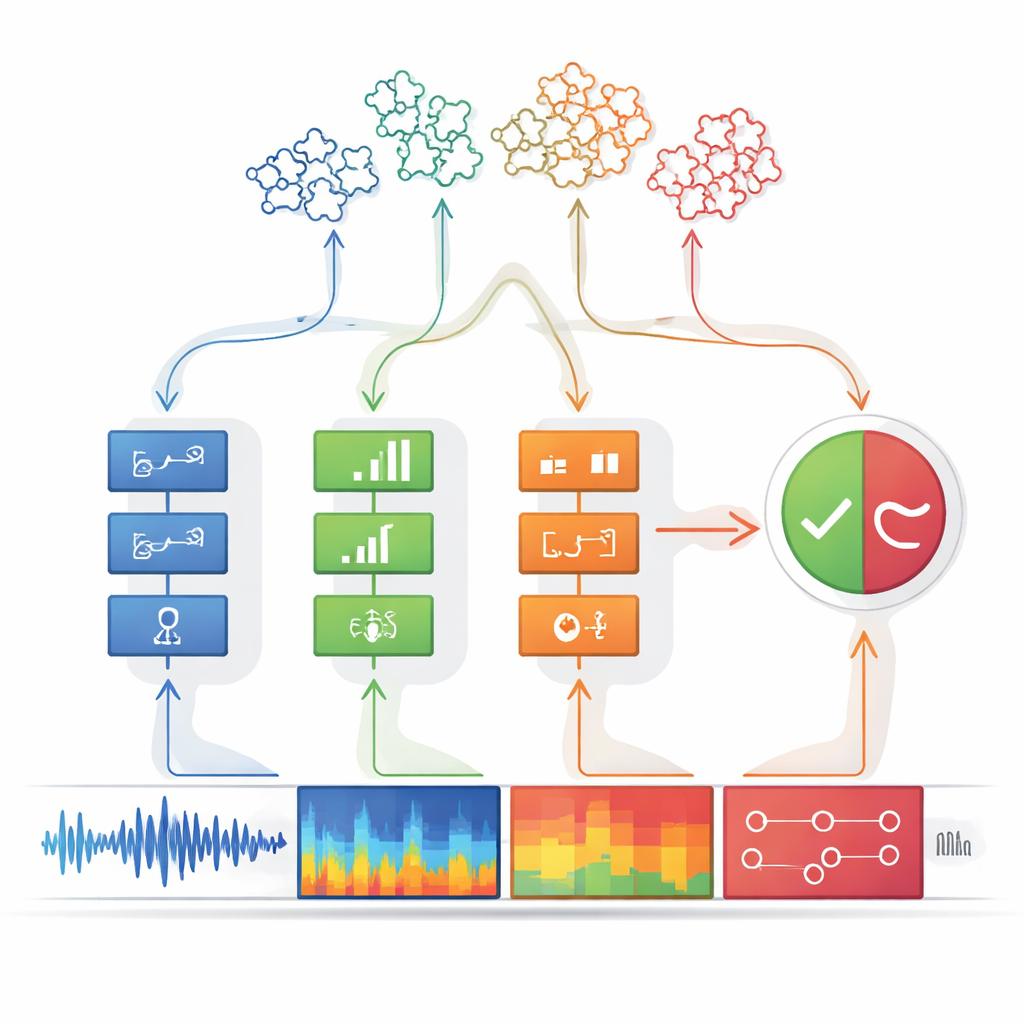
领先应对新型伪造
该设计的一大优势是可以在不重头开始的情况下扩展。当出现新型伪造语音时,工程师可以为其独特的伪迹创建并训练一个额外的检测器,然后将其插入感知模块。由于决策阶段接受灵活的线索输入列表,新检测器的输出可以在不重训整个系统的情况下并入。在对广泛使用的反欺骗基准测试中,感知-决策机器在熟悉的攻击上匹配或超过了强大的深度学习基线,并在此前未见的攻击上明显优于它们。它还通过简单地添加检测器适应了新的中文数据集,而竞争系统则需要完全重训,并且出现了对早期攻击“遗忘”的问题。
这对日常语音安全意味着什么
对非专业人士而言,结论是:假语音检测不必是一个神秘的黑箱。通过将问题拆分为许多可理解的小线索并用明确的逻辑规则将它们组合起来,作者构建了一个既高度准确又可解释的系统。正如我们的脑子在做出判断前依赖多重感官提示,这台机器收集并推理多样的伪造迹象。结果是一个更能抵御不断变化的音频深度伪造的稳健防护系统——它能随时间增长,帮助让基于语音的服务和通信对所有人更安全。
引用: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
关键词: 音频深度伪造, 假语音检测, 受大脑启发的人工智能, 语音安全, 增量学习